



GPT 原来这么简单?
我们知道,OpenAI 的 GPT 系列通过大规模和预训练的方式打开了人
工智能的新时代,然而对于大多数研究者来说,语言大模型(LLM)因
为体量和算力需求而显得高不可攀。在技术向上发展的同时,人们也一
直在探索「最简」的 GPT 模式。
近日,特斯拉前 AI 总监,刚刚回归 OpenAI 的 Andrej Karpathy 介绍
了一种最简 GPT 的玩法,或许能为更多人了解这种流行 AI 模型背后
的技术带来帮助。
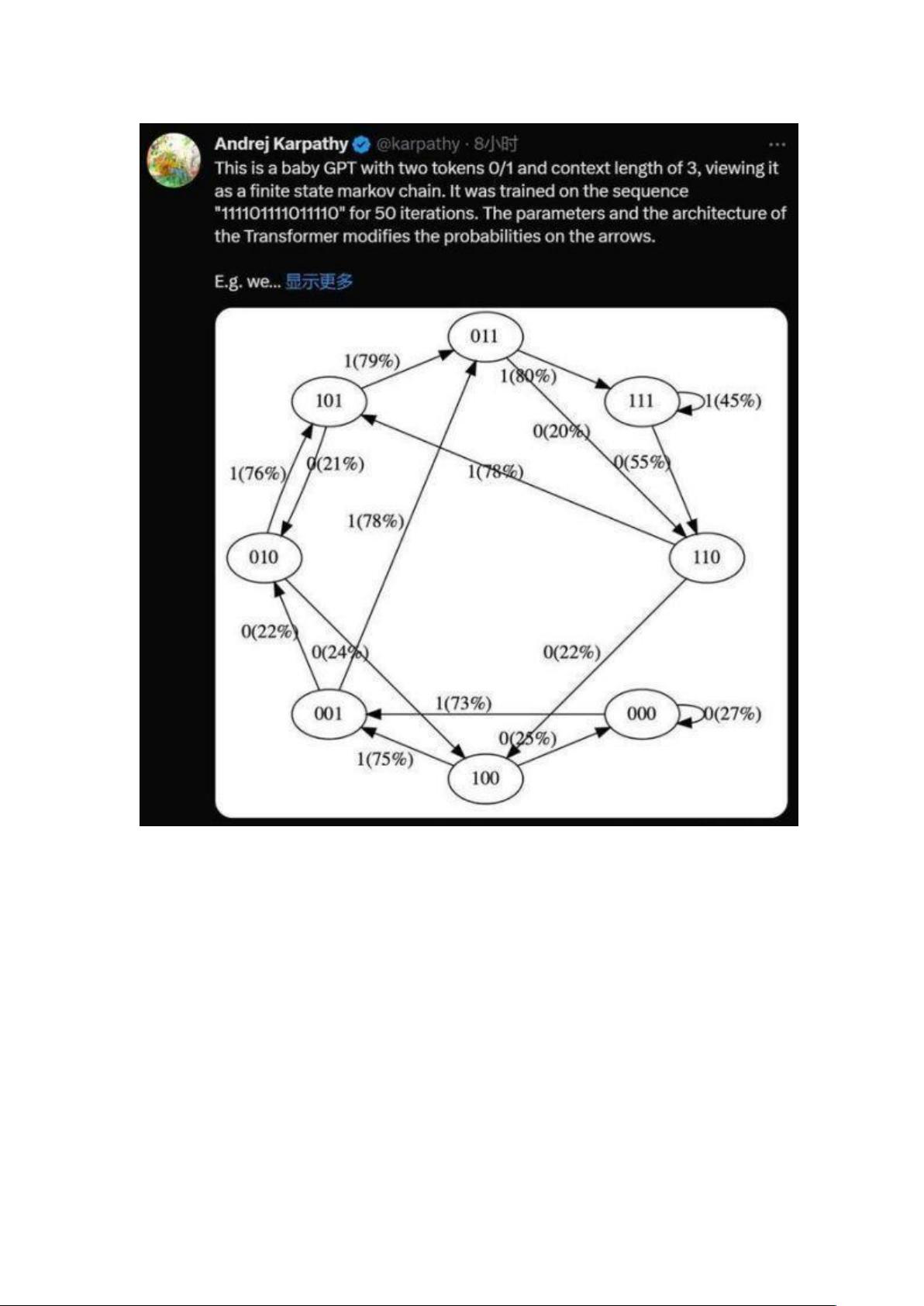
是的,这是一个带有两个 token 0/1 和上下文长度为 3 的极简 GPT,
将其视为有限状态马尔可夫链。它在序列「111101111011110」上训
练了 50 次迭代,Transformer 的参数和架构修改了箭头上的概率。
例如我们可以看到:
�

在训练数据中,状态 101 确定性地转换为 011,因此该转换的概率变
得更高 (79%)。但不接近于 100%,因为这里只做了 50 步优化。
�
�
状态 111 以 50% 的概率分别进入 111 和 110,模型几乎已学会了
(45%、55%)。
�
�
在训练期间从未遇到过像 000 这样的状态,但具有相对尖锐的转换概
率,例如 73% 转到 001。这是 Transformer 归纳偏差的结果。你可
能会想这是 50%,除了在实际部署中几乎每个输入序列都是唯一的,
而不是逐字地出现在训练数据中。
�
通过简化,Karpathy 已让 GPT 模型变得易于可视化,让你可以直观
地了解整个系统。
实际上,即使是 GPT 的最初版本,模型的体量很相当可观:在 2018
年,OpenAI 发布了第一代 GPT 模型,从论文《Improving Language
Understanding by Generative Pre-Training》可以了解到,其采用了 12
层的 Transformer Decoder 结构,使用约 5GB 无监督文本数据进行
训练。

但如果将其概念简化,GPT 是一种神经网络,它采用一些离散 token
序列并预测序列中下一个 token 的概率。例如,如果只有两个标记 0
和 1,那么一个很小的二进制 GPT 可以例如告诉我们:
[0,1,0] ---> GPT ---> [P (0) = 20%, P (1) = 80%]
在这里,GPT 采用位序列 [0,1,0],并根据当前的参数设置,预测下一
个为 1 的可能性为 80%。重要的是,默认情况下 GPT 的上下文长度
是有限的。如果上下文长度为 3,那么它们在输入时最多只能使用 3
个 token。在上面的例子中,如果我们抛出一枚有偏差的硬币并采样 1
确实应该是下一个,那么我们将从原始状态 [0,1,0] 转换到新状态
[1,0,1]。我们在右侧添加了新位 (1),并通过丢弃最左边的位 (0) 将序
列截断为上下文长度 3,然后可以一遍又一遍地重复这个过程以在状态
之间转换。
很明显,GPT 是一个有限状态马尔可夫链:有一组有限的状态和它们
之间的概率转移箭头。每个状态都由 GPT 输入处 token 的特定设置
定义(例如 [0,1,0])。我们可以以一定的概率将其转换到新状态,如
[1,0,1]。让我们详细看看它是如何工作的:
# hyperparameters for our GPT# vocab size is 2, so we only have two possible
tokens: 0,1vocab_size = 2# context length is 3, so we take 3 bits to predi
ct the next bit probabilitycontext_length = 3













