


⽂本分类问题不需要ResNet?⼩⼣解析DPCNN设计原理(下)
原创
⼣⼩瑶
2018-04-07⼣⼩瑶的卖萌屋
来⾃专辑
卖萌屋@⾃然语⾔处理
哎呀呀,说好的不拖稿的⼜拖了两天T_T,⼩⼣过⼀阵⼦分享给你们这两天的开⼼事哦。后台催稿调参系列的⼩伙伴们不要急,
下⼀篇就是第⼆篇调参⽂啦。
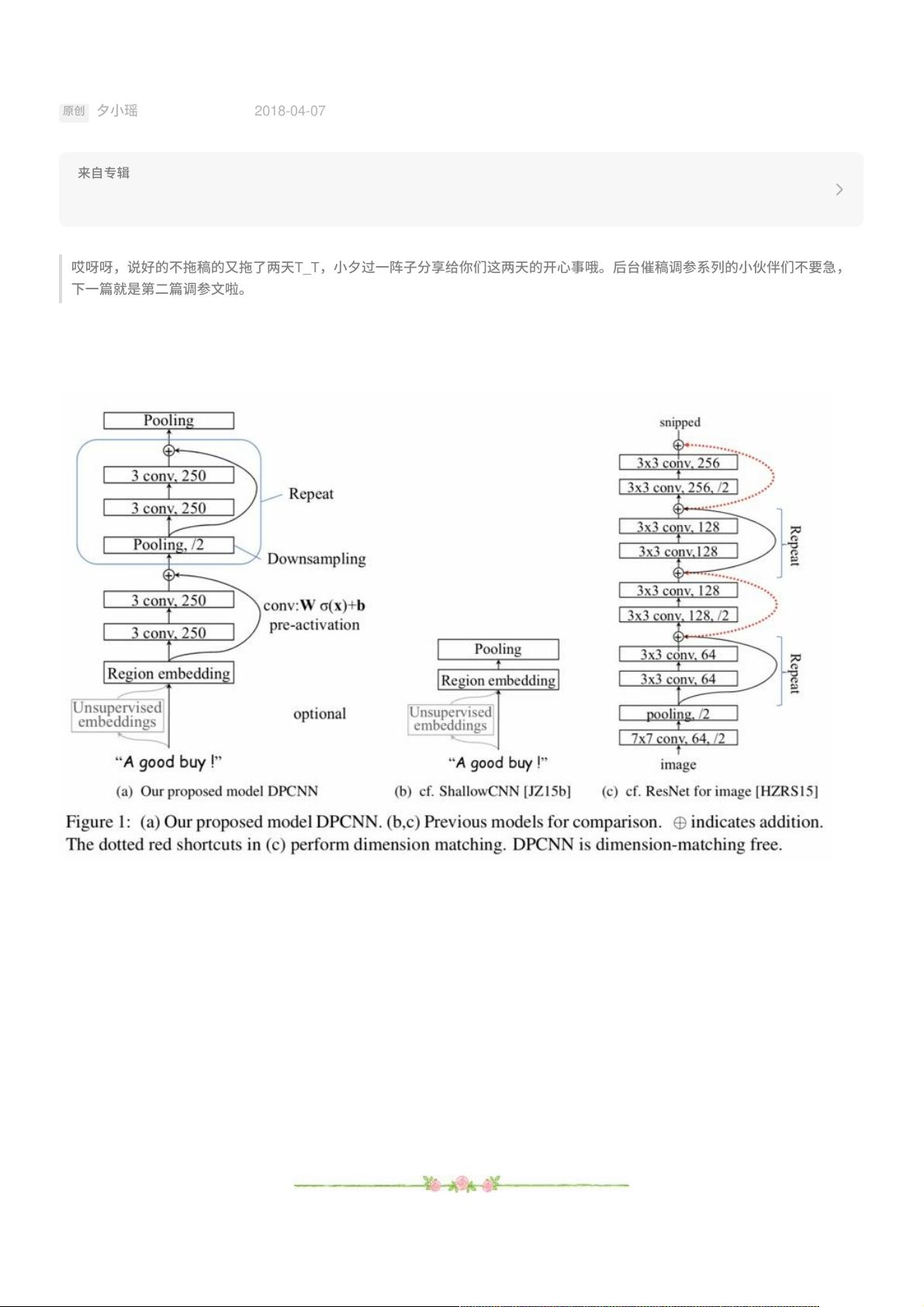
好啦,接着上⼀篇⽂章,直接搬来DPCNN、ShallowCNN、ResNet的对⽐图。
从图中的a和c的对⽐可以看出,DPCNN与ResNet差异还是蛮⼤的。同时DPCNN的底层貌似保持了跟TextCNN⼀样
的结构,这⾥作者将TextCNN的包含多尺⼨卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对
⼀个⽂本区域/⽚段(⽐如3gram)进⾏⼀组卷积操作后⽣成的embedding。
对⼀个3gram进⾏卷积操作时可以有两种选择,⼀种是保留词序,也就是设置⼀组size=3*D的⼆维卷积核对3gram进
⾏卷积(其中D是word embedding维度); 还有⼀种是不保留词序(即使⽤词袋模型),即⾸先对3gram中的3个词
的embedding取均值得到⼀个size=D的向量,然后设置⼀组size=D的⼀维卷积核对该3gram进⾏卷积。显然
TextCNN⾥使⽤的是保留词序的做法,⽽DPCNN使⽤的是词袋模型的做法,DPCNN作者argue前者做法更容易造成
过拟合,后者的性能却跟前者差不多(其实这个跟DAN⽹络(Deep averaging networks)中argue的原理和结论差
不多,有兴趣的可以下拉到下⼀部分的知乎传送⻔中了解⼀下)。
产⽣region embedding后,按照经典的TextCNN的做法的话,就是从每个特征 图中挑选出最有代表性的特征,也就














