




先分享⼀张在佛罗伦萨的⼈⽂摄影~
今年去意呆的时候特别热,每天都是⽩晃晃的⼤太阳,所以我总喜欢躲到附近的教堂,那⾥是“免费的避暑胜地”。
“诸圣教堂”离我住处很近,当时遇到神⽗祷告,他还缓缓唱了⾸歌,第⼀次觉得美声如此动⼈,怪不得意呆⼈那么热爱歌剧,连我这种⾳乐⼩⽩都
被感染到了~
喜欢“诸圣教堂”的另⼀个原因是这⾥埋葬着基尔兰达约、波提切利和他爱慕的⼥神西蒙内塔。⽣前“⼩桶”因她创作了《维纳斯的诞⽣》,离开⼈世
他⼜得偿所愿和⼼爱之⼈共眠。情深如此,我能想到的中国式浪漫⼤概也只有“庭有枇杷树,吾妻死之年所⼿植也,今已亭亭如盖矣”相⽐了..
AI sharing
之前介绍过Seq2Seq+SoftAttention这种序列模型实现机器翻译,那么抛弃RNN,全⾯拥抱attention的
transformer⼜是如何实现的呢。
本篇介绍Transformer的原理及Pytorch实现,包括⼀些细枝末节的trick和个⼈感悟,这些都是在调试代码过
程中深切领会的。⽹上查了很多⽂章,⼤部分基于哈佛那⽚论⽂注释,数据集来源于tochtext⾃带的英-德翻
译,但是本篇为了和上⾯摄影分享对应以及灵活的⾃定义数据集,采⽤意⼤利-英语翻译。
CONTENT
1、Transformer简介
2、模型概览
3、数据加载及预处理
3.1原始数据构造DataFrame
3.2⾃定义Dataset
3.3构建字典
3.4Iterator实现动态批量化
3.5⽣成mask
4、Embedding层
4.1普通Embedding
4.2位置PositionalEncoding
4.3层归⼀化
5、SubLayer⼦层组成
5.1MulHeadAttention(self+context attention)
self attention
attention score:scaled dot product
multi head
5.2Position-wise Feed-forward前馈传播
5.3Residual Connection残差连接
6、Encoder组合
7、Decoder组合
8、损失函数和优化器
8.1损失函数实现标签平滑
8.2优化器实现动态学习率
9、模型训练Train
10、测试⽣成
11、注意⼒分布可视化
12、数学原理解释transformer和rnn本质区别
【资料索取】

公众号回复:Transformer
可获取完整代码
1. Transfomer简介
《Attention Is All Your Need》 是⼀篇Google提出全⾯使⽤self-Attention的论⽂。这篇论⽂中提出⼀个全新的模型,叫 Transformer,抛弃
了以往深度学习任务⾥⾯使⽤到的 CNN 和 RNN。⽬前⼤热的Bert就是基于Transformer构建的,这个模型⼴泛应⽤于NLP领域,例如机器
翻译,问答系统,⽂本摘要和语⾳识别等等⽅向。
众所周知RNN虽然模型设计⼩巧精妙,但是其线性序列模型决定了⽆法实现并⾏,从两个任意输⼊和输出位置获取依赖关系都需要⼤量的
运算,运算量严重受到距离的制约;⽽且距离不但影响性能也影响效果,随着记忆时序的拉⻓,记忆削弱,导致学习能⼒削弱。
为了抛弃RNN step by step线性时序,Transformer使⽤了可以biself-attention,不依靠顺序和距离就能获得两个位置(实质是key和
value)的依赖关系(hidden)。这种计算成本减少到⼀个固定的运算量,虽然注意⼒加权会减少有效的resolution表征⼒,但是使⽤多
头multi-head attention可以弥补平均注意⼒加权带来的损失。
⾃注意⼒是⼀种关注⾃⾝序列不同位置的注意⼒机制,能计算序列的表征representation。
和之前分享的Seq2Seq+SoftAttention相⽐,Transformer不仅关注encoder和decoder之间的attention,也关注encoder和decoder各⾃内部
⾃⼰的attention。也就是说前者的hidden是靠lstm来实现,⽽transformer的encoder或者decoder的hidden是靠self-attention来实现。
2. 模型概览
Transformer结构和Seq2Seq模型是⼀样的,也采⽤了Encoder-Decoder结构,但Transformer更复杂。
2.1宏观组成
Encoder由6个EncoderLayer构成,Decoder由6个DecoderLayer构成:
对应的代码逻辑如下,make_model包含EncoderDecoder模块,可以看到N=6表⽰Encoder和Decoder的⼦层数量,d_ff是前馈神经⽹络的
中间隐层维度,h=代表的是注意⼒层的头数。
后⾯还规定了初始化的策略,如果每层参数维度⼤于1,那么初始化服从均匀分布init.xavier_uniform
def make_model(src_vocab , tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
return model
EncoderDecoder⾥⾯除了Encoder和Decoder两个模块,还包含embed和generator。Embed层是对对输⼊进⾏初始化,词嵌⼊包含普通的
Embeddings和位置标记PositionEncoding;Generator作⽤是对输出进⾏full linear+softmax
其中可以看到Decoder输⼊的memory就是来⾃前⾯Encoder的输出,memory会分别喂⼊Decoder的6个⼦层。
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
2.2内部结构
上⾯是Transformer宏观上的结构,那Encoder和Decoder内部都有哪些不同于Seq2Seq的技术细节呢:
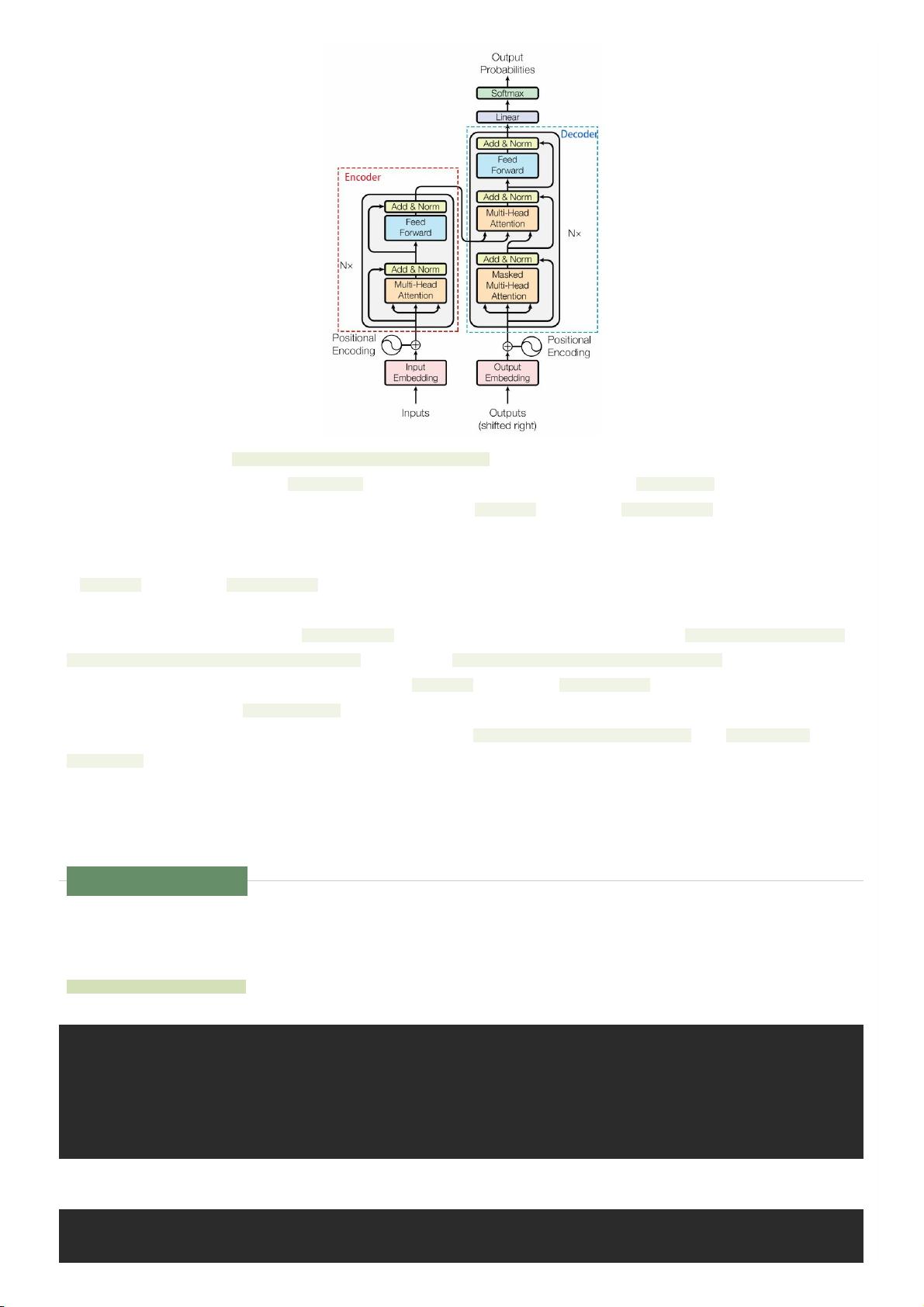
(1)Encoder的输⼊序列经过word embedding和positional encoding后,输⼊到encoder。
(2)在EncoderLayer⾥⾯先经过8个头的self-attention模块处理source序列⾃⾝。这个模块⽬的是求得序列的hidden,利⽤的就是⾃注意⼒
机制,⽽⾮之前RNN需要step by step算出每个hidden。然后经过⼀些 norm和drop基本处理,再使⽤残差连接模块,⽬的是为了避免梯度
消失问题。(后⾯代码实现和上图在实现顺序上有⼀点出⼊)
(3)在EncoderLayer⾥⾯再进⼊Feed-Forward前馈神经⽹络,实际上就是做了两次dense,linear2(activation(linear1))。然后同上经过⼀
些norm和drop基本处理,再使⽤残差连接模块。
(4)Decoder的输⼊序列处理⽅式同上
(5)在DecoderLayer⾥⾯也要经过8个头的self-attentention模块处理target序列⾃⾝。不同于Encoder层,这⾥只需要关注输⼊时刻t之前的
部分,⽬的是为了符合decoder看不到未来信息的逻辑,所以这⾥的mask是融合了pad-mask和sequence-mask两种。同Encoder,这个模
块⽬的也是为了求得target序列⾃⾝的hidden,然后经过⼀些norm和drop基本处理,再使⽤残差连接模块。
(6)在DecoderLayer⾥⾯再进⼊src-attention模块,这个模块也是相⽐Encoder增加的注意⼒层。其实注意⼒结构都是相似的,只是
(query,key,value)不同,对于self-attention这三个值都是⼀致的,对于src-attention,query来⾃decoder的hidden,key和value来⾃
encoder的hidden
(7)在DecoderLayer⾥⾯最后进⼊Feed-Forward前馈神经⽹络,同上。
介绍完Transformer整体结构,下⾯从数据集处理到各层代码实现细节进⾏详细说明~
3. 数据加载及预处理
GPU环境使⽤Google Colab 单核16g,数据集eng-ita.txt,普通的英意翻译对的⽂本数据。数据集预处理使⽤的是torchtext+spacy⼯具,他
使⽤的整体思路是构造Dataset,字典、Iterator实现批量化、对矩阵进⾏mask pad。
数据预处理⾮常重要,这⾥涉及很多提⾼训练性能的trick。下⾯具体看⼀下如何使⽤⾃定义数据集来完成这些预处理步骤。
3.1原始数据构造DataFrame
先加载⽂本,并将source和target两列转换为两个独⽴的list:
corpus = open('./dataset/%s-%s.txt' % ('eng', 'ita') , 'r', encoding='utf-8').readlines()
random.shuffle(corpus)
def prepare_data(lang1_name, lang2_name, reverse=False):
print("Reading lines...")
input_lang, output_lang = [], [] # raw
for parallel in corpus:
so,ta = parallel[:-1].split('\t') #⼀⾏实际是英⽂和法⽂对⼉ ⽤tab来分割
if so.strip() == "" or ta.strip() == "":
continue
input_lang.append(so)
output_lang.append(ta)
if reverse:
return output_lang,input_lang
else:
return input_lang,output_lang
input_lang, output_lang = prepare_data('eng', 'ita', True)
因为torchtext的dataset的输⼊需要DataFrame格式,所以这⾥先利⽤上⾯的source和target list构造DataFrame。训练集、验证集、测试集
按照实际要求进⾏划分:
train_list=corpus[:-3756]
valid_list=corpus[-1622:]
test_list=corpus[-3756:-1622]
c_train={'src':input_lang[:-3756],'trg':output_lang[:-3756]}
train_df=pd.DataFrame(c_train)
c_valid={'src':input_lang[-1622:],'trg':output_lang[-1622:]}

valid_df=pd.DataFrame(c_valid)
c_test={'src':input_lang[-3756:-1622],'trg':output_lang[-3756:-1622]}
test_df=pd.DataFrame(c_test)
3.2构造Dataset
这⾥主要包含分词、指定起⽌符和补全字符以及限制序列最⼤⻓度。
因为torchtext的Dataset是由example组成,example的含义就是⼀条翻译对记录。
# 分词
spacy_it = spacy.load('it')
spacy_en = spacy.load('en')
def tokenize_it(text):
return [tok.text for tok in spacy_it.tokenizer(text)]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
# 定义FIELD配置信息
# 主要包含以下数据预处理的配置信息,⽐如指定分词⽅法,是否转成⼩写,起始字符,结束字符,补全字符以及词典等等
BOS_WORD = '<s>'
EOS_WORD = '</s>'
BLANK_WORD = "<blank>"
SRC = data.Field(tokenize=tokenize_it, pad_token=BLANK_WORD)
TGT = data.Field(tokenize=tokenize_en, init_token=BOS_WORD, eos_token=EOS_WORD, pad_token=BLANK_WORD)
# get_dataset构造并返回Dataset所需的examples和fields
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [('id', None), ('src', text_field), ('trg', label_field)]
examples = []
if test:
for text in tqdm(csv_data['src']): # tqdm的作⽤是添加进度条
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['src'], csv_data['trg'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields
# 得到构建Dataset所需的examples和fields
train_examples, train_fields = get_dataset(train_df, SRC, TGT)
valid_examples, valid_fields = get_dataset(valid_df, SRC, TGT)
test_examples, test_fields = get_dataset(test_df, SRC, None, True)
构建Dataset数据集
# 构建Dataset数据集
# 这⾥的ita最⼤⻓度也就56
MAX_LEN = 100
train = data.Dataset(train_examples,train_fields,
filter_pred=lambda x: len(vars(x)['src'])<= MAX_LEN and len(vars(x)['trg']) <= MAX_LEN)
valid = data.Dataset(valid_examples, valid_fields,
filter_pred=lambda x: len(vars(x)['src']) <= MAX_LEN and len(vars(x)['trg']) <= MAX_LEN)
test = data.Dataset(test_examples, test_fields,
filter_pred=lambda x: len(vars(x)['src']) <= MAX_LEN)
3.3构造字典
MIN_FREQ = 2 #统计字典时要考虑词频
SRC.build_vocab(train.src , min_freq=MIN_FREQ)
TGT.build_vocab(train.trg, min_freq=MIN_FREQ)
3.4构造Iterator
torchtext的Iterator主要负责把Dataset进⾏批量划分、字符转数字、矩阵pad。
这⾥有个很重要的点就是批量化,本例使⽤的是动态批量化,即每个batch的批⼤⼩是不同的,是以每个batch的token数量作为统⼀划分
标准,也就是说每个batch的token数基本⼀致,这个机制是通过batch_size_fn来实现的,⽐如batch1[16,20],batch2是[8,40],两者的批⼤
⼩是不同的分别是16和8,但是token总数是⼀样的都是320。
采取这种⽅式的特点就是他会把⻓度相同序列的聚集到⼀起,然后进⾏pad,从⽽减少了pad的⽐例,为什么要减少pad呢:
(1)padding是对计算资源的浪费,pad越多训练耗费的时间越⻓。
(2)padding的计算会引⼊噪声,nsformer 中,Lay erNorm 会使 padding 位置的值变为⾮0,这会使每个 padding 都会有梯度,引起不必要
的权重更新。
下图是随意组织pad的batch(paddings)和⻓度相近原则组织pad的batch(baseline)
实现代码部分,可以看到这⾥MyIterator实现了data.Iterator的create_batch()函数,其实真正起作⽤的是⾥⾯的torchtext.data.batch()函数
部分,他的功能是把原始的字符数据按照batch_size_fn算法来进⾏batch并且shuffle,没有做数字化也没有做pad。
class MyIterator(data.Iterator):
def create_batches(self):
if self.train:
def pool(d, random_shuffler):
for p in data.batch(d, self.batch_size * 100):
p_batch = data.batch(
sorted(p, key=self.sort_key),
self.batch_size, self.batch_size_fn)
for b in random_shuffler(list(p_batch)):
yield b
self.batches = pool(self.data(), self.random_shuffler)
else:
self.batches = []
for b in data.batch(self.data(), self.batch_size,self.batch_size_fn):
self.batches.append(sorted(b, key=self.sort_key))
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
那么什么时候对batch进⾏数字化和pad呢,看了下源码,实际这些操作封装在data.Iterator.__iter__的torchtext.data.Batch这个类中。
这⾥还有⼀个问题,BATCH_SIZE这个参数设置多少合适呢,这个参数在这⾥的含义代表每个batch的token总量,我测试了下单核16G的













