POEM Reconstructing Hand in a Point Embedded.pdf

需积分: 0 126 浏览量
更新于2024-11-19
收藏 1.29MB PDF 举报
多视图立体三维重建MVS论文
POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
Lixin Yang
1,2
Jian Xu
3
Licheng Zhong
1
Xinyu Zhan
1
Zhicheng Wang
3
Kejian Wu
3
Cewu Lu
1,2†
1
Shanghai Jiao Tong University
2
Shanghai Qi Zhi Institute
3
Nreal
{siriusyang, zlicheng, kelvin34501, lucewu}@sjtu.edu.cn
{jianxu, kejian}@nreal.ai chgggo@gmail.com
Abstract
Enable neural networks to capture 3D geometrical-
aware features is essential in multi-view based vision tasks.
Previous methods usually encode the 3D information of
multi-view stereo into the 2D features. In contrast, we
present a novel method, named POEM, that directly oper-
ates on the 3D POints Embedded in the Multi-view stereo
for reconstructing hand mesh in it. Point is a natural form
of 3D information and an ideal medium for fusing fea-
tures across views, as it has different projections on dif-
ferent views. Our method is thus in light of a simple yet
effective idea, that a complex 3D hand mesh can be rep-
resented by a set of 3D points that 1) are embedded in
the multi-view stereo, 2) carry features from the multi-view
images, and 3) encircle the hand. To leverage the power
of points, we design two operations: point-based feature
fusion and cross-set point attention mechanism. Evalua-
tion on three challenging multi-view datasets shows that
POEM outperforms the state-of-the-art in hand mesh re-
construction. Code and models are available for research
at github.com/lixiny/POEM
1. Introduction
Hand mesh reconstruction plays a central role in the field
of augmented and mixed reality, as it can not only deliver
realistic experiences for the users in gaming but also sup-
port applications involving teleoperation, communication,
education, and fitness outside of gaming. Many significant
efforts have been made for the monocular 3D hand mesh
reconstruction [1, 5, 7, 9, 31, 32]. However, it still strug-
gles to produce applicable results, mainly for these three
reasons. (1) Depth ambiguity. Recovery of the absolute
position in a monocular camera system is an ill-posed prob-
lem. Hence, previous methods [9, 31, 54] only recovered
the hand vertices relative to the wrist (i.e. root-relative).
(2) Unknown perspectives. The shape of the hand’s 2D
†
Cewu Lu is the corresponding author, the member of Qing Yuan Re-
search Institute and MoE Key Lab of Artificial Intelligence, AI Institute,
Shanghai Jiao Tong University, China and Shanghai Qi Zhi institute.
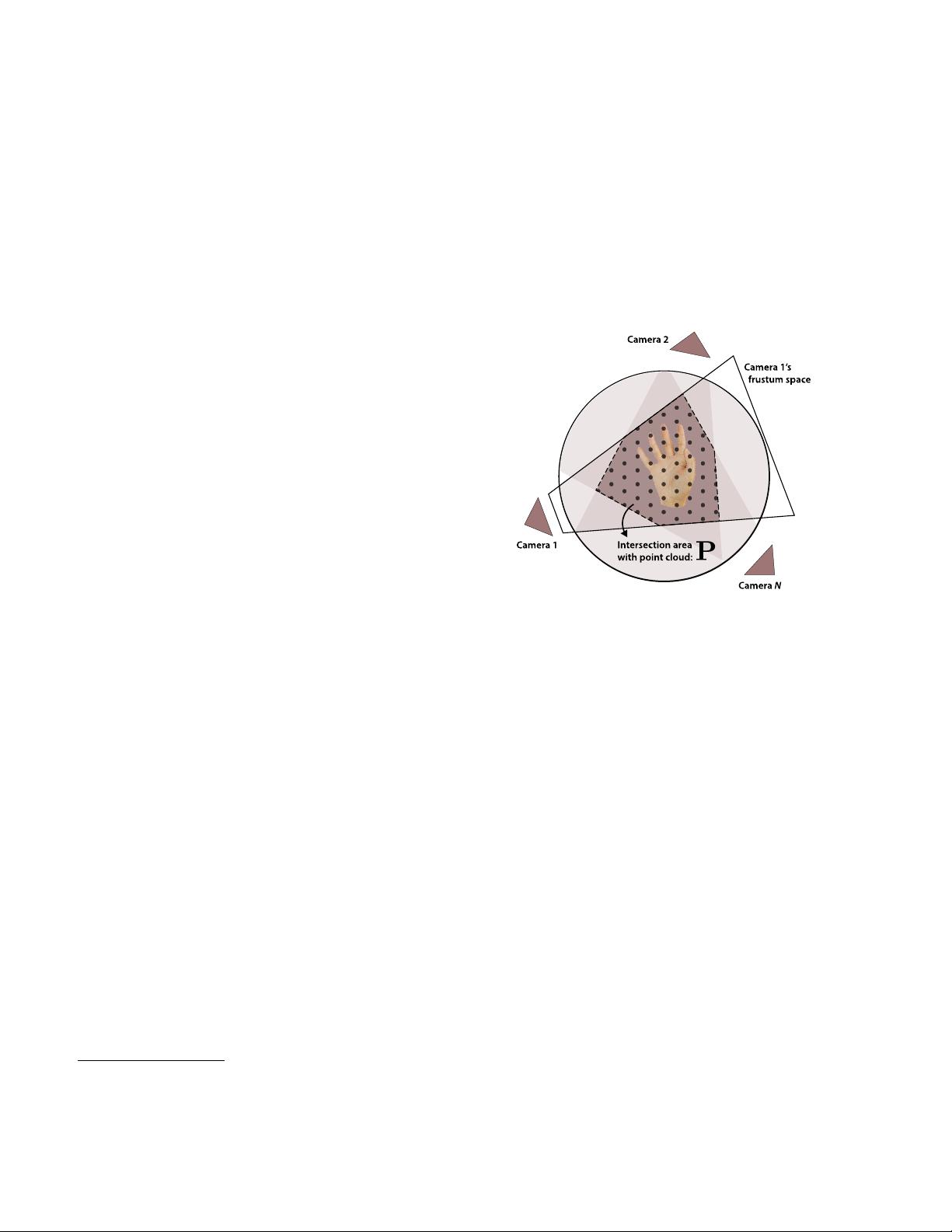
Figure 1. Intersection area of N cameras’ frustum spaces. The
gray dots represent the point cloud P aggregated from N frustums.
Our method: POEM, standing for the point embedded multi-view
stereo, focuses on the dark area scatted with gray dots.
projection is highly dependent on the camera’s perspec-
tive model (i.e. camera intrinsic matrix). However, the
monocular-based methods usually suggest a weak perspec-
tive projection [1, 27], which is not accurate enough to re-
cover the hand’s 3D structure. (3) Occlusion. The occlu-
sion between the hand and its interacting objects also chal-
lenges the accuracy of the reconstruction [32]. These issues
limit monocular-based methods from practical application,
in which the absolute and accurate position of the hand sur-
face is required for interacting with our surroundings.
Our paper is thus focusing on reconstructing hands from
multi-view images. Motivation comes from two aspects.
First, the issues mentioned above can be alleviated by lever-
aging the geometrical consistency among multi-view im-
ages. Second, the prospered multi-view hand-object track-
ing setups [2, 4, 49, 55] and VR headsets bring us an urgent
demand and direct application of multi-view hand recon-
struction in real-time. A common practice of multi-view 3D
pose estimation follows a two-stage design. It first estimates
the 2D key points of the skeleton in each view and then
back-project them to 3D space through several 2D-to-3D
lifting methods, e.g. algebraic triangulation [17,18,39], Pic-
torial Structures Model (PSM) [33, 38], 3D CNN [18, 43],
21108
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
979-8-3503-0129-8/23/$31.00 ©2023 IEEE
DOI 10.1109/CVPR52729.2023.02022
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) | 979-8-3503-0129-8/23/$31.00 ©2023 IEEE | DOI: 10.1109/CVPR52729.2023.02022
Authorized licensed use limited to: Institute of Software. Downloaded on November 08,2024 at 02:43:11 UTC from IEEE Xplore. Restrictions apply.
下载后可阅读完整内容,剩余9页未读,立即下载
151 浏览量
158 浏览量
2021-09-23 上传
149 浏览量
114 浏览量
2021-11-09 上传
2021-09-30 上传
107 浏览量
2021-10-08 上传
2021-11-09 上传
2006-02-23 上传
143 浏览量
2023-08-10 上传
2021-10-30 上传
167 浏览量
136 浏览量
109 浏览量
107 浏览量
168 浏览量
127 浏览量
2021-05-25 上传
2023-07-26 上传
168 浏览量
资源评论



GL_Rain
- 粉丝: 3149
- 资源: 36









最新资源
- 自主设计自动驾驶控制器与车道偏离预警系统:基于Simulink控制模型的功能验证与实时警报界面展示,自动驾驶控制器,车道偏离预警系统,基于Prescan设计场景和交通流,在Simulink中建立了相应
- 基于Simulink 2018+与Carsim 2019的自适应MPC轨迹跟踪控制仿真研究:跟踪轨迹展示,无人驾驶基于自适应mpc的轨迹跟踪控制仿真跟踪轨迹,simulink版本2018及以上,car
- 基于PSIM软件的LLC闭环仿真模型研究:探究半桥LLC暂稳态与调频ZVS特性分析,LLC闭环仿真PSIM调频ZVS 半桥LLC闭环仿真模型,基于PSIM建模仿真 可以进行LLC暂态、稳态仿真,仿真
- 基于Matlab计算任意三点夹角的算法教程:坐标转换与夹角计算详解,Matlab计算任意三点的夹角 给出特定一组坐标(可以直角坐标系或极坐标系) 计算出所有夹角值 matlab代码,备注清楚,更改为自
- 橘子公益端口8.2.zip
- 基于FCM聚类的数据归一化及自定义聚类处理详解:MATLAB代码实践与解析,FCM聚类,代码对数据先进行归一化然后聚类 可自定义聚类个数,求得每类的具体数据 matlab代码,备注清楚,更改为自己的数
- 基于双层优化的电动汽车充放电行为时空协同调度研究:实现与风电协同的输配协同调度策略,MATLAB代码:基于双层优化的电动汽车优化调度研究 关键词:双层优化 选址定容 输配协同 时空优化 参考
- 基于MATLAB的多种概率分布拟合与KS检验:用于概率分析、可靠度计算等领域的实战教程,11种概率分布的拟合与ks检验,可用于概率分析,可靠度计算等领域 案例中提供11种概率分布,具体包括:gev、l
- "基于PSIM9.1的Buck仿真闭环与双闭环控制模型:暂稳态模拟及控制电路设计探索",Buck仿真闭环Psim双闭环 Buck闭环仿真模型,基于PSIM建模仿真 可以进行暂态、稳态仿真,电压电流双
- 核密度估计方法下的概率分布拟合及KS检验确定最优核密度估计:使用多种核密度算法进行可视化矩形框调整优化拟合策略及Matlab代码实践 ,核密度估计及ks检验确定最优核密度估计 使用Normal、box
- Labview与基恩士PLC上位链路协议通讯通用VI支持全系列网口设备连通,labview与基恩士plc上位链路协议通讯通用vi,支持基恩士plc带网口全系列,有需要的欢迎咨询 ,关键词:LabVI
- 基于弦波SVPWM驱动的龙贝格观测器无感FOC风机方案:高压支持顺风启动原理图和源代码全解析,foc风机方案 高压 支持顺风启动 使用弦波 svpwm驱动方式 使用龙贝格观测器 无感FOC方案
- 基于PSO优化的极限学习机ELM算法详解Matlab代码,注释详尽,易于上手使用,PSO优化极限学习机ELM matlab代码,备注详细,易于使用 ,核心关键词:PSO优化; 极限学习机ELM; M
- 汽车EPB仿真模型:Carsim与Simulink联合实现制动钳动力学建模及电机控制功能仿真,汽车EPB仿真模型,Carsim和Simulink联合仿真 1.其中包括 制动钳系统 的动力学建模
- COMSOL激光烧蚀三维仿真:体热源与引力场对温度场影响分析,COMSOL 激光烧蚀3D体热源引力场温度场仿真 ,核心关键词:COMSOL; 激光烧蚀; 3D体热源; 引力场; 温度场仿真;,"COM
- "COMSOL仿真下的3D脉冲激光刻槽技术与应用研究",COMSOL 3D脉冲激光刻槽 ,"COMSOL 3D激光刻槽技术:脉冲激光精准切割工艺"
