SeimiCrawler
============
[](https://github.com/zhegexiaohuozi/JsoupXpath/releases)
[](https://opensource.org/licenses/Apache-2.0)
An agile,powerful,standalone,distributed crawler framework.
SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油。
# 简介 #
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的Seimi帮你搞定。设计思想上SeimiCrawler受Python的爬虫框架Scrapy启发,同时融合了Java语言本身特点与Spring的特性,并希望在国内更方便且普遍的使用更有效率的XPath解析HTML,所以SeimiCrawler默认的HTML解析器是[JsoupXpath](http://jsoupxpath.wanghaomiao.cn)(独立扩展项目,非jsoup自带),默认解析提取HTML数据工作均使用XPath来完成(当然,数据处理亦可以自行选择其他解析器)。并结合[SeimiAgent](https://github.com/zhegexiaohuozi/SeimiAgent)彻底完美解决复杂动态页面渲染抓取问题。
# 号外 #
- 2016.04.14
用于实现浏览器级动态页面渲染以及抓取的[SeimiAgent](https://github.com/zhegexiaohuozi/SeimiAgent)已经发布。SeimiAgent基于Qtwebkit开发,主流浏览器内核(chrome,safari等),可在服务器端后台运行,并通过http协议发布对外调用API,支持任何语言或框架从SeimiAgent获取服务,彻底的解决动态页面渲染抓取等问题。具体可以参考SeimiAgent主页。SeimiCrawler已经在`v0.3.0`中内置支持SeimiAgent的使用并添加了[demo](https://github.com/zhegexiaohuozi/SeimiCrawler/blob/master/demo/src/main/java/cn/wanghaomiao/crawlers/SeimiAgentDemo.java),具体请查看demo或是官方文档。
- 2016.01.05
专门为SeimiCrawler工程打包部署的`maven-seimicrawler-plugin`已经发布可用,详细请继续参阅[maven-seimicrawler-plugin](https://github.com/zhegexiaohuozi/maven-seimicrawler-plugin)或是下文`工程化打包部署`章节。
# 原理示例 #
## 基本原理 ##
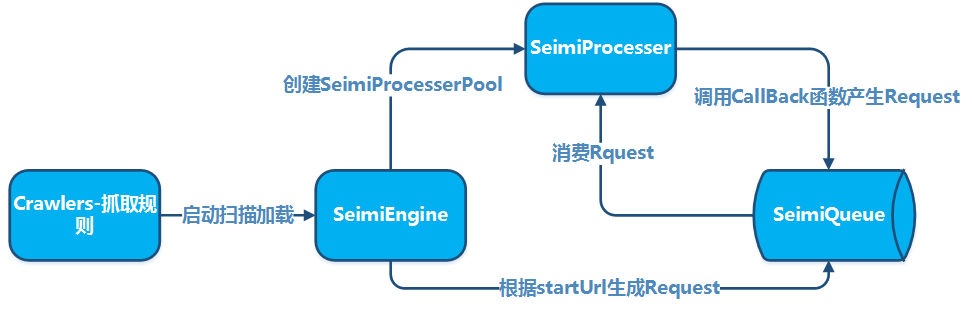
## 集群原理 ##
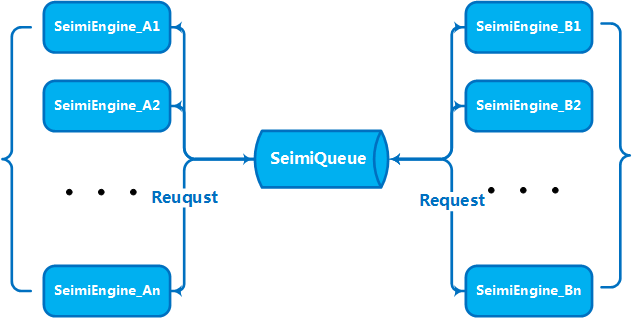
# 快速开始 #
添加maven依赖(中央maven库最新版本1.3.5):
```
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>1.3.5</version>
</dependency>
```
在包`crawlers`下添加爬虫规则,例如:
```
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(new Request(s.toString(),"getTitle"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
//do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
然后随便某个包下添加启动Main函数,启动SeimiCrawler:
```
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
```
以上便是一个最简单的爬虫系统开发流程。
## 工程化打包部署 ##
上面可以方便的用来开发或是调试,当然也可以成为生产环境下一种启动方式。但是,为了便于工程化部署与分发,SeimiCrawler提供了专门的打包插件用来对SeimiCrawler工程进行打包,打好的包可以直接分发部署运行了。
pom中添加添加plugin
```
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.2.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
<!--<configuration>-->
<!-- 默认target目录 -->
<!--<outputDirectory>/some/path</outputDirectory>-->
<!--</configuration>-->
</plugin>
```
执行`mvn clean package`即可,打好包目录结构如下:
```
.
├── bin # 相应的脚本中也有具体启动参数说明介绍,在此不再敖述
│ ├── run.bat #windows下启动脚本
│ └── run.sh #Linux下启动脚本
└── seimi
├── classes #Crawler工程业务类及相关配置文件目录
└── lib #工程依赖包目录
```
接下来就可以直接用来分发与部署了。
> 详细请继续参阅[maven-seimicrawler-plugin](https://github.com/zhegexiaohuozi/maven-seimicrawler-plugin)
# 更多文档 #
目前可以参考demo工程中的样例,基本包含了主要的特性用法。更为细致的文档移步[SeimiCrawler主页](http://seimi.wanghaomiao.cn)中进一步查看
# 社区讨论 #
大家有什么问题或建议现在都可以选择通过下面的邮件列表讨论,首次发言前需先订阅并等待审核通过(主要用来屏蔽广告宣传等)
- 订阅:请发邮件到 `seimicrawler+subscribe@googlegroups.com`
- 发言:请发邮件到 `seimicrawler@googlegroups.com`
- 退订:请发邮件至 `seimicrawler+unsubscribe@googlegroups.com`
- QQ群:`557410934`

这个就是给大家自由沟通啦
- 微信订阅号

里面会发布一些使用案例等文章,以及seimi体系相关项目的最新更新动态等。
# Change log #
请参阅 [ChangeLog.md](https://github.com/zhegexiaohuozi/SeimiCrawler/blob/master/ChangeLog.md)
# 项目源码 #
[Github](https://github.com/zhegexiaohuozi/SeimiCrawler)
> **BTW:**
> 如果您觉着这个项目不错,到github上`star`一下,我是不介意的 ^_^
SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油

需积分: 5 28 浏览量
2024-05-14
16:13:56
上传
评论
收藏 138KB ZIP 举报
 SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油 (107个子文件)
SeimiCrawler的目标是成为Java里最实用的爬虫框架,大家一起加油 (107个子文件)  spring.factories 128B .gitignore 109B SeimiProcessor.java 9KB Request.java 9KB CrawlerModel.java 9KB HcDownloader.java 8KB OkHttpDownloader.java 7KB DefaultRedisQueue.java 7KB SeimiBeanResolver.java 6KB HcRequestGenerator.java 6KB GenericUtils.java 5KB SeimiScanner.java 5KB Response.java 5KB SeimiConfig.java 4KB OkHttpRequestGenerator.java 4KB Seimi.java 4KB SeimiCrawlerBootstrapListener.java 4KB BaseSeimiCrawler.java 4KB Run.java 4KB HttpClientFactory.java 4KB MySelfRedisQueueImpl.java 4KB DefaultLocalQueue.java 4KB HttpClientCMPBox.java 4KB PushRequestHttpProcessor.java 3KB JDWalker.java 3KB OkHttpClientBuilderBox.java 3KB CrawlerCache.java 3KB StructValidator.java 3KB SeimiRedirectStrategy.java 2KB Crawler.java 2KB SeimiCrawler.java 2KB SeimiCrawlerBeanRegistar.java 2KB SeimiAgentDemo.java 2KB SeimiHttpHandler.java 2KB UseCookie.java 2KB CrawlerProperties.java 2KB DynamicUserAgent.java 2KB MutiPageNewsCrawler.java 2KB StrFormatUtil.java 2KB SeimiContext.java 2KB UseDynamicProxy.java 2KB SeimiCrawlerBeanPostProcessor.java 2KB DatabaseMybatisDemo.java 2KB BasicWithScheduler.java 2KB DefaultRedisQueueEG.java 2KB DefaultRedisQueueEG.java 2KB CookiesManager.java 2KB CrawlerStatusHttpProcessor.java 2KB SeimiQueue.java 2KB StoreInFile.java 2KB UseProxy.java 2KB SeimiInterceptor.java 2KB IntercepterDemo.java 2KB SeimiDownloader.java 1KB SelfConfigRedisQueueEG.java 1KB Basic.java 1KB UseDelay.java 1KB Basic.java 1KB UseBeanResolver.java 1KB SeimiAgentContentType.java 1KB Xpath.java 1KB HttpRequestProcessor.java 1KB Interceptor.java 1KB BlogContent.java 1KB TestCmd.java 1KB Queue.java 1KB DemoInterceptor.java 1KB HttpClientConnectionManagerProvider.java 1KB OkHttpClientBuilderProvider.java 1KB NotNull.java 1KB CommonObject.java 1KB SeimiDefScanConfig.java 1KB SeimiHttpType.java 1KB SeimiCookie.java 1KB SeimiCrawlerAutoConfigurationTest.java 1023B IndexController.java 990B SeimiProcessExcepiton.java 971B HttpMethod.java 935B BodyType.java 924B SeimiCrawlerAutoConfiguration.java 912B SeimiInitExcepiton.java 897B SeimiBeanResolveException.java 880B CastToNumber.java 840B EnableSeimiCrawler.java 608B StrFormatUtilTest.java 538B MybatisStoreDAO.java 531B SeimiCallbackFunc.java 480B SeimiCrawlerBaseConfig.java 440B SeimiCrawlerApplication.java 440B StartWorkers.java 290B Boot.java 289B Constants.java 285B DoLog.java 273B LICENSE 11KB README.md 6KB ChangeLog.md 5KB seimi.properties 365B application.properties 131B db_demo.sql 272B pom.xml 7KB
spring.factories 128B .gitignore 109B SeimiProcessor.java 9KB Request.java 9KB CrawlerModel.java 9KB HcDownloader.java 8KB OkHttpDownloader.java 7KB DefaultRedisQueue.java 7KB SeimiBeanResolver.java 6KB HcRequestGenerator.java 6KB GenericUtils.java 5KB SeimiScanner.java 5KB Response.java 5KB SeimiConfig.java 4KB OkHttpRequestGenerator.java 4KB Seimi.java 4KB SeimiCrawlerBootstrapListener.java 4KB BaseSeimiCrawler.java 4KB Run.java 4KB HttpClientFactory.java 4KB MySelfRedisQueueImpl.java 4KB DefaultLocalQueue.java 4KB HttpClientCMPBox.java 4KB PushRequestHttpProcessor.java 3KB JDWalker.java 3KB OkHttpClientBuilderBox.java 3KB CrawlerCache.java 3KB StructValidator.java 3KB SeimiRedirectStrategy.java 2KB Crawler.java 2KB SeimiCrawler.java 2KB SeimiCrawlerBeanRegistar.java 2KB SeimiAgentDemo.java 2KB SeimiHttpHandler.java 2KB UseCookie.java 2KB CrawlerProperties.java 2KB DynamicUserAgent.java 2KB MutiPageNewsCrawler.java 2KB StrFormatUtil.java 2KB SeimiContext.java 2KB UseDynamicProxy.java 2KB SeimiCrawlerBeanPostProcessor.java 2KB DatabaseMybatisDemo.java 2KB BasicWithScheduler.java 2KB DefaultRedisQueueEG.java 2KB DefaultRedisQueueEG.java 2KB CookiesManager.java 2KB CrawlerStatusHttpProcessor.java 2KB SeimiQueue.java 2KB StoreInFile.java 2KB UseProxy.java 2KB SeimiInterceptor.java 2KB IntercepterDemo.java 2KB SeimiDownloader.java 1KB SelfConfigRedisQueueEG.java 1KB Basic.java 1KB UseDelay.java 1KB Basic.java 1KB UseBeanResolver.java 1KB SeimiAgentContentType.java 1KB Xpath.java 1KB HttpRequestProcessor.java 1KB Interceptor.java 1KB BlogContent.java 1KB TestCmd.java 1KB Queue.java 1KB DemoInterceptor.java 1KB HttpClientConnectionManagerProvider.java 1KB OkHttpClientBuilderProvider.java 1KB NotNull.java 1KB CommonObject.java 1KB SeimiDefScanConfig.java 1KB SeimiHttpType.java 1KB SeimiCookie.java 1KB SeimiCrawlerAutoConfigurationTest.java 1023B IndexController.java 990B SeimiProcessExcepiton.java 971B HttpMethod.java 935B BodyType.java 924B SeimiCrawlerAutoConfiguration.java 912B SeimiInitExcepiton.java 897B SeimiBeanResolveException.java 880B CastToNumber.java 840B EnableSeimiCrawler.java 608B StrFormatUtilTest.java 538B MybatisStoreDAO.java 531B SeimiCallbackFunc.java 480B SeimiCrawlerBaseConfig.java 440B SeimiCrawlerApplication.java 440B StartWorkers.java 290B Boot.java 289B Constants.java 285B DoLog.java 273B LICENSE 11KB README.md 6KB ChangeLog.md 5KB seimi.properties 365B application.properties 131B db_demo.sql 272B pom.xml 7KB共 107 条
- 1
- 2
资源评论














