

Transfer Learning from Speaker Verification to
Multispeaker Text-To-Speech Synthesis
Ye Jia
∗
Yu Zhang
∗
Ron J. Weiss
∗
Quan Wang Jonathan Shen Fei Ren
Zhifeng Chen Patrick Nguyen Ruoming Pang Ignacio Lopez Moreno Yonghui Wu
Google Inc.
{jiaye,ngyuzh,ronw}@google.com
Abstract
We describe a neural network-based system for text-to-speech (TTS) synthesis that
is able to generate speech audio in the voice of different speakers, including those
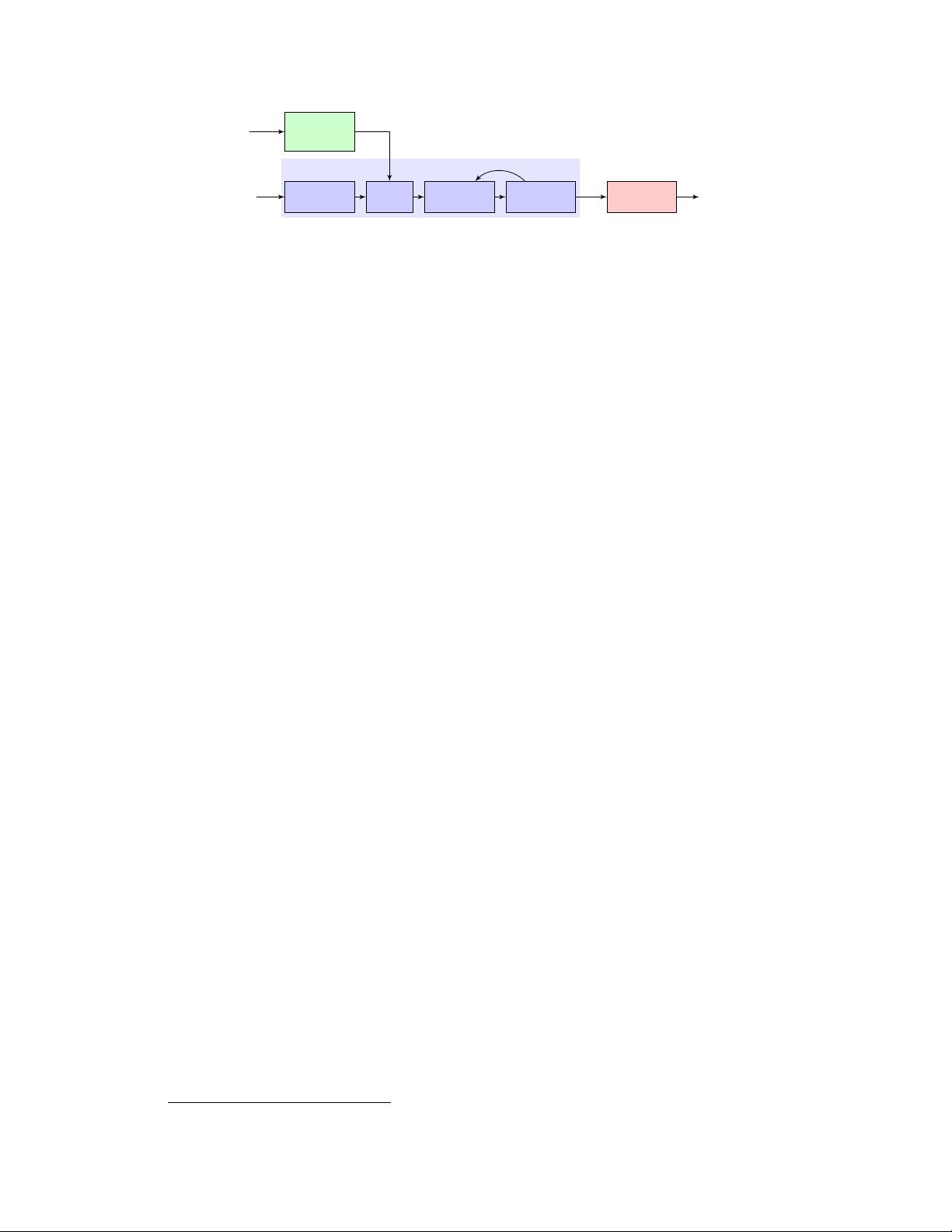
unseen during training. Our system consists of three independently trained compo-
nents: (1) a speaker encoder network, trained on a speaker verification task using an
independent dataset of noisy speech without transcripts from thousands of speakers,
to generate a fixed-dimensional embedding vector from only seconds of reference
speech from a target speaker; (2) a sequence-to-sequence synthesis network based
on Tacotron 2 that generates a mel spectrogram from text, conditioned on the
speaker embedding; (3) an auto-regressive WaveNet-based vocoder network that
converts the mel spectrogram into time domain waveform samples. We demonstrate
that the proposed model is able to transfer the knowledge of speaker variability
learned by the discriminatively-trained speaker encoder to the multispeaker TTS
task, and is able to synthesize natural speech from speakers unseen during training.
We quantify the importance of training the speaker encoder on a large and diverse
speaker set in order to obtain the best generalization performance. Finally, we show
that randomly sampled speaker embeddings can be used to synthesize speech in
the voice of novel speakers dissimilar from those used in training, indicating that
the model has learned a high quality speaker representation.
1 Introduction
The goal of this work is to build a TTS system which can generate natural speech for a variety of
speakers in a data efficient manner. We specifically address a zero-shot learning setting, where a
few seconds of untranscribed reference audio from a target speaker is used to synthesize new speech
in that speaker’s voice, without updating any model parameters. Such systems have accessibility
applications, such as restoring the ability to communicate naturally to users who have lost their
voice and are therefore unable to provide many new training examples. They could also enable
new applications, such as transferring a voice across languages for more natural speech-to-speech
translation, or generating realistic speech from text in low resource settings. However, it is also
important to note the potential for misuse of this technology, for example impersonating someone’s
voice without their consent. In order to address safety concerns consistent with principles such as [
1
],
we verify that voices generated by the proposed model can easily be distinguished from real voices.
Synthesizing natural speech requires training on a large number of high quality speech-transcript
pairs, and supporting many speakers usually uses tens of minutes of training data per speaker [
8
].
Recording a large amount of high quality data for many speakers is impractical. Our approach is to
decouple speaker modeling from speech synthesis by independently training a speaker-discriminative
embedding network that captures the space of speaker characteristics and training a high quality TTS
∗
Equal contribution.
32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada.
arXiv:1806.04558v4 [cs.CL] 2 Jan 2019

剩余14页未读,继续阅读
资源评论













