SVM
目录
1 目的 ......................................................................................................................................2
2 数据处理 ..............................................................................................................................2
2.1 数据下载 ...................................................................................................................2
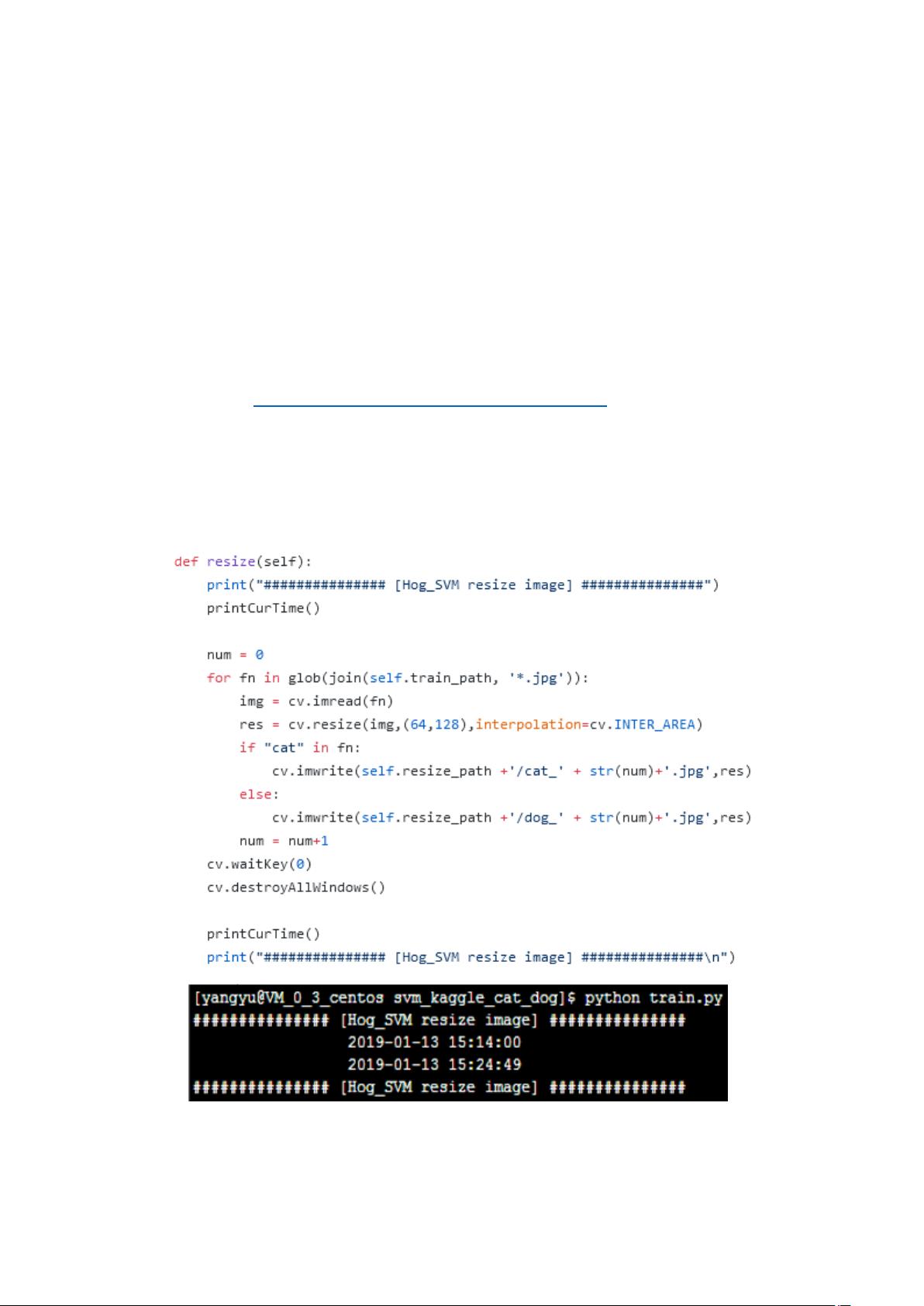
2.2 格式化数据 ...............................................................................................................2
3 SVM 模型...............................................................................................................................3
3.1 训练与结果分析 .......................................................................................................3
3.2 目录结构 ...................................................................................................................4