
FPGA 异构计算现状及优化
基于 FPGA 的通用 CNN 加速设计,可以大大缩短 FPGA 开发周期,支持
业务深度学习算法快速迭代;提供与 GPU 相媲美的计算性能,但拥有相较
于 GPU 数量级的延时优势,为业务构建最强劲的实时 AI 服务能力。
WHEN?深度学习异构计算现状
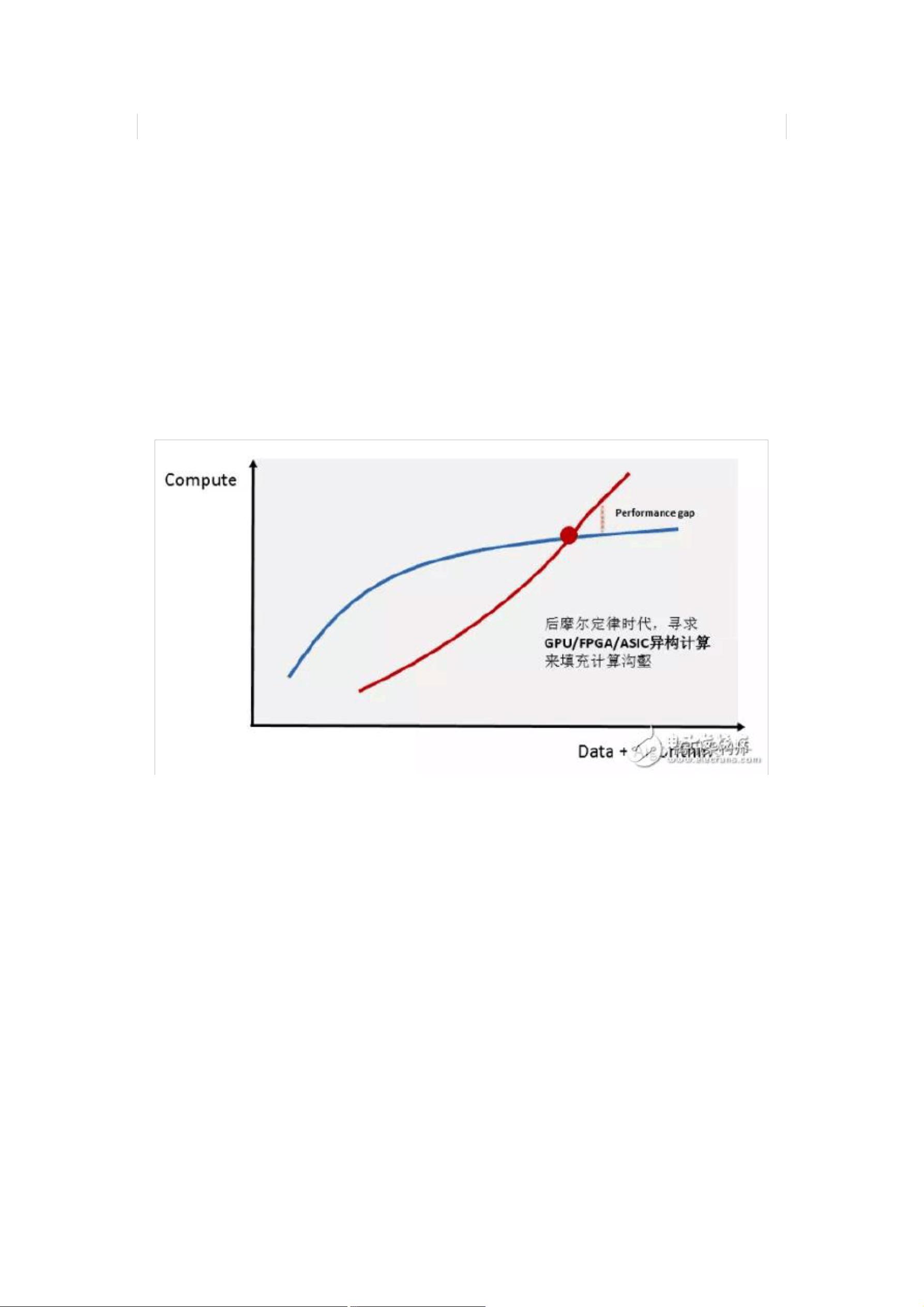
随着互联网用户的快速增长,数据体量的急剧膨胀,数据中心对计算
的需求也在迅猛上涨。同时,人工智能、高性能数据分析和金融分析等计
算密集型领域的兴起,对计算能力的需求已远远超出了传统 CPU 处理器的
能力所及。
异构计算被认为是现阶段解决此计算沟壑的关键技术,目前
“CPU+GPU ”以及“ CPU+FPGA ” 是最受业界关注的异构计算平台。它们具
有比传统 CPU 并行计算更高效率和更低延迟的计算性能优势。面对如此巨
大的市场,科技行业大量企业投入了大量的资金和人力,异构编程的开发
标准也在逐渐成熟,而主流的云服务商更是在积极布局。

剩余15页未读,继续阅读
资源评论


apple_51426592
- 粉丝: 9840
- 资源: 9652









最新资源
- Java+JSP+Mysql实现Web学生成绩管理系统源码(高分项目)
- 三相LCL型并网逆变器 MATLAB 内含:SPWM模块,LCL滤波结构,有源阻尼电容电流比例反馈模块,PI控制器模型 采用dq轴电流矢量控制 模型图、电网电压和并网电流波形图如下 适用matla
- 基于spring的留学信息推荐系统的设计与实现源码(java毕业设计完整源码).zip
- 机械设计在线式PCBA点胶机sw18可编辑全套设计资料100%好用.zip
- 基于SSH框架的教师管理课程教学系统设计与实现
- (176594622)数据库课程设计065ssm体育器材租借管理系统hsg4912AHA5程序.sql
- (176961994)java学生学籍管理系统(源代码+论文+开题报告+外文翻译+答辩PPT)
- 基于web的金融交易平台设计与实现.doc
- 四旋翼PID控制仿真模型 matlab仿真程序,支持姿态单独控制,阶跃信号,方波,正弦波直接输入姿态环,波形完美,可以选择接入位置环,定点控制,轨迹跟踪,一键切轨迹等功能 带公式推导文档
- (177034626)基于ASP网络办公OA系统设计(论文+源代码+开题报告+答辩PPT).rar
- 基于Vue+SpringBoot的考研学习分享平台设计与实现源码(java毕业设计完整源码+LW).zip
- (177365632)多目标粒子群优化算法(MOPSO)【含Matlab源码 033期】.zip
- 程序清理和卸载工具 App Cleaner & Uninstaller for Mac v8.2.3
- 卸载和清理工具 App Cleaner for Mac v8.4.2
- 基于web的快递员物流管理系统论文.doc
- 系统维护工具 CleanMyMac X for Mac v4.15.2
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


