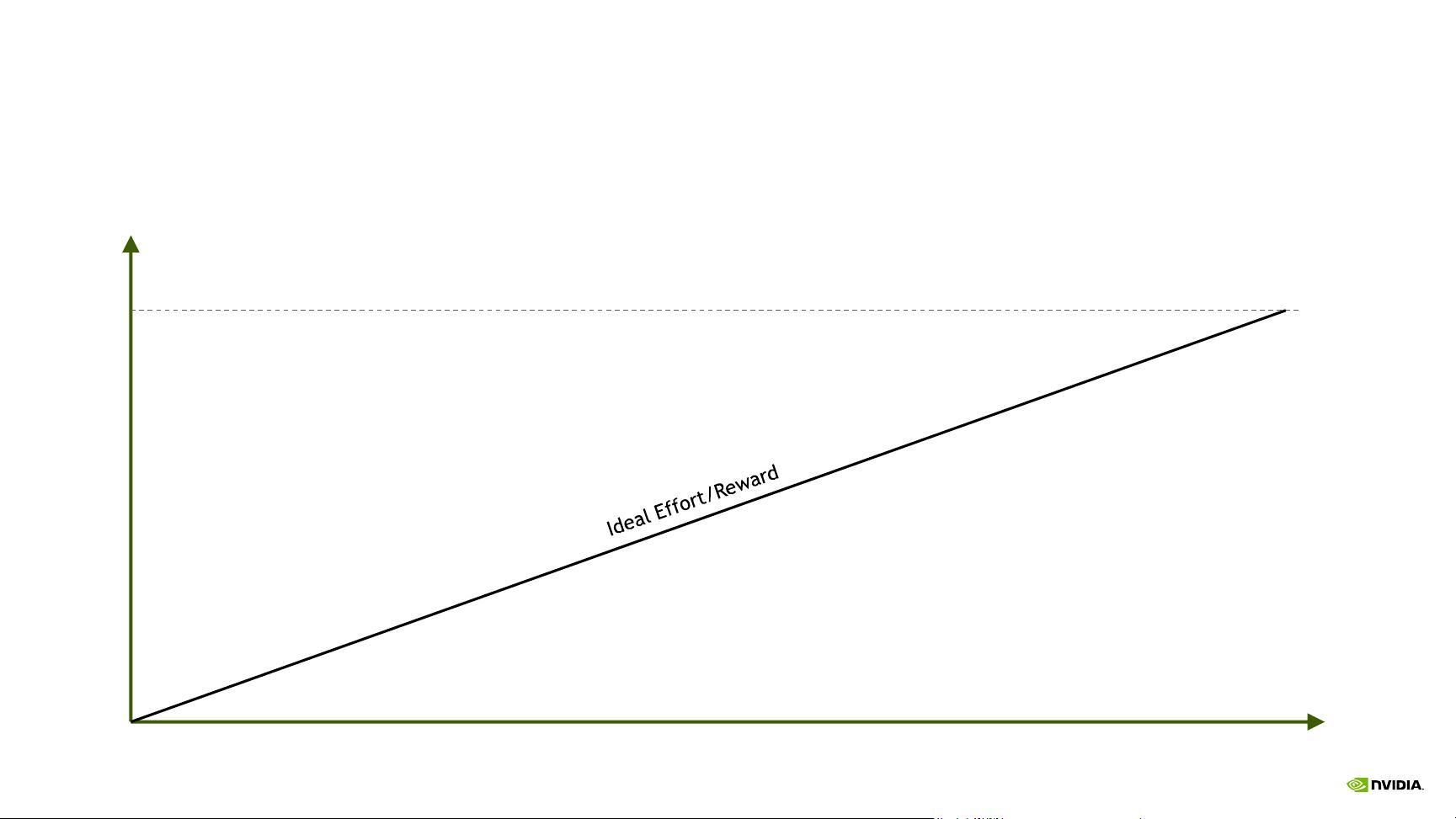
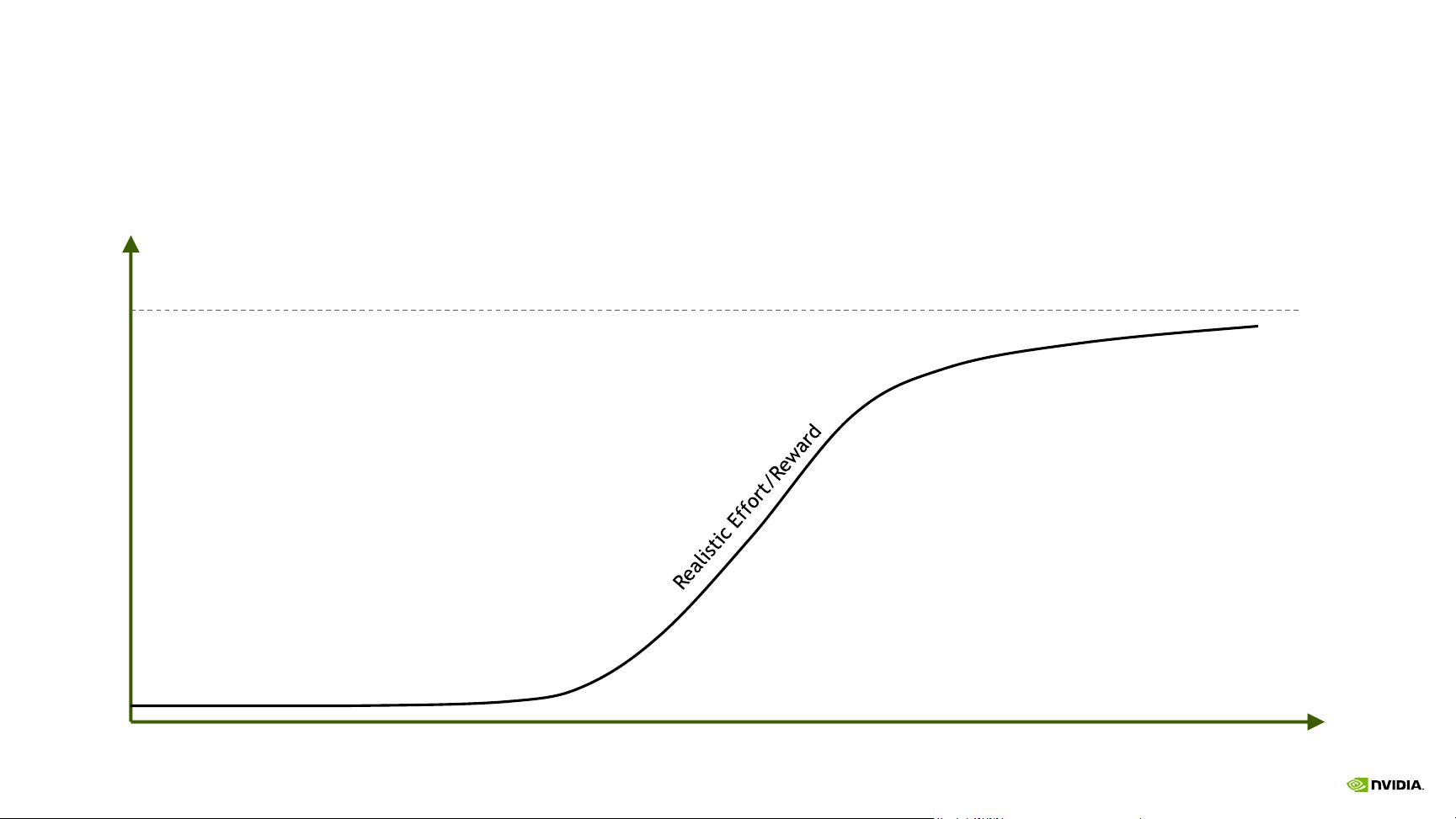
《CUDA优化技巧与技术》是NVIDIA CUDA编程者的一份宝贵资源,由Stephen Jones在GTC 2017大会上提出。这份指南的核心理念是“不要过度努力”,意在提醒开发者,追求性能提升时要避免投入过多而回报有限。CUDA性能优化的目标是在减少计算时间的同时,尽可能接近硬件的峰值性能,避免陷入“失望低谷”,即努力优化却导致性能下降的困境。
性能瓶颈是优化的关键关注点。据统计,内存占据了75%的性能约束,包括CPU到GPU的数据传输、数据对齐、缓存效率、寄存器溢出和分支分歧等。其中,内存访问效率尤为重要,因为CPU、DRAM、GDRAM、L2 Cache和L1 Cache之间的速度差异可达几个数量级,例如,CPU内存带宽大约为150GB/s,而L1 Cache的速度则可高达20,000GB/s。
在优化策略上,文档建议首先使用NVIDIA Visual Profiler这一工具,它能帮助开发者识别性能瓶颈并提供优化建议。CPU和GPU之间的数据移动是优化的重点,由于PCIe总线的带宽限制(16GB/sec),数据传输成为性能的制约因素。因此,需要通过将CPU内存固定(pinning)来提高数据传输效率,这可以通过CUDA的cudaHostAlloc和cudaHostRegister函数实现,以创建映射的、固定的CPU内存,从而利用DMA控制器进行高效的数据复制。
1. **内存优化**:优化内存访问模式,减少内存访问的不连续性和数据碎片,如使用预取和缓存策略,以及利用同步内存(shared memory)和寄存器(registers)降低全局内存访问。
2. **CPU-GPU数据传输**:通过固定CPU内存,可以使用DMA控制器直接进行数据传输,提高数据移动效率。
3. **占用率(Occupancy)和分支分歧**:优化线程块和流式多处理器(SM)的关系,增加有效占用率,同时避免分支指令导致的计算单元利用率降低。
4. **延迟优化**:减少等待时间和空闲周期,例如,通过预计算、减少同步点和利用异步计算来隐藏延迟。
5. **奇怪但有效的技巧**:文档还提到了一些可能不常见的优化方法,这些方法可能带来显著的性能提升,但需要谨慎尝试,以免引入新的问题。
在进行CUDA程序优化时,开发者应遵循一种结构化的方法,从明显的性能问题开始,逐步深入到更复杂的优化技术,同时保持对性能指标的持续监控,以确保优化措施真正带来了性能提升,而不是相反。