










构建信用卡反欺诈预测模型
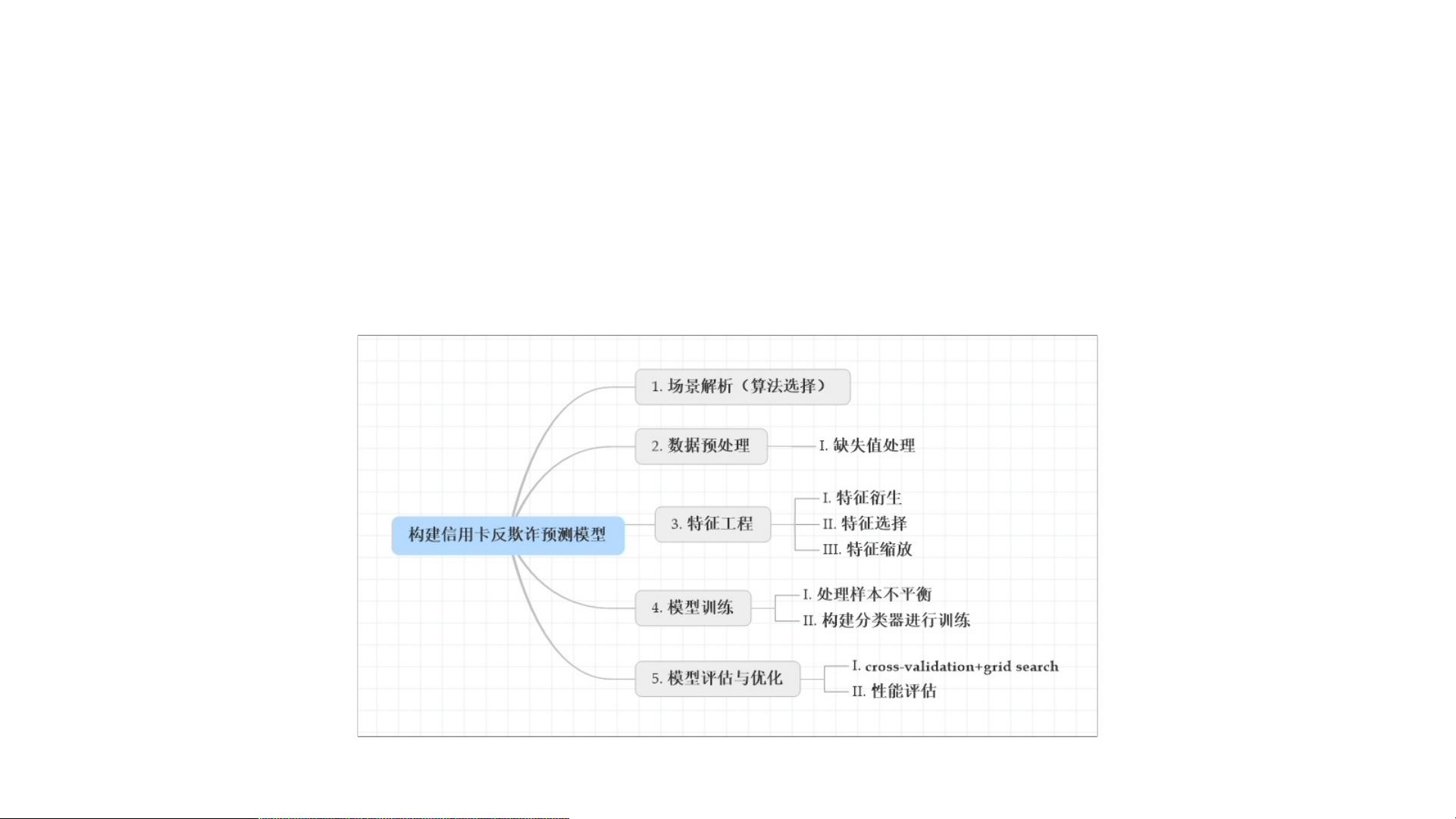
建模思路
• 本项目通过利用信用卡的历史交易数据,进行机器学习,构建信
用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。

项目背景
• 数据集包含由欧洲持卡人于2013年9月使用信用卡进行交的数据。此数据
集显示两天内发生的交易,其中284,807笔交易中有492笔被盗刷。数据
集非常不平衡,被盗刷的类(positive class)占所有交易的0.172%。
• 它只包含28个输入特征变量,特征V1,V2,... V28输入变量是由原始数
据经过PCA主成分分析之后得到的结果变量。不幸的是,由于保密问题,
我们无法提供有关数据的原始功能和更多背景信息。没有用PCA转换的变
量特征是“时间(TIme)”和“量(Amount)”。特征“时间”包含数
据集中每个事务距离第一个事务之间经过的秒数。特征“金额”是交易
金额。特征'class'是预测变量,如果发生被盗刷,则取值1,否则为0。

场景解析(算法选择)
• 1)首先,我们拿到的数据是持卡人两天内的信用卡交易数据,这份数据包含很多维度,要
解决的问题是预测持卡人是否会发生信用卡被盗刷。信用卡持卡人是否会发生被盗刷只有
两种可能,发生被盗刷或不发生被盗刷。又因为这份数据给出了标注(字段Class是目标列
),也就是说它是一个监督学习的场景。于是,我们判定信用卡持卡人是否会发生被盗刷
是一个二元分类问题,意味着可以通过二分类相关的算法来找到具体的解决办法,本项目
选用的算法是逻辑斯蒂回归(Logistic Regression)。
• 2)分析数据:数据是结构化数据 ,不需要做特征抽象。特征V1至V28是经过PCA处理,而
特征Time和Amount的数据规格与其他特征差别较大,需要对其做特征缩放,将特征缩放至
同一个规格。在数据质量方面 ,没有出现乱码或空字符的数据,可以确定字段Class为目
标列,其他列为特征列。
• 3)这份数据是全部已经标注好的数据,可以通过交叉验证的方法对训练集生成的模型进行
评估。70%的数据进行训练,30%的数据进行预测和评估。
• 现对该业务场景进行总结如下:
• 根据历史记录数据学习并对信用卡持卡人是否会发生被盗刷进行预测,二分类监督学习场
景,选择逻辑斯蒂回归(Logistic Regression)算法。
• 数据为结构化数据,不需要做特征抽象,但需要做特征缩放。
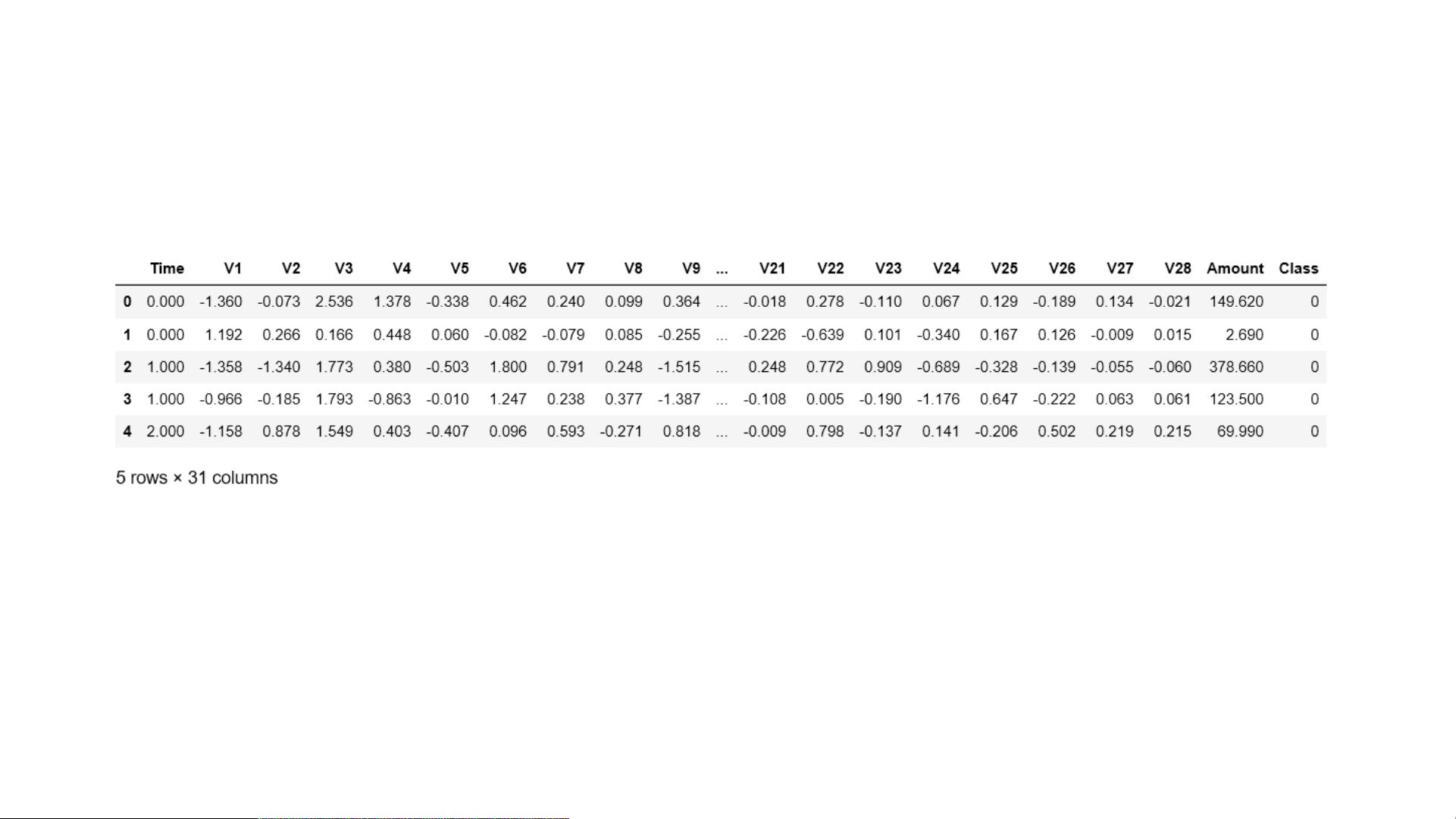
读取数据
从上面可以看出,数据为结构化数据,不需要抽特征转化,但特征Time和Amount的数据规格和其他特
征不一样,需要对其做特征做特征缩放。













