操作步骤必读
一、项目导入
1、准备工作
这里以《图像去雾》课题为例。把压缩包解压成文件夹,确
保所有文件都在一个文件夹内,把文件夹放入到桌面,无需放入
MATLAB 默认文件夹。
图:压缩包解压成文件夹
2、运行方式
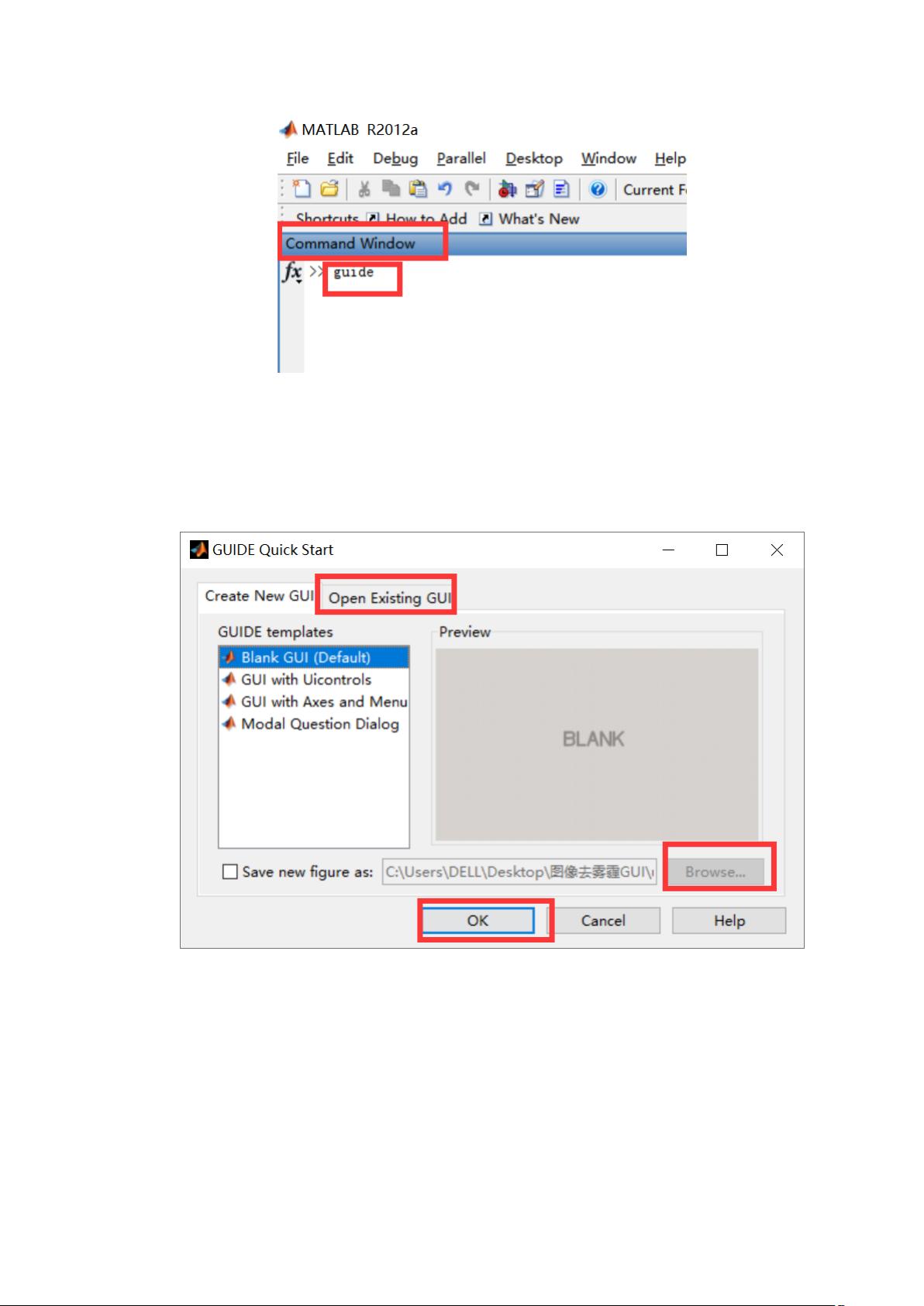
(1)、打开 MATLAB 软件,在命令行窗口,即有双肩号>>的
地方,也就是光标一直闪动的地方,输入 guide(小写字母),
按回车键;
 基于平台的口罩识别检测.zip (13个子文件)
基于平台的口罩识别检测.zip (13个子文件)  基于平台的口罩识别检测
基于平台的口罩识别检测  p.mat 765KB finddomain.m 1KB
p.mat 765KB finddomain.m 1KB 口罩黄2.jpg 31KB 警报.wav 78KB 穿戴.wav 66KB mask.m 13KB
口罩黄2.jpg 31KB 警报.wav 78KB 穿戴.wav 66KB mask.m 13KB 操作必读指南.doc 707KB 蓝1.jpg 43KB 红1.jpg 2KB mask.fig 13KB 红2.jpg 19KB Unt.p 198B
操作必读指南.doc 707KB 蓝1.jpg 43KB 红1.jpg 2KB mask.fig 13KB 红2.jpg 19KB Unt.p 198B 阶段任务.txt 571B
阶段任务.txt 571B