


强化学习扫盲贴:从Q-learning到DQN
2019-09-28⼣⼩瑶的卖萌屋
本⽂转载⾃知乎专栏「机器学习笔记」,原⽂作者「余帅」,链接
https://zhuanlan.zhihu.com/p/35882937
1 本⽂学习⽬标
1. 复习Q-Learning;
2. 理解什么是值函数近似(Function Approximation);
3. 理解什么是DQN,弄清它和Q-Learning的区别是什么。
2 ⽤Q-Learning解决经典迷宫问题
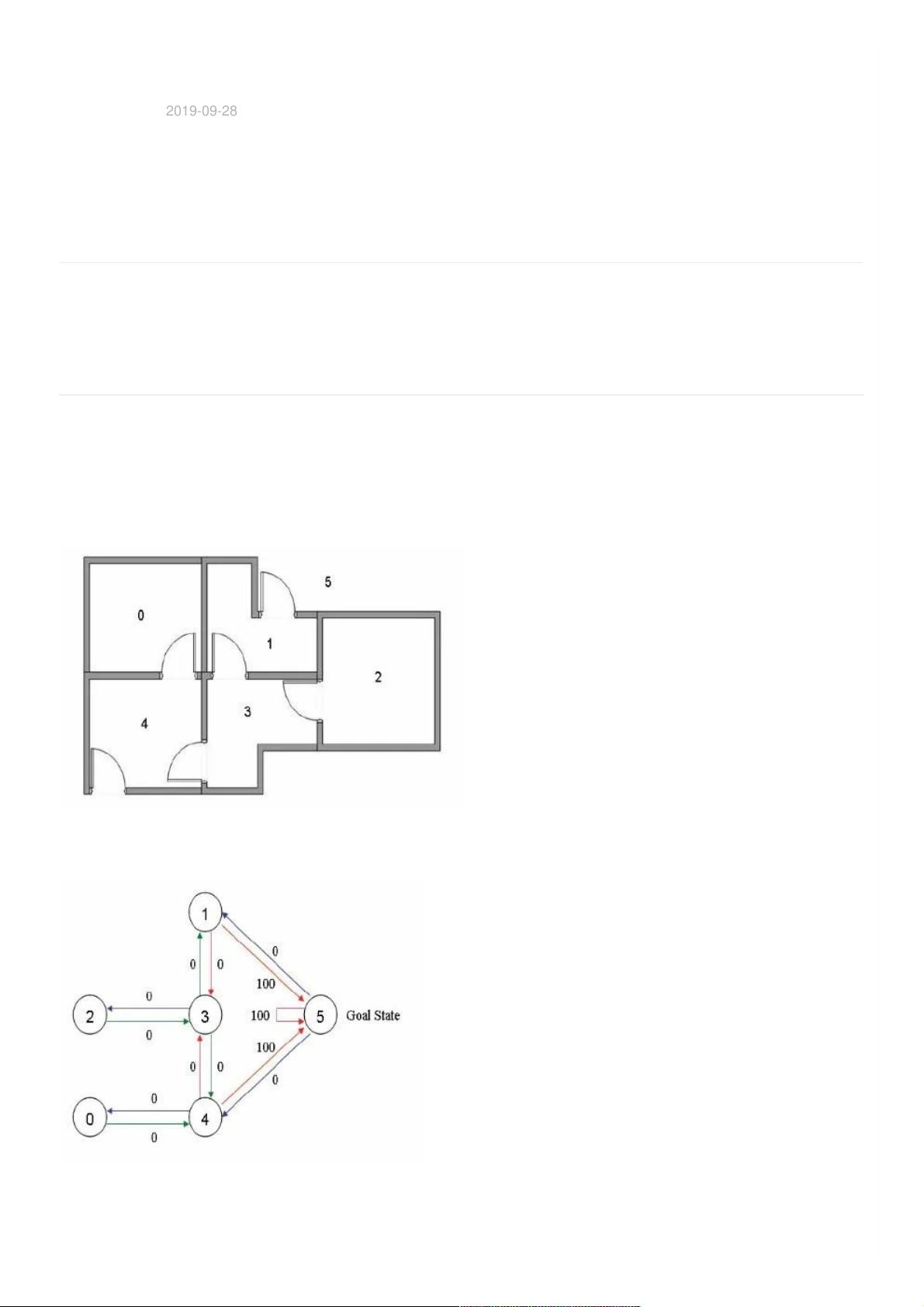
现有⼀个5房间的房⼦,如图1所⽰,房间与房间之间通过⻔连接,编号0到4,5号是房⼦外边,即我们的终点。我们将agent随机放在
任⼀房间内,每打开⼀个房⻔返回⼀个reward。图2为房间之间的抽象关系图,箭头表⽰agent可以从该房间转移到与之相连的房
间,箭头上的数字代表reward值。
图1 房⼦原型图
图2 抽象关系图
根据此关系,可以得到reward矩阵为














