使用 ADS1.2 进行嵌入式软件开发(下)
上期主要介绍了基于 ARM 的嵌入式系统软件开发中,怎样来对必要的 C 库函数进
行移植和重定向,以及如何根据不同的目标存储器系统进行程序编译和连接设
置。本期介绍程序中的存储器分配和如何根据设置正确初始化系统。
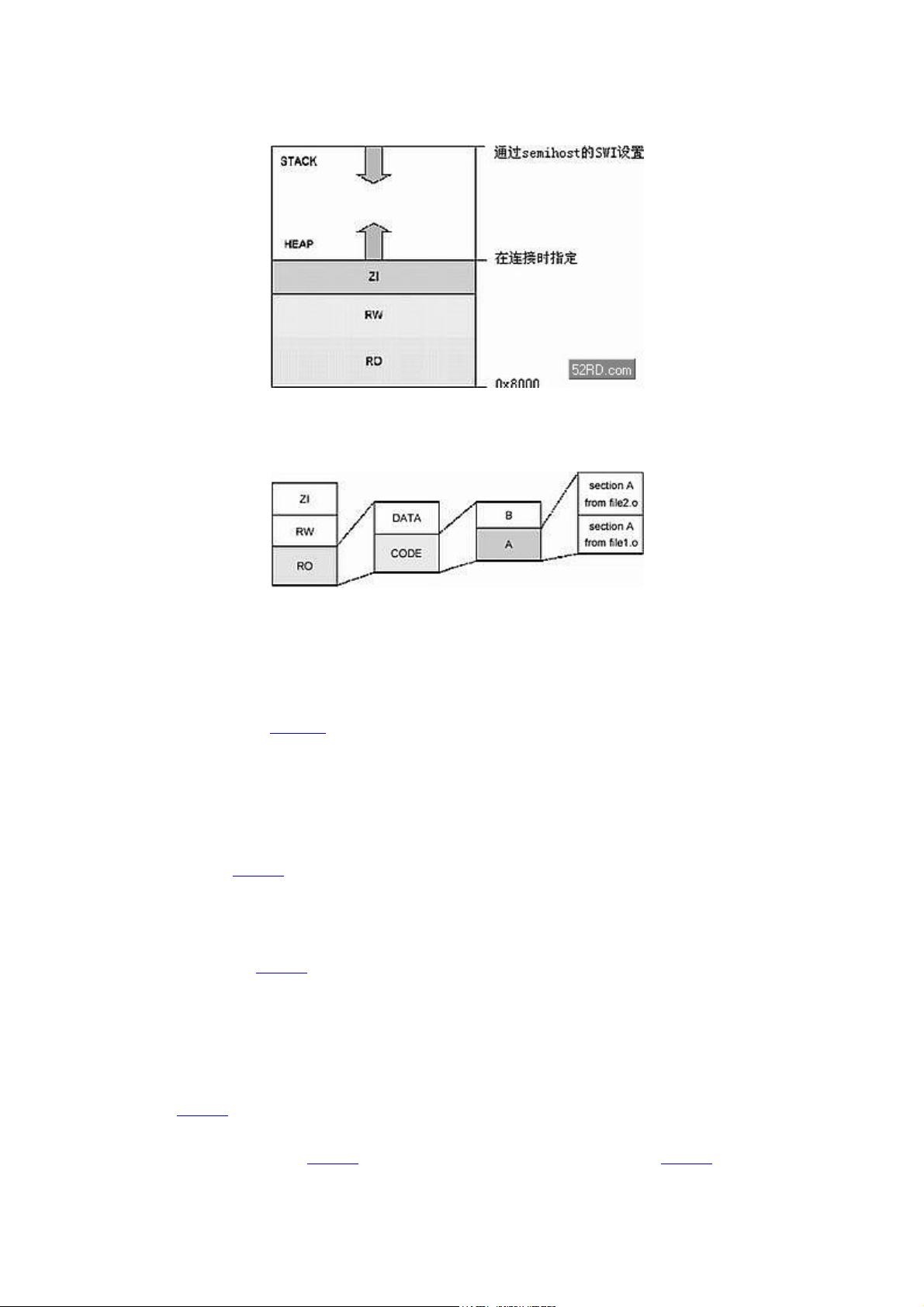
放置堆栈和 heap
Scatterloading 机制提供了一种指定代码和静态数据布局的方法。下面介
绍如何放置应用程序的堆栈和 heap。
* _user_initial_stackheap 重定向
应用程序的堆栈和 heap 是在 C 库函数初始化过程中建立起来的。可以通过
重定向对应的子程序来改变堆栈和 heap 的位置,在 ADS 的库函数中,即
_user_initial_stackheap()函数。
_user_initial_stackheap()可以用 C 或汇编来实现,它必须返回如下参数:
r0:heap 基地址;
r1:堆栈基地址;
r2:heap 长度限制值(需要的话);
r3:堆栈长度限制值。
当用户使用分散装载功能的时候,必须重调用_user_initial_stackheap(),
否则连接器会报错:
Error: L6218E: Undefined symbol Image$$ZI$$Limit (referred from
sys_stackheap.o)
* 存储器模型
ADS 提供了两种实时存储器模型。缺省时为 one-region,应用 程序的堆栈
和 heap 位于同一个存储器区块,使用的时候相向生长,当在 heap 区分配一块存
储器空间时需要检查堆栈指针。另一种情况是堆栈和 heap 使用 两块独立的存储
器区域。对于速度特别快的 RAM,可选择只用来作堆栈使用。为了使用这种
two-region 模型,用户需要导入符号 use_two_region_memory,heap 使用需要
检查 heap 的长度限制值。
对这两种模型来说,缺省情况下对堆栈的生长都不进行检查。用户可以在程
序编译时使用 -apcs/swst 编译器选项来进行软件堆栈检查。如果使用
two-region 模型,必须得在执行_user_initial_stackheap 时指定一个堆栈限制
值。