显存不够,如何训练⼤型神经⽹络?
3⽉3⽇
以下⽂章来源于NLPCAB ,作者李如
⼣⼩瑶的卖萌屋
NLPCAB
⼀些⾃然语⾔处理的学习经验和Paper解读
⼀只⼩狐狸带你解锁 炼丹术&NLP 秘籍
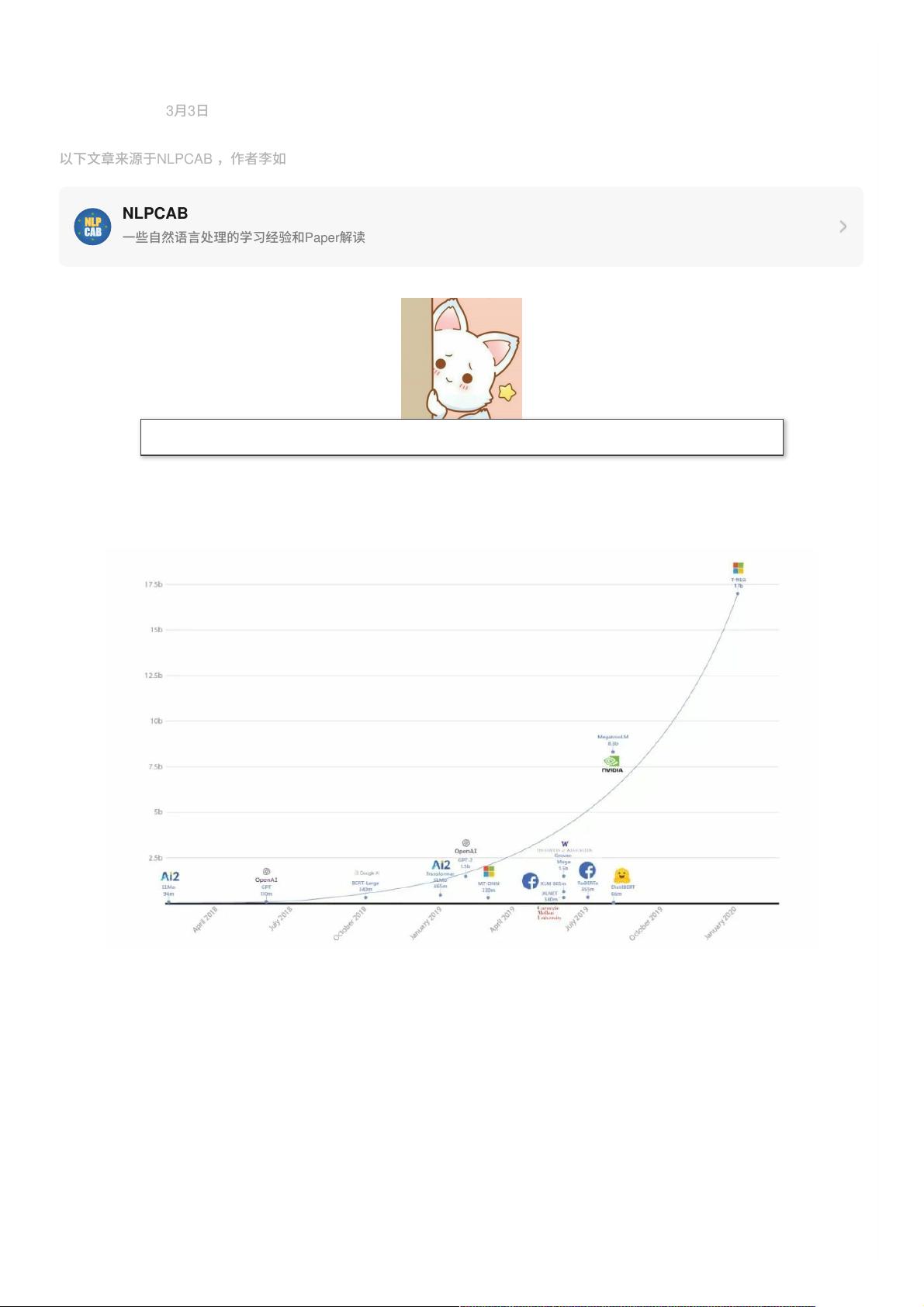
前阵⼦微软开源了DeepSpeed训练框架,从测试效果来看有10倍的速度提升,⽽且对内存进⾏了各种优化,最⼤可以训练
100B(illion)参数的模型。同时发布了这个框架训练出的17B模型 Turing-NLG,处于⽬前壕赛事的顶端。
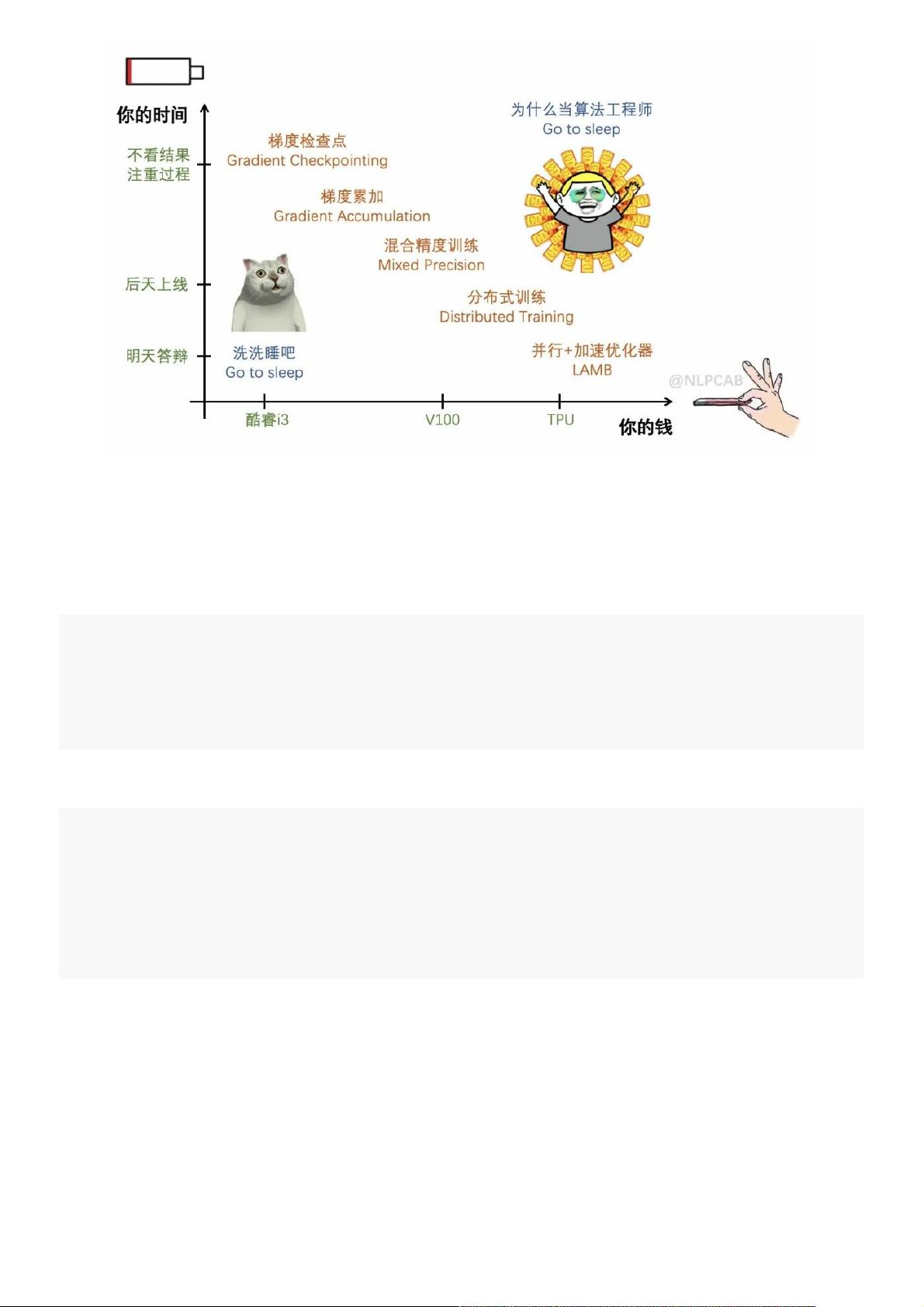
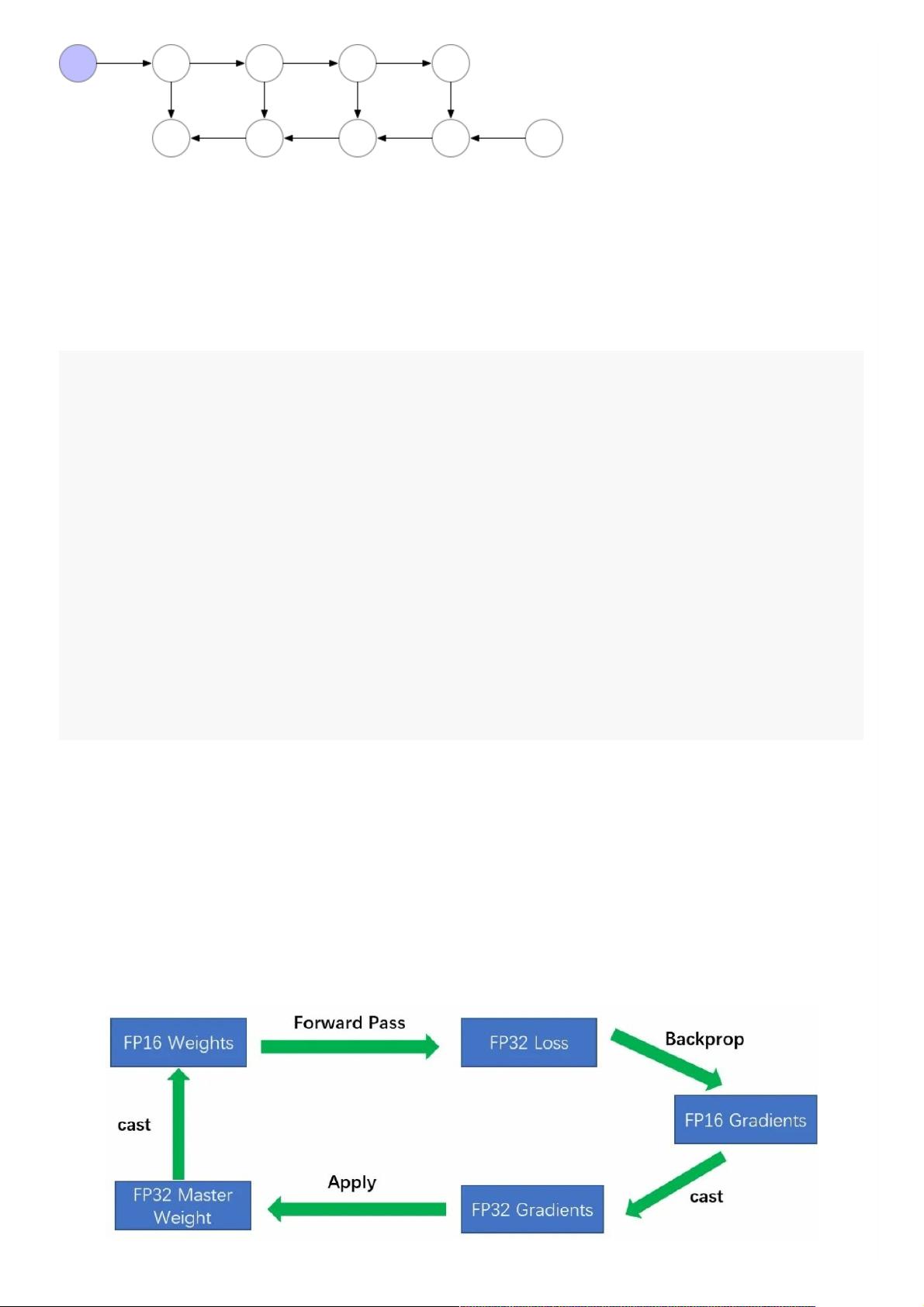
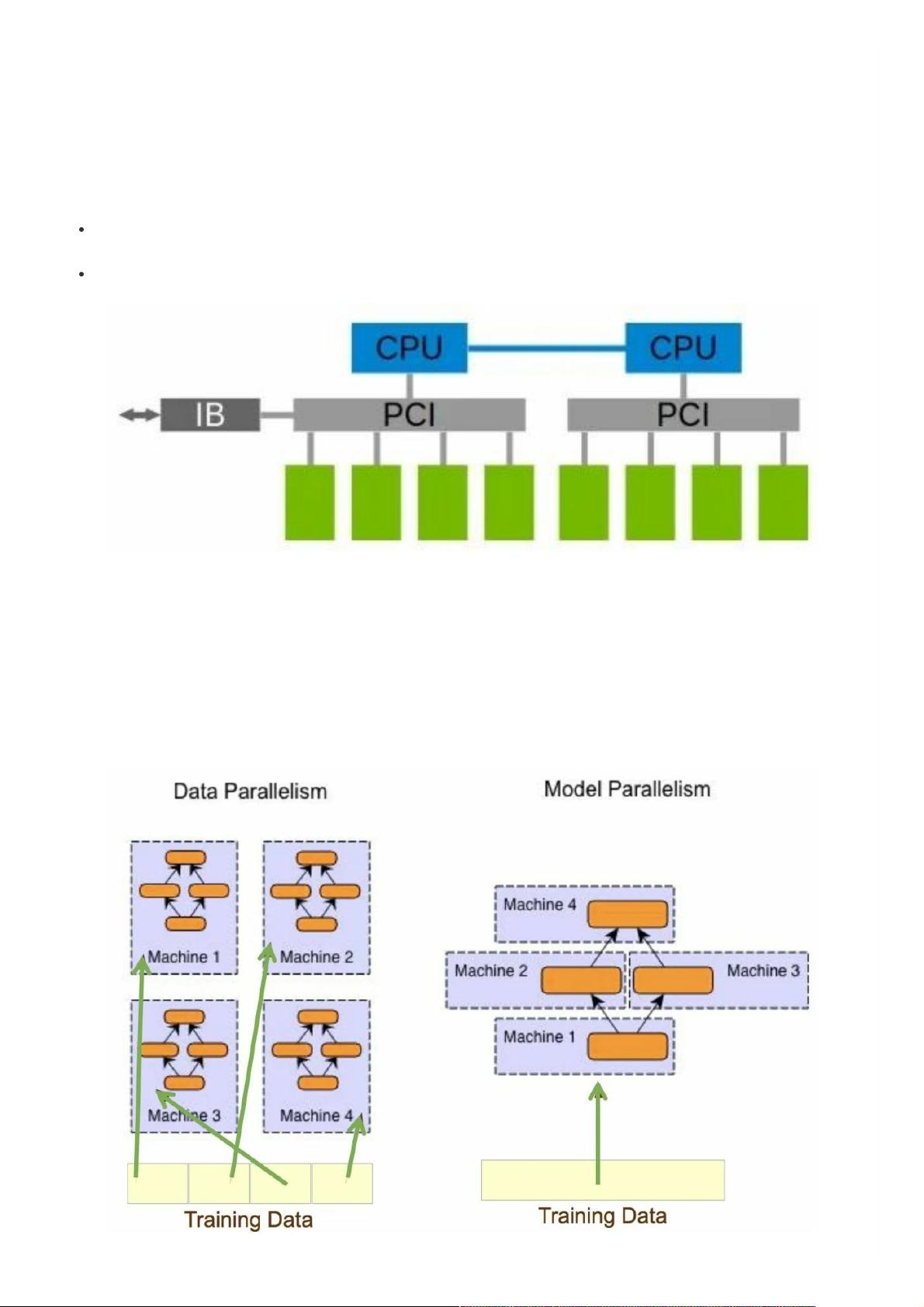
训100B的模型就先别想了(狗头),先把110M的BERT-base训好上线吧。本⽂主要介绍模型训练中速度和内存的
优化策略,针对以下⼏种情况:
1. 我明天就要答辩了,今天必须把这⼗个实验跑完
2. 我的模型有些⼤,好不容易放到⼀张卡上,训完⼀亿样本之前我就可以领N+1了
3. 我想出了⼀个绝妙的T6模型,却加载不进12GB的卡⾥,⼜拿不到今年的best paper了
(以上纯属虚构,如有雷同请赶紧看下⽂)
现实总是残酷的,其实限制⼤模型训练只有两个因素:时间和空间(=GPU=钱),根据不同情况可以使⽤的⽅案⼤致
如下: