
使用小结
简介
是一个专门为互联网上的网页进行存档而开发的网页检索器。它使用 编写并且
完全开源。它主要的用户界面可以通过一个 流量器来访问并通过它来控制检索器的行
为,另外,它还有一个命令行工具来供用户选择调用。
是由互联网档案馆和北欧国家图书馆联合规范化编写于 年初。第一次正式发
布是在 年 月,并不断的被互联网档案馆和其他感兴趣的第三方改进着。到现在已经
成为一个成熟的开源爬虫,并被广泛使用。
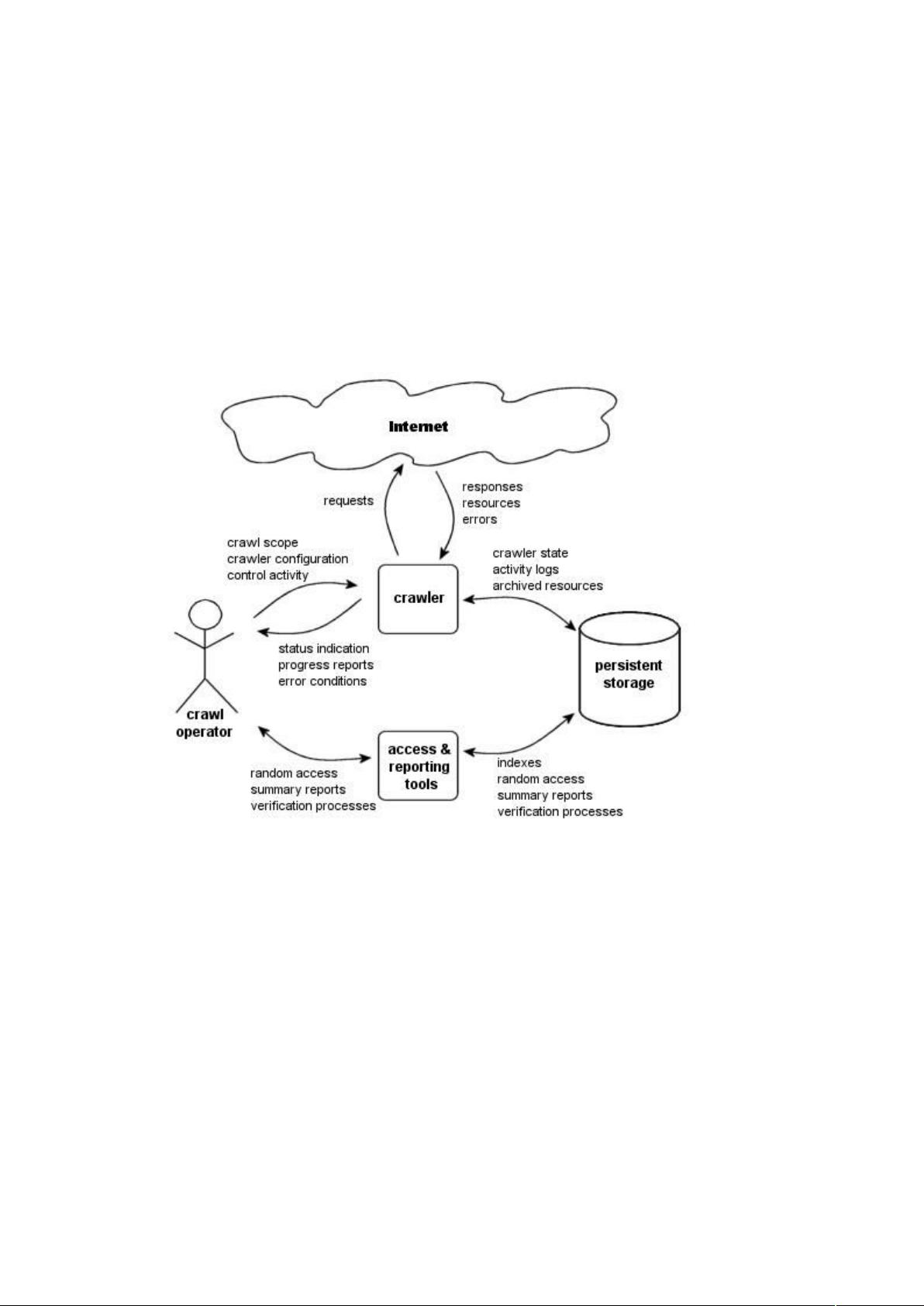
的操作模型
从模型中可以看到,利用 我们可以轻松从互联网上获取信息并将它们全部存储下来,
然后可以任意的访问获取到的网页信息并可以查看报告。
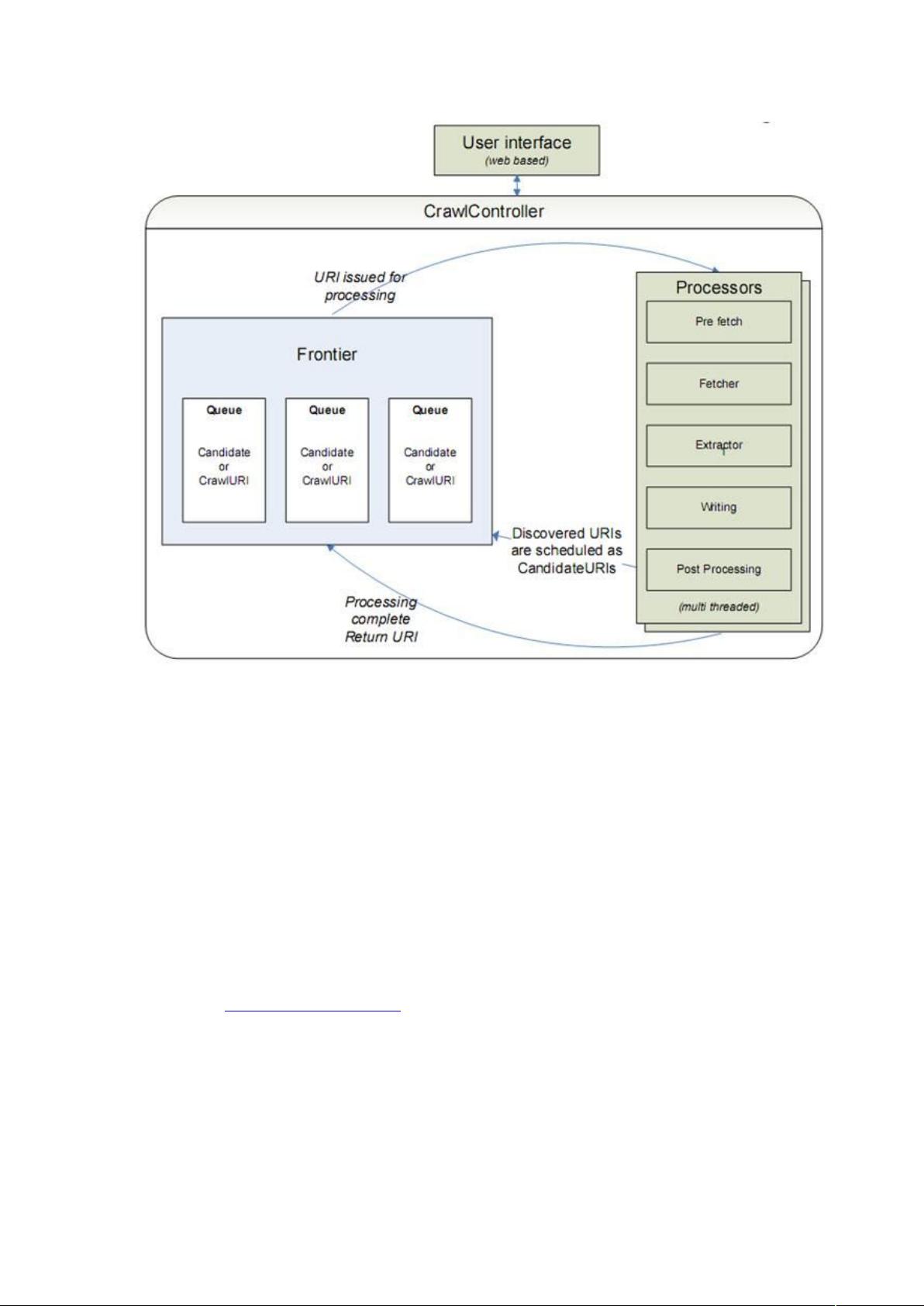
的整体结构简图如下:
剩余11页未读,继续阅读
资源评论

 zzh189945977772014-07-14非常有帮助,但是其中有少许缺漏,需要自己添加
zzh189945977772014-07-14非常有帮助,但是其中有少许缺漏,需要自己添加- zhangyuemeimeimei2013-12-23里面有具体代码,挺好用的
- xiao_yun2014-03-25可以使用,还不错哦
 HMH24782392014-08-25不错!正好是我需要的
HMH24782392014-08-25不错!正好是我需要的
a2362432
- 粉丝: 0
- 资源: 1









最新资源
- 13-募捐义卖活动策划书方案.docx
- 阳光义卖策划书.docx
- 12-募捐义卖活动策划书.docx
- 公司运动会策划书.doc
- 公司运动会策划案(详细).docx
- 程序设计基础课程辅助教学系统_6e043x2u.zip
- 趣味运动会策划方案.doc
- 骑行运动活动策划.pptx
- 复兴村医疗管理系统-6q87918h.zip
- 职工足球联赛活动方案 (2).docx
- 足球比赛策划.doc
- Qt源码~~EQ曲线升级版 代码写的不错,注释也很详细了
- 高考志愿智能推荐系统_2a1qfv22.zip
- 基于 springboot +vue 的实践性教学系统-o74t04z0-论文.zip
- 基于 javaee 的超市外卖系统的设计与实现_pp44m888--论文.zip
- 基于Java的车辆保险理赔平台的设计与实现-za60wo3t.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


