计算机科学与技术学院 大数据管理与分析 课程实验报告
实验题目:数据分析系统的设计与实现
基于关联规则挖掘的图书推荐
学号:
日期:2020.6.4
班级:2017 级计算机 4 班
姓名:
Email:623581439@qq.com
实验目的:
随着 Hadoop 与 Spark 产生的影响越来越深,各种基于 Hadoop 与 Spark 平台的数据分析系统也随之出现。本次实验要求各位同学利用之前实验以及所学知识
实现一个基于 Hadoop、Spark 或其他大数据平台的数据分析系统,理解其中的实现细节以及各种算法的原理。
实验软件和硬件环境:
1)操作系统:Linux(实验室版本为 Ubuntu17.04,集群环境为 centos6.5);
2)Hadoop 版本:2.9.0;
3)JDK 版本:1.8;
4)Java IDE:Eclipse 3.8。
5)Spark 版本:实验室版本为 2.1.0,集群环境为 2.3.0;
6)Maven
实验要求:
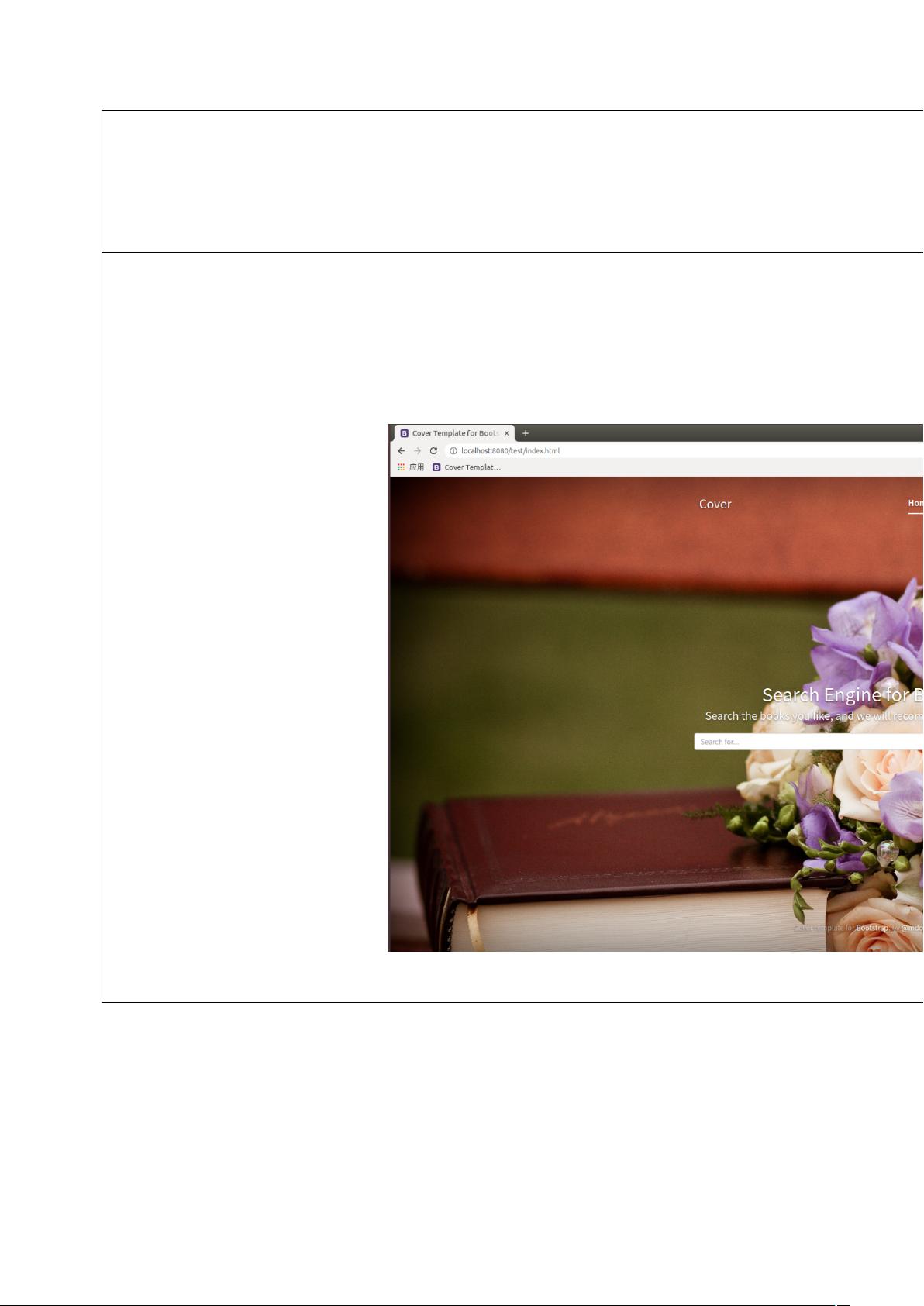
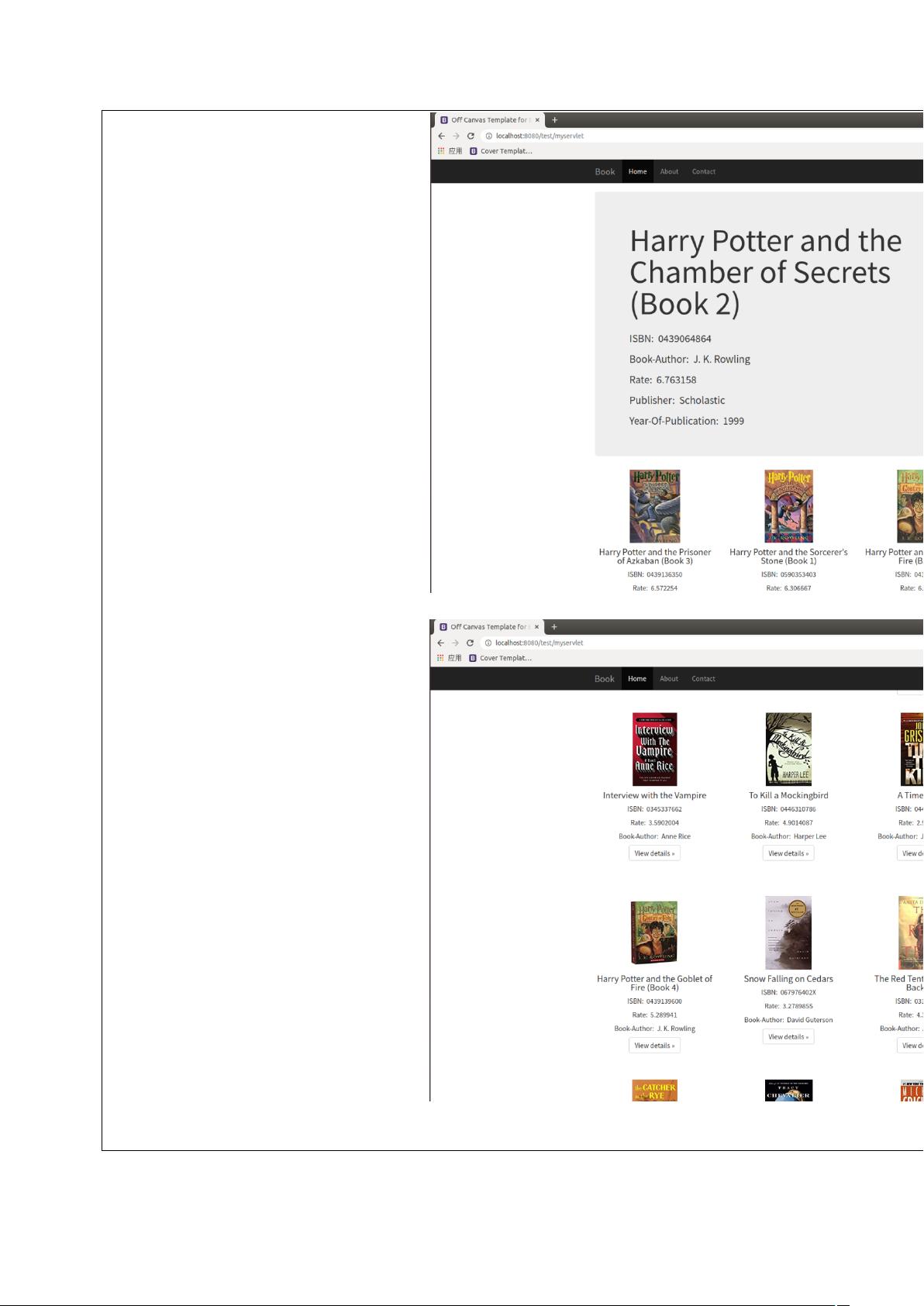
基本要求:实现的数据分析系统要有对数据分析结果以及各种功能的图形化、图表化展示界面。
高级要求:在数据分析系统中应用算法解决一些实际问题,例如采用某个推荐系统算法实现产品推荐,或某个挖掘算法产生数据的深度分析结果,算法都是基于大数据系统的并行化算
法。
实验主题:基于关联规则挖掘的图书推荐
在我国的图书出版和发行行业,经过多年的发展,图书市场在种类规模和总体数量等方面发展和增长迅速。但与此同时也带来了图书过多、读者难以选择的问题。常规的明细分类
使得读者可以针对每- - 种类型的图书进行选择,但是每个分类下依然有成千上万种书籍。因此,基于读者的用户评论分析来进行图书推荐是一个具有实际应用价值的研究。
基于 Apriori 关联规则挖掘算法进行图书推荐的应用算法设计和实现,将利用大量图书评论数据,使用 MapReduce 并行化处理技术来完成图书的 k-频繁项集挖掘和图书推荐置信度
的计算,在此基础上完成图书的推荐应用,并整合图书评分统计系统。
实验原理:
频繁项集挖掘
关联规则用来描述事物之间的联系,用来挖掘事物之间的相关性。挖掘关联规则的核心是通过统计数据项获得频繁项集。
设 I={i,i, .,im} 是项的集合,设任务相关的数据 D 是数据库事务的集合,其中每个事务 T 是项的集合,每一个事务有一个标志符,称作 TID。设 A 和 B 是两个项集,A、B 均为 I 的非
空子集。关联规则是形如 A->B 的蕴涵式,并且 A∩B=φ。关联规则挖掘涉及到以下几个关键概念。
1) 置信度/可信度( Confidence)。 置信度即是“值得信赖性”。设 A, B 是项集,对于事务集 D, A∈D, B∈D, A∩B=φ,A->B 的置信度定义为:置信度(A->B)=包含 A 和 B 的元组数/包含 A
的元组数。
Confidence(A->B) = P(B|A) = P(AB)/P(A)
2) 支持度(Support)。 支持度(A->B) =包含 A 和 B 的元组数/元组总数。支持度描述了 A 和 B 这两个项集在所有事务中同时出现的概率。