KaiwuDB 分布式系统 Range Split and Merge 原理详解.pdf

需积分: 0 22 浏览量
更新于2024-03-07
收藏 3.5MB PDF 举报
### KaiwuDB 分布式系统 Range Split and Merge 原理详解
#### 一、KaiwuDB 简介
KaiwuDB 是一款分布式数据库系统,它支持事务处理和SQL查询,能够高效地存储和管理大规模数据。在KaiwuDB中,数据被划分为多个范围(Range),每个范围包含一组键值对(<k,v>)。这种设计有助于提高系统的可扩展性和性能。
#### 二、Range 概念与物理存储抽象
##### 2.1 Range 的概念
Range 在KaiwuDB中表示一个有序的键值对集合,这些键值对按照键(Key)的顺序进行排序。一个Range可以包含大量的键值对,并且为了确保数据的一致性,KaiwuDB采用了一致性协议来管理这些数据。
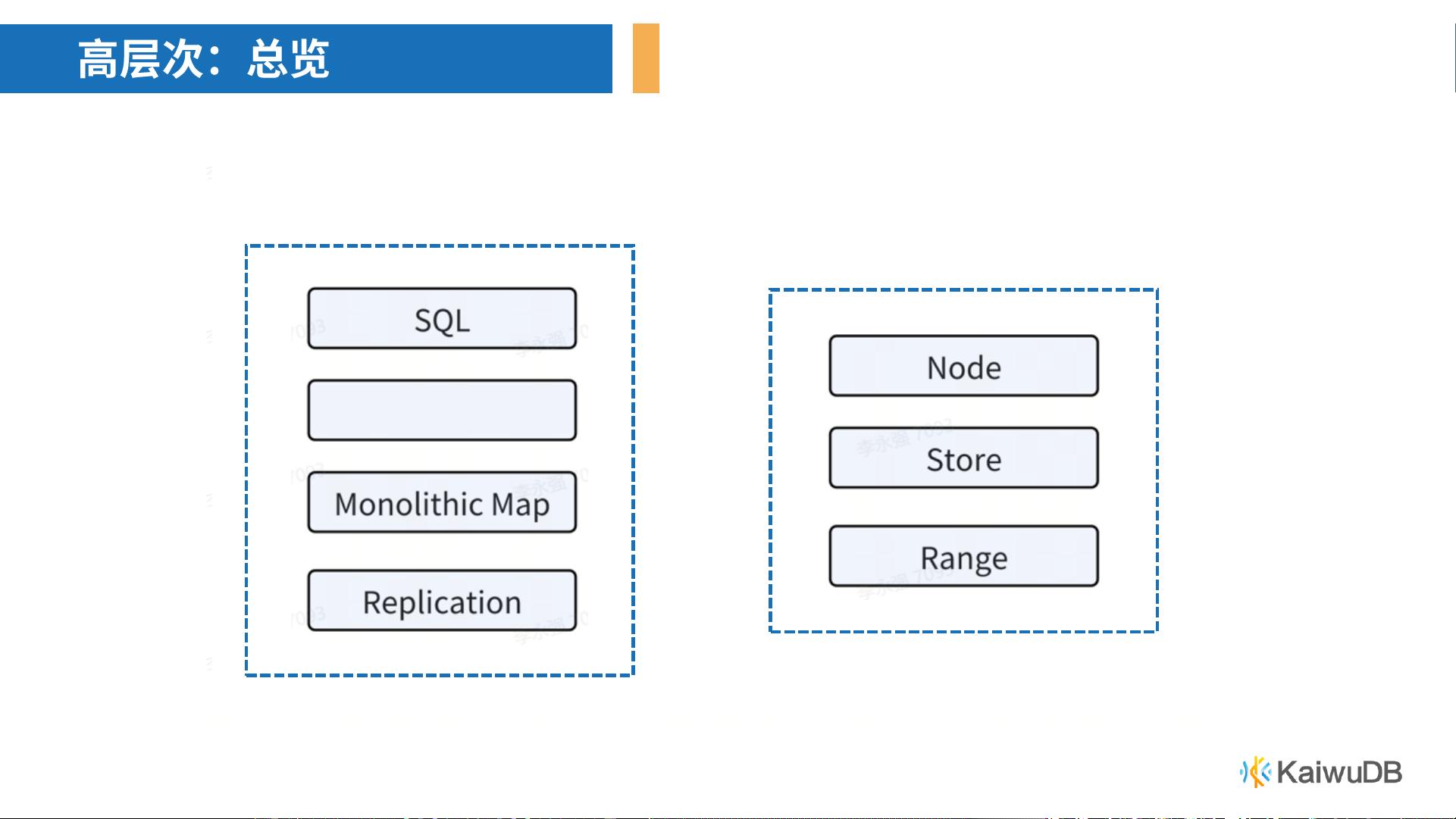
##### 2.2 物理存储抽象
KaiwuDB采用了多层存储抽象,主要包括:
- **事务键值(Transactional KV)**:这是最底层的数据存储模型,用于存储键值对。
- **SQL 层**:提供SQL接口,使得用户可以通过SQL语句进行数据操作。
- **单体映射(Monolithic Map)**:一种抽象模型,用于表示整个系统的键值对集合。
- **节点(Node)**:每个节点上运行着一个或多个Range实例,这些实例通常部署在容器(如Docker)中。
- **存储(Store)**:存储实际的数据和元数据,通常使用高速固态硬盘(SSD)来实现低延迟和高性能。
#### 三、KaiwuDB 中的Range 分区与合并
##### 3.1 Range 分区(Split)
当Range中的数据量达到一定阈值时,KaiwuDB会自动将该Range分成两个较小的Range,这一过程称为Range Split。Range Split的主要目的是为了保持每个Range的大小在合理的范围内,从而避免单一Range变得过大而影响性能。
**Range Split的触发条件**:
- 当一个Range的大小超过预定阈值(例如64MB)时,系统会自动将其分裂成两个新的Range。
- 这个阈值可以根据实际情况进行调整,以适应不同的应用场景。
**Range Split的过程**:
1. **选择分裂点**:根据键值分布情况,选择一个合适的键作为分裂点。
2. **复制数据**:复制分裂点之前的数据到新创建的第一个Range中。
3. **重新分配数据**:将分裂点之后的数据移动到新创建的第二个Range中。
4. **更新元数据**:更新所有涉及到的节点上的元数据,确保一致性。
##### 3.2 Range 合并(Merge)
当两个相邻的Range长时间内数据增长较慢或者数据量减少时,为了减少Range的数量和优化资源利用率,KaiwuDB会执行Range Merge操作,即将两个Range合并为一个。
**Range Merge的触发条件**:
- 两个相邻的Range长时间内数据增长较慢。
- 两个相邻的Range的数据总量低于预定阈值。
**Range Merge的过程**:
1. **合并数据**:将两个Range中的数据合并到一个Range中。
2. **更新元数据**:更新所有涉及到的节点上的元数据,确保一致性。
3. **释放资源**:释放被合并Range的存储空间和其他资源。
#### 四、一致性协议与事务支持
##### 4.1 一致性协议
为了保证数据的一致性,KaiwuDB采用了基于Raft一致性算法的共识机制。Raft是一种简单易理解的一致性算法,它可以有效地处理分布式系统中的故障恢复和成员变更等问题。
**Raft算法的特点**:
- **简单性**:相对于其他一致性算法(如Paxos),Raft更易于理解和实现。
- **领导选举**:Raft通过选举出一个领导者(Leader)来协调数据复制过程。
- **日志复制**:领导者负责接收客户端请求并将请求转换为日志条目,然后复制到其他副本(Follower)中。
- **安全性**:通过多数派投票机制确保数据的一致性。
##### 4.2 事务支持
KaiwuDB支持原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)这四个ACID属性,保证了事务的正确性和数据的一致性。
**事务处理流程**:
1. **提交记录**:事务开始时创建一个事务记录(Transaction Record)。
2. **一致性检查**:在事务执行过程中,系统会检查数据的一致性。
3. **提交/回滚**:事务完成后,如果一切正常则提交事务;如果出现异常,则回滚事务。
4. **结果确认**:一旦事务提交成功,结果将永久保存在系统中。
#### 五、KaiwuDB 中的键值存储模型
KaiwuDB采用了一种键值存储模型,其中键(Key)是唯一的标识符,用于唯一确定一条记录。在SQL层面上,键由表名、索引名、主键等组成,具体格式如下:
```
Key:/<table>/<index>/<key>/<column>
```
例如,在插入一条水果记录时,键可能如下所示:
```
Key:/fruit/primary/1/name
Value: "apple"
```
这里的`fruit`表示表名,`primary`表示索引类型,`1`表示主键值,`name`表示列名。这种键的设计使得数据能够按照一定的逻辑结构进行组织,方便快速查找和访问。
#### 六、总结
KaiwuDB是一款强大的分布式数据库系统,通过Range Split和Range Merge等技术实现了高效的水平扩展能力。同时,它还提供了事务支持和一致性保障,使得系统能够在分布式环境中保证数据的一致性和完整性。对于大规模数据处理和分析场景来说,KaiwuDB无疑是一个值得考虑的选择。




191 浏览量
186 浏览量
108 浏览量
2023-01-03 上传
2023-09-13 上传
2023-04-13 上传
112 浏览量
2024-06-25 上传
2024-02-29 上传
182 浏览量
106 浏览量
资源评论


KaiwuDB数据库
- 粉丝: 514
- 资源: 14









最新资源
- 毕设和企业适用springboot企业管理类及远程医疗平台源码+论文+视频.zip
- 毕设和企业适用springboot企业管理类及在线教育互动平台源码+论文+视频.zip
- 毕设和企业适用springboot企业管理类及智慧电力管理平台源码+论文+视频.zip
- 毕设和企业适用springboot企业管理类及智能化系统源码+论文+视频.zip
- 毕设和企业适用springboot企业管理类及自动化控制系统源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及活动管理平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及机器人平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及技术支持平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及健康风险评估平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及跨平台销售系统源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及教育评价系统源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及跨平台协作平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及企业风险监控平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及人工智能客服平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及汽车信息管理平台源码+论文+视频.zip
- 毕设和企业适用springboot企业健康管理平台类及视频编辑平台源码+论文+视频.zip
