




STATA 十八讲:6 程序
中国人民大学 陈传波
chrisccb@126.com
62
keep price weight
tempfile master part1
save “`master’”
drop weight
save “`part1’”
use “`master’”, clear
drop price
rename weight price
append using “`part1’”
restore
/*在这种情形下,无论是出现运行错误还是中途中止,都不会破坏原数据文件,也不会产生
垃圾文件。*/
*============================end====================================/*
6.7 基尼系数命令的创建案例 (选学内容)
6.7.1 背景知识:基尼系数
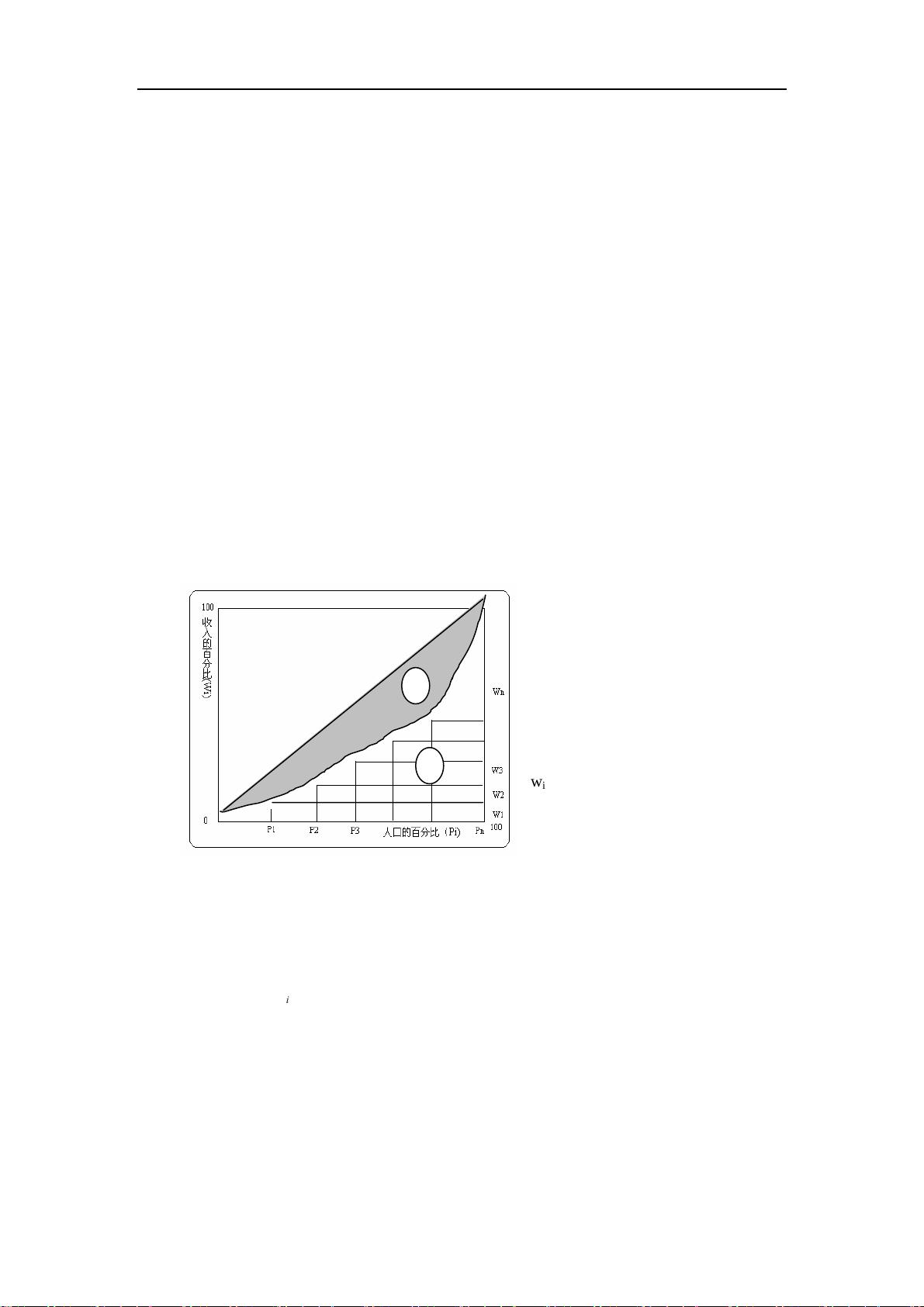
基尼系数是通过计算洛伦茨曲线图
中洛伦茨曲线与对角线之间的面积
A 以及对角线右下方的直角三角形
面积(A+B),将这两块面积相除而求
得。即基尼系数=A/(A+B)。在基尼
系数的计算上存在许多公式和算法,
一种较直观简便的计算方法是:
假定样本人口可以分成 n 组,设
w
i
、m
i
和 p
i
分别代表第 i 组的收入份
额、平均人均收入和人口频数
(i=1,2,…n),对全部样本按人均收
入( m
i
)由小到大排序后,基尼系数
(G)可由公式(1)计算出来:
Q
i
为从 1 到 i 的累积收入比重。B 为洛伦茨曲线右下方的面积。p
i
、w
i
从 1 到 n 的和为 1。
任务:试编写一个计算 gini 系数的命令,并计算湖北农户的基尼系数,数据 hbdata97.dta,
部分数据如下表(其中 hhid 为户代码, inc 为家庭纯收入, hhsize 为家庭人口数)。
6.7.2 粗糙且只能使用一次的程序
*============================begin====================================
cd c:\\ex3 //定位路径
)1()2(121
11
ii
n
i
i
n
i
i
wQpBG −−=−=
∑∑
==
完全平等线
洛伦兹曲线
q
1
o
2
q
2
A
B
∑
=
=
i
k
ki
wQ
1


















- 1
- 2
- 3
- 4
前往页