训练 cnn 分类模型
1、优化模型
1)加入归一化:在设置数据变换是加入归一化
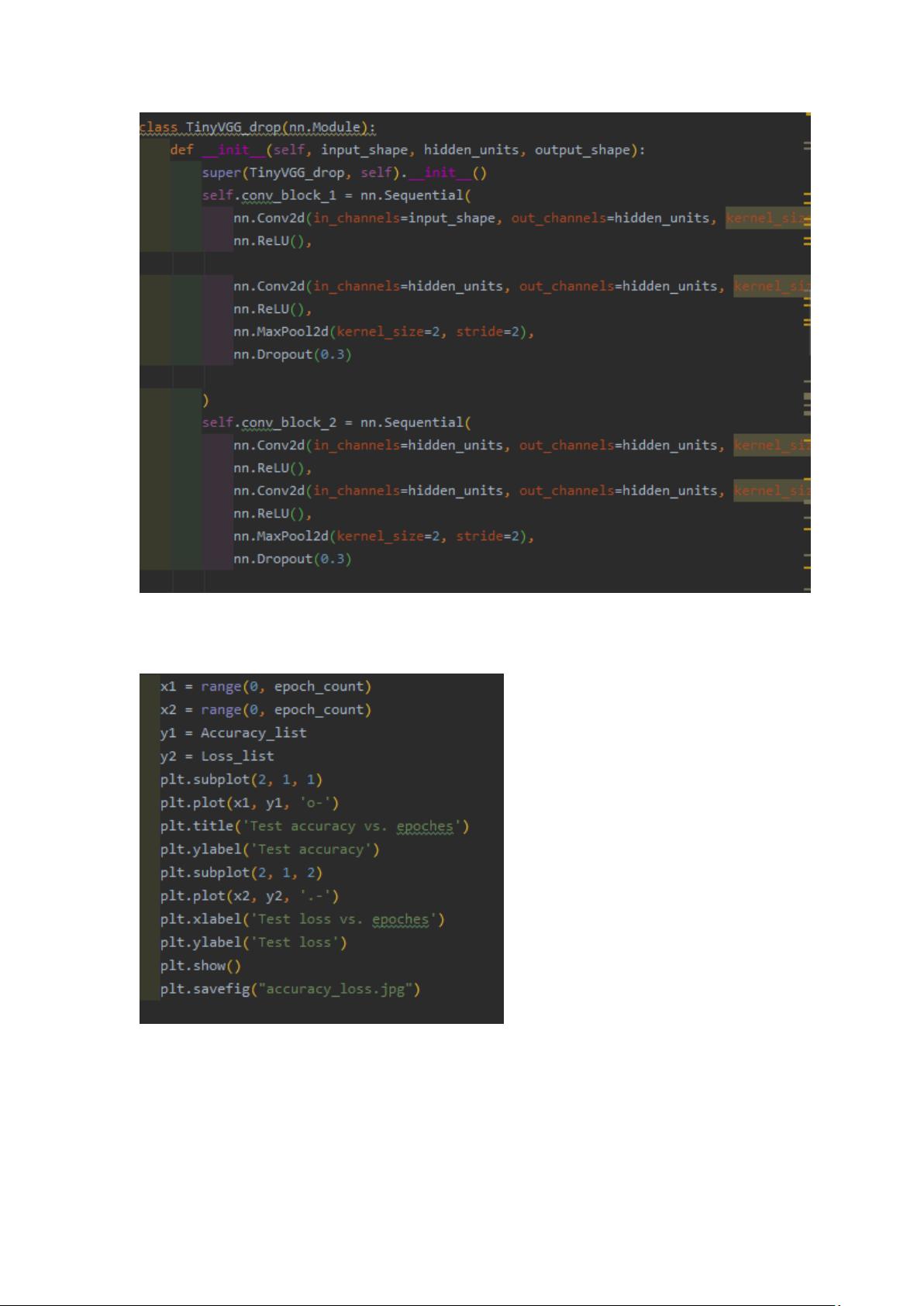
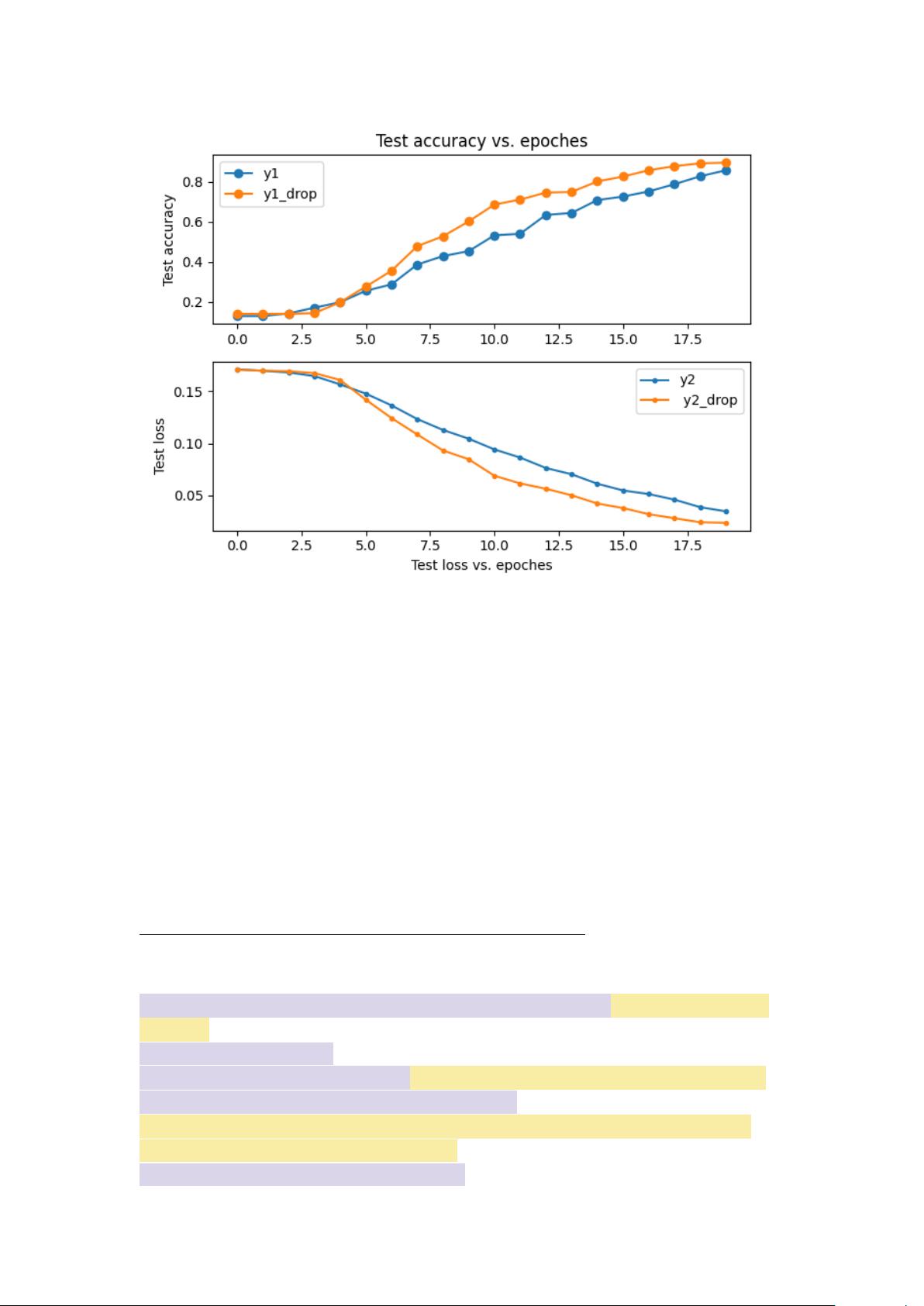
2)加入 dropout 层:构造两个模型一个未加入 dropout 层
torch.save(model, 'tinyvgg-pokemon.pth')
一个加入 dropout 层,
torch.save(model_drop, 'tinyvgg_drop-pokemon.pth')
采取
nn.Dropout(0.3)
代码如下:
 训练CNN分类模型-pokemon(文件包括数据集) (245个子文件)
训练CNN分类模型-pokemon(文件包括数据集) (245个子文件)  训练cnn分类模型.docx 9.38MB
训练cnn分类模型.docx 9.38MB image_06626.jpg 98KB image_06629.jpg 74KB image_06737.jpg 69KB image_06640.jpg 67KB image_06619.jpg 66KB image_06628.jpg 61KB image_05087.jpg 59KB image_05661.jpg 59KB image_06633.jpg 58KB image_06758.jpg 58KB image_06759.jpg 57KB image_05148.jpg 57KB image_06772.jpg 57KB image_06639.jpg 57KB image_06613.jpg 56KB image_06750.jpg 55KB image_05646.jpg 54KB image_06638.jpg 54KB image_06637.jpg 54KB image_05093.jpg 54KB image_06749.jpg 53KB image_06765.jpg 53KB image_06617.jpg 53KB image_06738.jpg 52KB image_06773.jpg 52KB image_06755.jpg 52KB image_06631.jpg 52KB image_06771.jpg 52KB image_05200.jpg 52KB image_05189.jpg 52KB image_06648.jpg 51KB image_06741.jpg 51KB image_06753.jpg 50KB image_05149.jpg 50KB image_05139.jpg 49KB image_06612.jpg 49KB image_05172.jpg 49KB image_05643.jpg 49KB image_05095.jpg 49KB image_05211.jpg 49KB image_06630.jpg 47KB image_06766.jpg 47KB image_06770.jpg 47KB image_05126.jpg 46KB image_05185.jpg 46KB image_05183.jpg 46KB image_05645.jpg 45KB image_05207.jpg 45KB image_06622.jpg 45KB image_06762.jpg 45KB image_05184.jpg 45KB image_05179.jpg 45KB image_06747.jpg 44KB image_06751.jpg 44KB image_05131.jpg 44KB image_05670.jpg 43KB image_05195.jpg 43KB image_06636.jpg 43KB image_05103.jpg 43KB image_05649.jpg 43KB image_05115.jpg 42KB image_05631.jpg 42KB image_05157.jpg 42KB image_05116.jpg 42KB image_05187.jpg 42KB image_06740.jpg 42KB image_05114.jpg 42KB image_05168.jpg 41KB image_05099.jpg 41KB image_05137.jpg 41KB image_05659.jpg 41KB image_06625.jpg 41KB image_05089.jpg 41KB image_06761.jpg 41KB image_06618.jpg 41KB image_06615.jpg 40KB image_05160.jpg 40KB image_05202.jpg 40KB image_05672.jpg 40KB image_06642.jpg 40KB image_05638.jpg 40KB image_05656.jpg 40KB image_05105.jpg 40KB image_05162.jpg 39KB image_05203.jpg 39KB image_05112.jpg 39KB image_05122.jpg 39KB image_05194.jpg 39KB image_05671.jpg 39KB image_05156.jpg 39KB image_05150.jpg 39KB image_06624.jpg 39KB image_05165.jpg 39KB image_05130.jpg 39KB image_05673.jpg 39KB image_05098.jpg 39KB image_05174.jpg 38KB image_06744.jpg 38KB image_05683.jpg 38KB
image_06626.jpg 98KB image_06629.jpg 74KB image_06737.jpg 69KB image_06640.jpg 67KB image_06619.jpg 66KB image_06628.jpg 61KB image_05087.jpg 59KB image_05661.jpg 59KB image_06633.jpg 58KB image_06758.jpg 58KB image_06759.jpg 57KB image_05148.jpg 57KB image_06772.jpg 57KB image_06639.jpg 57KB image_06613.jpg 56KB image_06750.jpg 55KB image_05646.jpg 54KB image_06638.jpg 54KB image_06637.jpg 54KB image_05093.jpg 54KB image_06749.jpg 53KB image_06765.jpg 53KB image_06617.jpg 53KB image_06738.jpg 52KB image_06773.jpg 52KB image_06755.jpg 52KB image_06631.jpg 52KB image_06771.jpg 52KB image_05200.jpg 52KB image_05189.jpg 52KB image_06648.jpg 51KB image_06741.jpg 51KB image_06753.jpg 50KB image_05149.jpg 50KB image_05139.jpg 49KB image_06612.jpg 49KB image_05172.jpg 49KB image_05643.jpg 49KB image_05095.jpg 49KB image_05211.jpg 49KB image_06630.jpg 47KB image_06766.jpg 47KB image_06770.jpg 47KB image_05126.jpg 46KB image_05185.jpg 46KB image_05183.jpg 46KB image_05645.jpg 45KB image_05207.jpg 45KB image_06622.jpg 45KB image_06762.jpg 45KB image_05184.jpg 45KB image_05179.jpg 45KB image_06747.jpg 44KB image_06751.jpg 44KB image_05131.jpg 44KB image_05670.jpg 43KB image_05195.jpg 43KB image_06636.jpg 43KB image_05103.jpg 43KB image_05649.jpg 43KB image_05115.jpg 42KB image_05631.jpg 42KB image_05157.jpg 42KB image_05116.jpg 42KB image_05187.jpg 42KB image_06740.jpg 42KB image_05114.jpg 42KB image_05168.jpg 41KB image_05099.jpg 41KB image_05137.jpg 41KB image_05659.jpg 41KB image_06625.jpg 41KB image_05089.jpg 41KB image_06761.jpg 41KB image_06618.jpg 41KB image_06615.jpg 40KB image_05160.jpg 40KB image_05202.jpg 40KB image_05672.jpg 40KB image_06642.jpg 40KB image_05638.jpg 40KB image_05656.jpg 40KB image_05105.jpg 40KB image_05162.jpg 39KB image_05203.jpg 39KB image_05112.jpg 39KB image_05122.jpg 39KB image_05194.jpg 39KB image_05671.jpg 39KB image_05156.jpg 39KB image_05150.jpg 39KB image_06624.jpg 39KB image_05165.jpg 39KB image_05130.jpg 39KB image_05673.jpg 39KB image_05098.jpg 39KB image_05174.jpg 38KB image_06744.jpg 38KB image_05683.jpg 38KB