2023/6/28 16:46
大幅超越DALL·E 2和Imagen,斯坦福发布RA-CM3模型,融合检索与生成
https://mp.weixin.qq.com/s/oKWpRk9Gvmvtp7BjAShdCw
1/9
大幅超越DALL·E 2和Imagen,斯坦福发布RA-CM3模型,融合检索
与生成
文 | QvQ
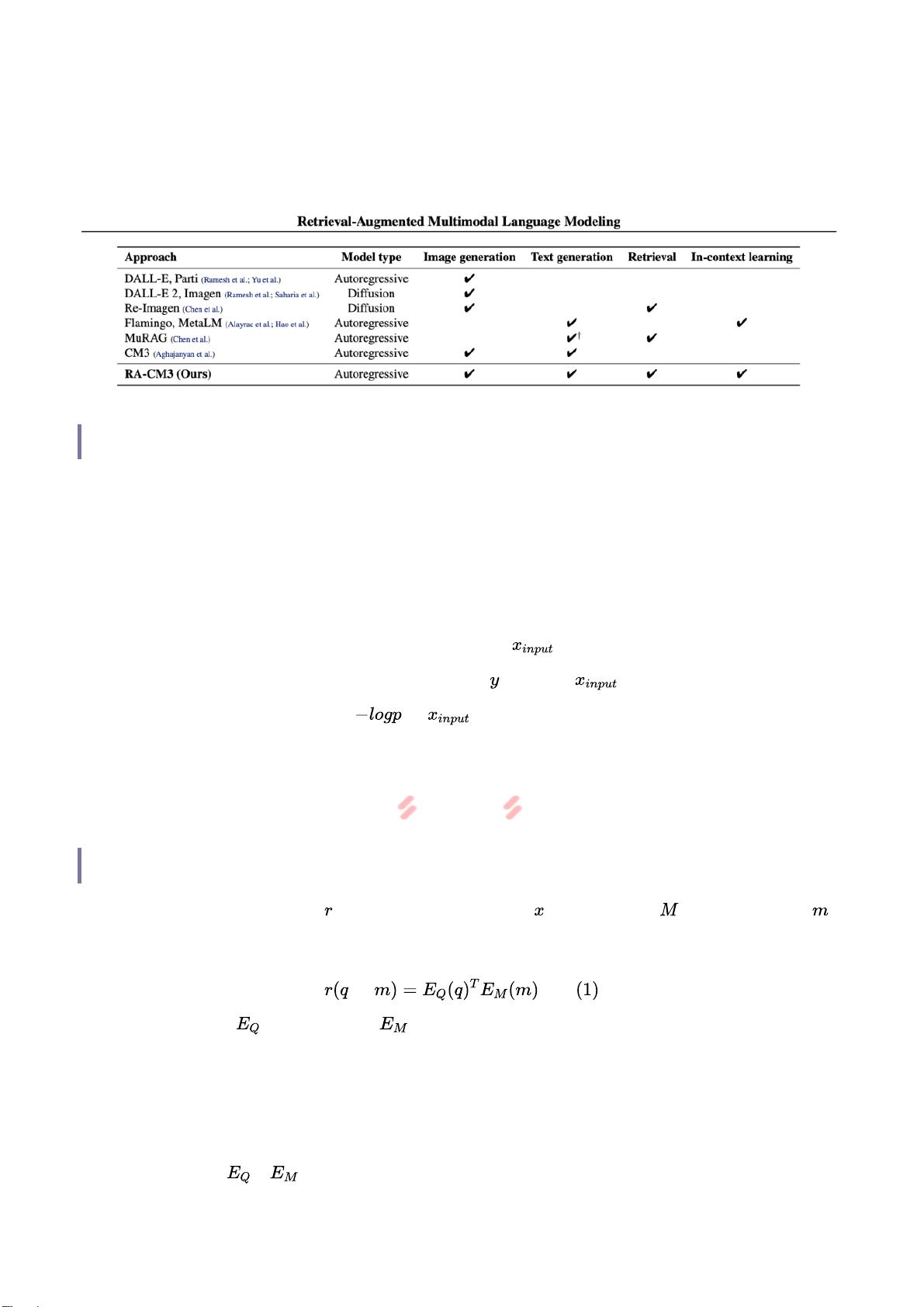
最近,DALL-E和CM3等模型在多模态任务尤其是图文理解上表现出色。然而,这些模型似乎
需要将所有学到的知识存储都存储在模型参数中,这就不得不需要越来越大的模型和训练数据
来获取更多的知识,俨然将bigger andbett er绑定在了一起。
那既然如此,哪还需要算法工程师?全体转行数据标注工程师和芯片制造工程师岂不是可以早
日实现AI自由?
这不,斯坦福和Meta AI一众学者为了证明算法工程师“不可取代”的地位,提出了一种检索增
强的 多模态 模型: 实 现 了 通 过 可 缩 放 和 模 块 化 的 方 式 集 成 知 识 , 从 而 使 基 础 多 模 态 模 型
QvQ 2022-12-12 11:39 发表于北京
原创
夕小瑶科技说