
馃摎 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 馃殌. UPDATED 29 September 2021.
- [About Weights & Biases](#about-weights-&-biases)
- [First-Time Setup](#first-time-setup)
- [Viewing runs](#viewing-runs)
- [Disabling wandb](#disabling-wandb)
- [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
- [Reports: Share your work with the world!](#reports)
## About Weights & Biases
Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models 鈥� architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
- [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
- [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
- [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
- [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
- [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
- [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
## First-Time Setup
<details open>
<summary> Toggle Details </summary>
When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device.
W&B will create a cloud **project** (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run **name** within that project as project/name. You can also manually set your project and run name as:
```shell
$ python train.py --project ... --name ...
```
YOLOv5 notebook example: <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
<img width="960" alt="Screen Shot 2021-09-29 at 10 23 13 PM" src="https://user-images.githubusercontent.com/26833433/135392431-1ab7920a-c49d-450a-b0b0-0c86ec86100e.png">
</details>
## Viewing Runs
<details open>
<summary> Toggle Details </summary>
Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in <b>realtime</b> . All important information is logged:
- Training & Validation losses
- Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95
- Learning Rate over time
- A bounding box debugging panel, showing the training progress over time
- GPU: Type, **GPU Utilization**, power, temperature, **CUDA memory usage**
- System: Disk I/0, CPU utilization, RAM memory usage
- Your trained model as W&B Artifact
- Environment: OS and Python types, Git repository and state, **training command**
<p align="center"><img width="900" alt="Weights & Biases dashboard" src="https://user-images.githubusercontent.com/26833433/135390767-c28b050f-8455-4004-adb0-3b730386e2b2.png"></p>
</details>
## Disabling wandb
- training after running `wandb disabled` inside that directory creates no wandb run
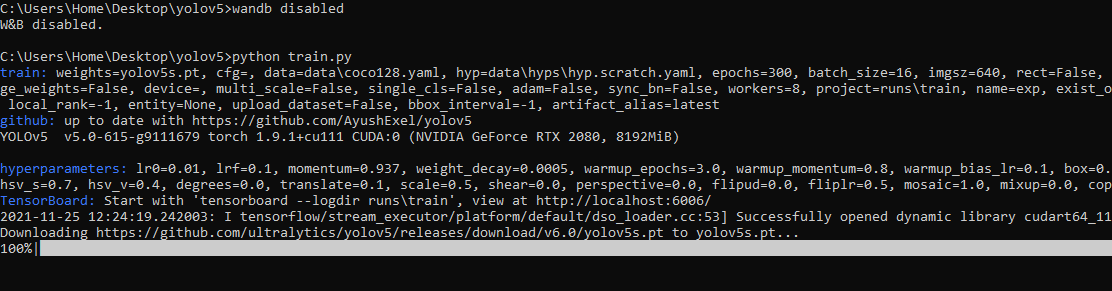
- To enable wandb again, run `wandb online`
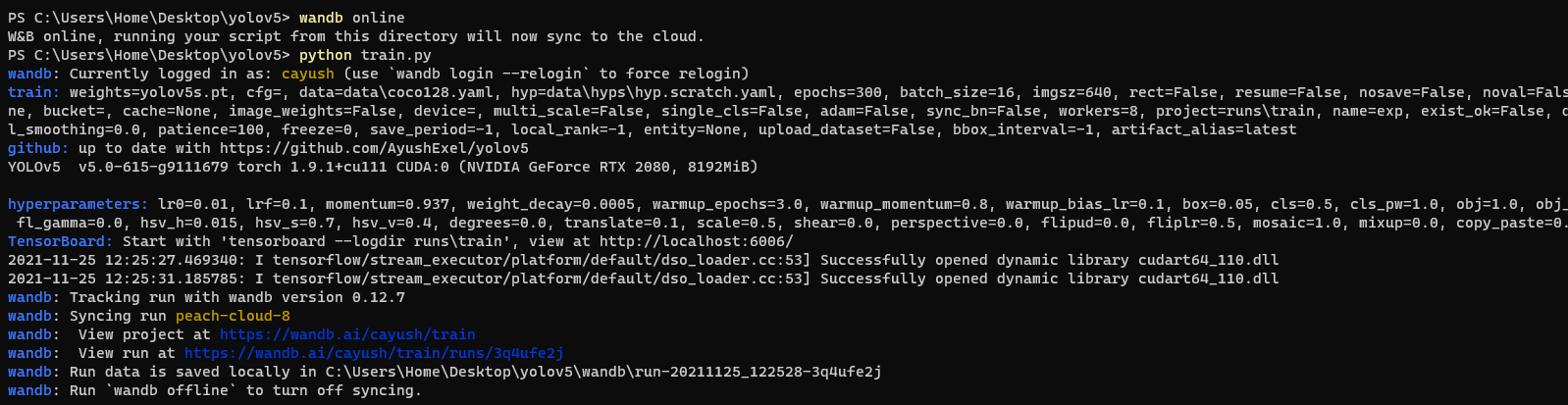
## Advanced Usage
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
<details open>
<h3> 1: Train and Log Evaluation simultaneousy </h3>
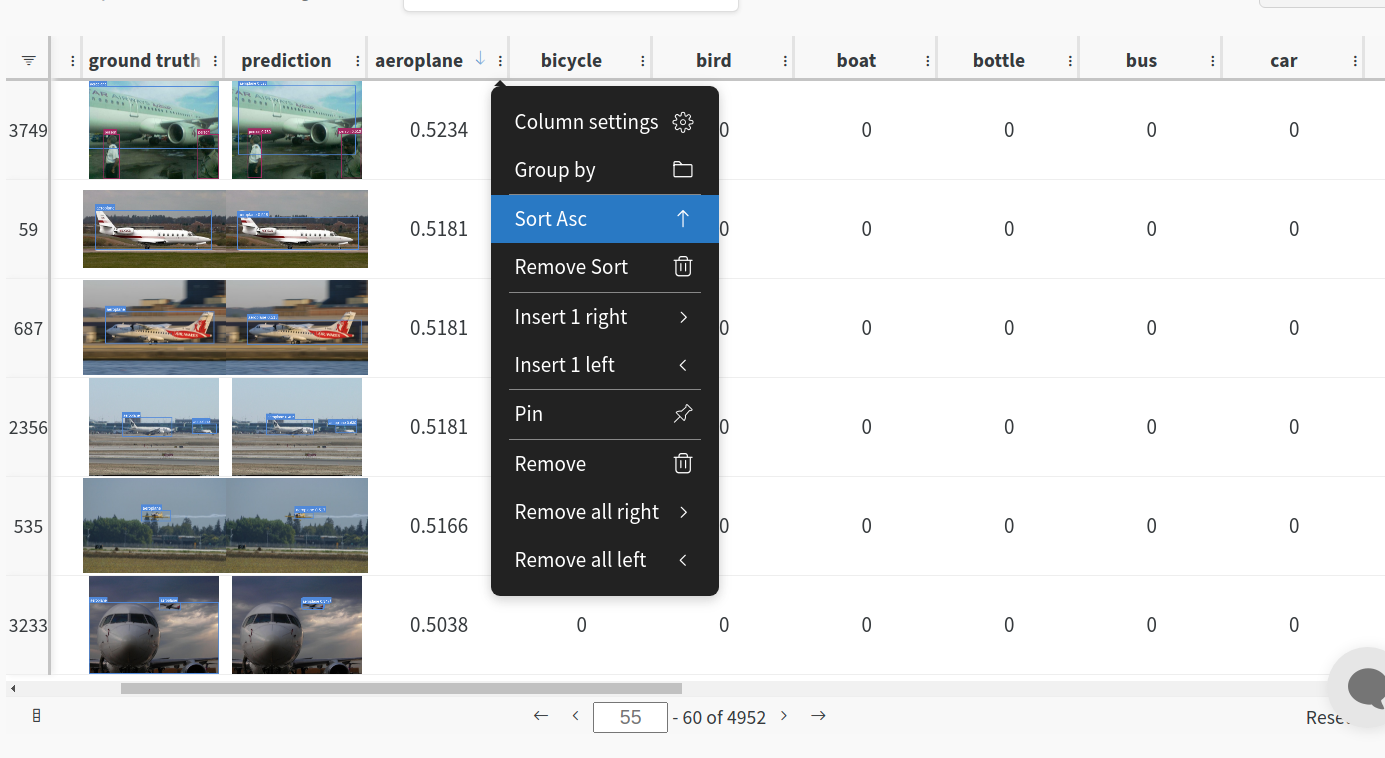
This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
so no images will be uploaded from your system more than once.
<details open>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --upload_data val</code>
</details>
<h3>2. Visualize and Version Datasets</h3>
Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data .. </code>

</details>
<h3> 3: Train using dataset artifact </h3>
When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that
can be used to train a model directly from the dataset artifact. <b> This also logs evaluation </b>
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --data {data}_wandb.yaml </code>

</details>
<h3> 4: Save model checkpoints as artifacts </h3>
To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval.
You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be logged
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --save_period 1 </code>

</details>
</details>
<h3> 5: Resume runs from checkpoint artifacts. </h3>
Any run can be resumed using artifacts if the <code>--resume</code> argument starts with聽<code>wandb-artifact://</code>聽prefix followed by the run path, i.e,聽<code>wandb-artifact://username/project/runid </code>. This doesn't require the model checkpoint to be present on the local system.
<details>
<summary> <b>Usage</b> </summary>
<b>Code</b> <code> $ python train.py --resume wandb-artifact://{run_path} </code>

</details>
<h3> 6: Resume runs from dataset artifact & checkpoint artifacts. </h3>
<b> Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device </b>
The syntax is same as the previous section, but you'll need to lof both the dataset and model checkpoints as artifacts, i.e, set bot <code>--upload_dataset</code> or
train fro
 人工智能-项目实践-信息检索-一个基于可视水印检测识别的数字媒体溯源应用系统 (146个子文件)
人工智能-项目实践-信息检索-一个基于可视水印检测识别的数字媒体溯源应用系统 (146个子文件)  scrapy.cfg 267B Dockerfile 2KB Dockerfile 821B Dockerfile-arm64 2KB Dockerfile-cpu 1KB .dockerignore 4KB vis_dataset.ipynb 129KB split.ipynb 6KB
scrapy.cfg 267B Dockerfile 2KB Dockerfile 821B Dockerfile-arm64 2KB Dockerfile-cpu 1KB .dockerignore 4KB vis_dataset.ipynb 129KB split.ipynb 6KB bus.jpg 476KB zidane.jpg 165KB LICENSE 34KB README.md 11KB README.md 2KB SourceHanSansCN-Regular.otf 8.39MB
bus.jpg 476KB zidane.jpg 165KB LICENSE 34KB README.md 11KB README.md 2KB SourceHanSansCN-Regular.otf 8.39MB Watermark_Trace.pdf 2.09MB result.pdf 347KB dataset.pdf 344KB yolo.pdf 340KB logo.pdf 290KB algo.pdf 283KB framework.pdf 120KB
Watermark_Trace.pdf 2.09MB result.pdf 347KB dataset.pdf 344KB yolo.pdf 340KB logo.pdf 290KB algo.pdf 283KB framework.pdf 120KB lena.png 463KB kfc.png 21KB bilibili-2.png 19KB 百度.png 16KB baidu.png 16KB taobao.png 13KB douyu.png 11KB alipay.png 10KB 知乎.png 9KB zhihu.png 9KB sougou.png 8KB hauwei.png 8KB kuaishou.png 8KB tencent_tv.png 7KB tieba-1.png 7KB youku.png 7KB wechat.png 7KB wechat.png 7KB GitHub.png 6KB 新浪微博.png 6KB sina.png 6KB 小红书.png 6KB xiaohongshu.png 6KB tieba-2.png 6KB bilibili.png 5KB QQzone.png 5KB cctv.png 5KB iqiyi-1.png 5KB mangguo.png 5KB baidu_music.png 5KB douyin.png 5KB netease_music.png 5KB apple.png 4KB iqiyi-2.png 4KB keep.png 4KB microsoft.png 2KB yolov5l.pt 89.29MB best.pt 88.51MB dataloaders.py 46KB general.py 40KB train.py 34KB common.py 34KB export.py 29KB wandb_utils.py 27KB tf.py 23KB plots.py 21KB val.py 19KB generator.py 15KB yolo.py 15KB metrics.py 14KB torch_utils.py 13KB detect.py 13KB augmentations.py 12KB trace.py 11KB loss.py 10KB __init__.py 8KB autoanchor.py 7KB downloads.py 7KB hubconf.py 6KB benchmarks.py 6KB experimental.py 4KB activations.py 3KB baidu.py 3KB callbacks.py 2KB autobatch.py 2KB restapi.py 1KB sweep.py 1KB resume.py 1KB __init__.py 1KB log_dataset.py 1KB example_request.py 368B __init__.py 0B __init__.py 0B __init__.py 0B __init__.py 0B userdata.sh 1KB get_coco.sh 900B mime.sh 780B get_coco128.sh 615B
lena.png 463KB kfc.png 21KB bilibili-2.png 19KB 百度.png 16KB baidu.png 16KB taobao.png 13KB douyu.png 11KB alipay.png 10KB 知乎.png 9KB zhihu.png 9KB sougou.png 8KB hauwei.png 8KB kuaishou.png 8KB tencent_tv.png 7KB tieba-1.png 7KB youku.png 7KB wechat.png 7KB wechat.png 7KB GitHub.png 6KB 新浪微博.png 6KB sina.png 6KB 小红书.png 6KB xiaohongshu.png 6KB tieba-2.png 6KB bilibili.png 5KB QQzone.png 5KB cctv.png 5KB iqiyi-1.png 5KB mangguo.png 5KB baidu_music.png 5KB douyin.png 5KB netease_music.png 5KB apple.png 4KB iqiyi-2.png 4KB keep.png 4KB microsoft.png 2KB yolov5l.pt 89.29MB best.pt 88.51MB dataloaders.py 46KB general.py 40KB train.py 34KB common.py 34KB export.py 29KB wandb_utils.py 27KB tf.py 23KB plots.py 21KB val.py 19KB generator.py 15KB yolo.py 15KB metrics.py 14KB torch_utils.py 13KB detect.py 13KB augmentations.py 12KB trace.py 11KB loss.py 10KB __init__.py 8KB autoanchor.py 7KB downloads.py 7KB hubconf.py 6KB benchmarks.py 6KB experimental.py 4KB activations.py 3KB baidu.py 3KB callbacks.py 2KB autobatch.py 2KB restapi.py 1KB sweep.py 1KB resume.py 1KB __init__.py 1KB log_dataset.py 1KB example_request.py 368B __init__.py 0B __init__.py 0B __init__.py 0B __init__.py 0B userdata.sh 1KB get_coco.sh 900B mime.sh 780B get_coco128.sh 615B共 146 条
- 1
- 2
资源评论


博士僧小星
- 粉丝: 2455
- 资源: 5998









最新资源
- AI生成散文【指令+教程】.rar
- 模拟芯片行业:从竞争格局到产业生态深度剖析及其未来前景展望
- AI写小说指令【指令+教程】.rar
- 本地部署并运行DeepSeekPDF
- 爆款短视频脚本文案【指令+教程】.rar
- 基于CNN-LSTM-Attention的多特征输入多因变量输出回归预测模型(Matlab 2021版,含详细注释及多种结果图展示),基于CNN-LSTM-Attention的多特征输入多因变量回归预
- Matlab多维度信号处理与预测:大型设备振动信号的检测、分类与预警系统研究,Matlab多维度信号处理与预测系统:大型设备振动信号的检测、分类与安全预警策略,Matlab多维度分析,信号处理,预测
- Linux常用命令,linux常用命PDF令
- deepseek 应该怎样提问.zip
- Deepseek+高效使用指南.zip
- Deepseek不好用,是你真的不会用啊!.zip
- 当我用 DeepSeek 学习、工作和玩,惊艳!含提问攻略、使用实例和心得.zip
- DeepSeek小白使用指南,99%+的人都不知道的使用技巧(建议收藏).zip
- DeepSeek最强使用攻略,放弃复杂提示词,直接提问效果反而更好?.zip
- 零基础使用DeepSeek高效提问技巧.zip
- 让你的DeepSeek能力翻倍的使用指南.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


