

IKAnalyzer 中文分词器
V3.X 使用手册
目录
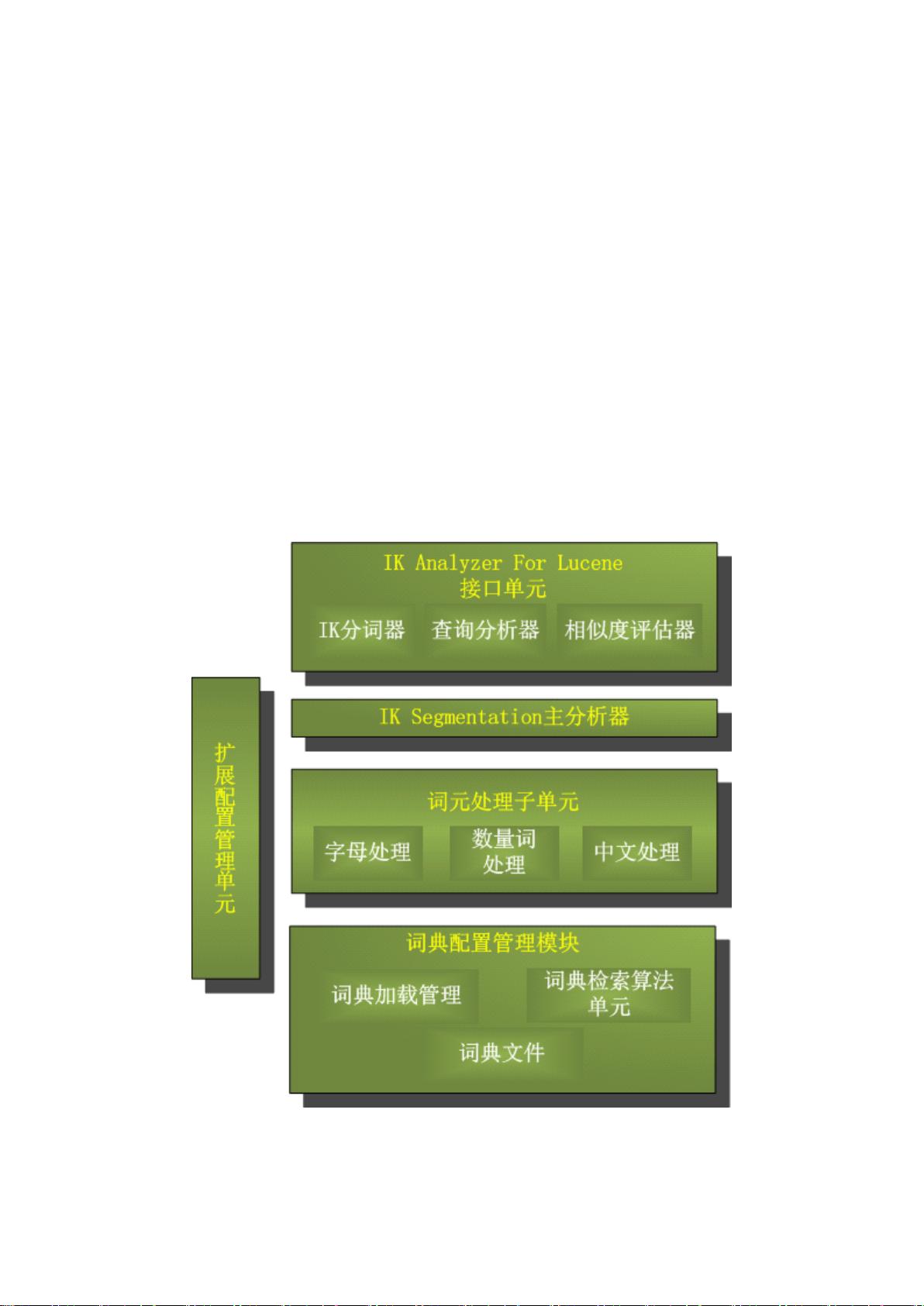
1.IK Analyzer 3.0 介绍 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2. 使用指南 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3. 词表扩展 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4 针对 solr 的分词器应用扩展 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5. 关于作者 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14

剩余14页未读,继续阅读
资源评论


aukulin
- 粉丝: 0
- 资源: 2









最新资源
- 自适应巡航控制器,ACC设计,以车辆速度误差,车间距误差为输入量通过mpc控制器进行自适应巡航,采用S函数代码编写,以实现车间距保持与速度跟随,matlab与carsim联合仿真,控制量为轮胎转矩,可
- 西门子plc1500控制的智能物流分拣系统 博图触摸屏仿真 不需要实物 自带人机界面,动画,可以仿真 还有接线图原理图 1.设计说明1500 2.程序博图v16 3.cad图纸,说明b78
- 光伏同步发电机并网simulink仿真模型 光伏采用最大功率点跟踪,拓扑为Boost电路 右侧逆变器为VSG控制策略 2018b以上的版本
- 维也纳整流器(Vienna recttifier)闭环仿真模型,Svpwm调制 matlab, simulink
- 基于同步发电机(vsg)分布式能源并网仿真 并网逆变器,有功频率控制,无功电压控制,VSG控制,电压电流双环PI控制 各方面波形都完美 模型一次调频,也可以模拟一次调压 MATLAB201
- 基于TTC(或车辆安全距离,车头时距)触发的车辆道轨迹规划与控制,采用五次多项式实时规划,ttc触发车辆道决策,matlab与carsim联合仿真实验,控制量为节气门开度,制动压力和方向盘转角,模型仅
- 考虑光伏出力利用率的电动汽车充电站能量调度策略 仿真软件:matlab + cvx 注意事项:程序注释详细,提供cvx求解器安装包和安装方法 代码内容: 针对间歇性能源利用的问题,构建电动汽车的充放
- 纯电动汽车整车Matlab simulink仿真模型(电机模型、电池模型、变速器模型、驾驶员模型、整车动力学模型) -整车总成参数都有,可直接运行仿真
- 基于多智能体系统一致性算法的电力系统分布式经济调度策略-谢俊lunwen的复现 包括10个发电单元和19个柔性负荷单元 能完美的实现复现
- 光伏三相并网仿真 模型内容: 1.光伏+MPPT控制+两级式并网逆变器(boost+三相桥式逆变) 2.坐标变+锁相环+dq功率控制+解耦控制+电流内环电压外环控制+spwm调制 3.LCL滤波 仿真
- 车辆状态估计模型EKF AEKF,基于Carsim和simulink联合仿真51 在建立车辆三自由度模型(自行车模型加纵向)的基础上, 分别使用EKF和AEKF算法 对纵向车速, 横摆角速度,
- ansoft ansys Maxwell 有限元仿真 电磁场模型 主要为无线电能传输WPT 磁耦合谐振 多相多绕组变压器 高频非正弦周期激励变压器等模型 永磁同步电机(pmsm) 永磁游标电机(pm
- 纯电动汽车Simulink仿真模型建模详细步骤 通过文档的形式,跟着文档一步一步操作,既可以提高自己的建模能力,又可以对整个建模思路进行借鉴,形成设计能力 附带模型
- 纯电动汽车动力经济性仿真,Cruise和Simulink联合仿真,提供Cruise整车模型和simuink策略模型,2015版本可用 策略主要为BMS、再生制动和电机驱动策略,内含注释模型和详细解析文
- comsol枝晶生长,沉积模型,包括:典型,形状成核,随机成核,均匀沉积,雪花晶形成过程 适用于电池,电化学沉积,催化的模拟学习
- 双电机纯电动汽车整车仿真模型,基于Matlab Simulink的双电机前后轴双驱电动汽车仿真模型 双电机纯电动汽车整车控制策略,新能源电动汽车整车仿真模型 -包括前轴电机、后轴电机双电机模型转矩
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


