智慧城市人工智能开放平台建设方案.docx
版权申诉
90 浏览量
2022-11-13
16:44:54
上传
评论
收藏 1.07MB DOCX 举报


智慧城市人工智能开放平台建设方案
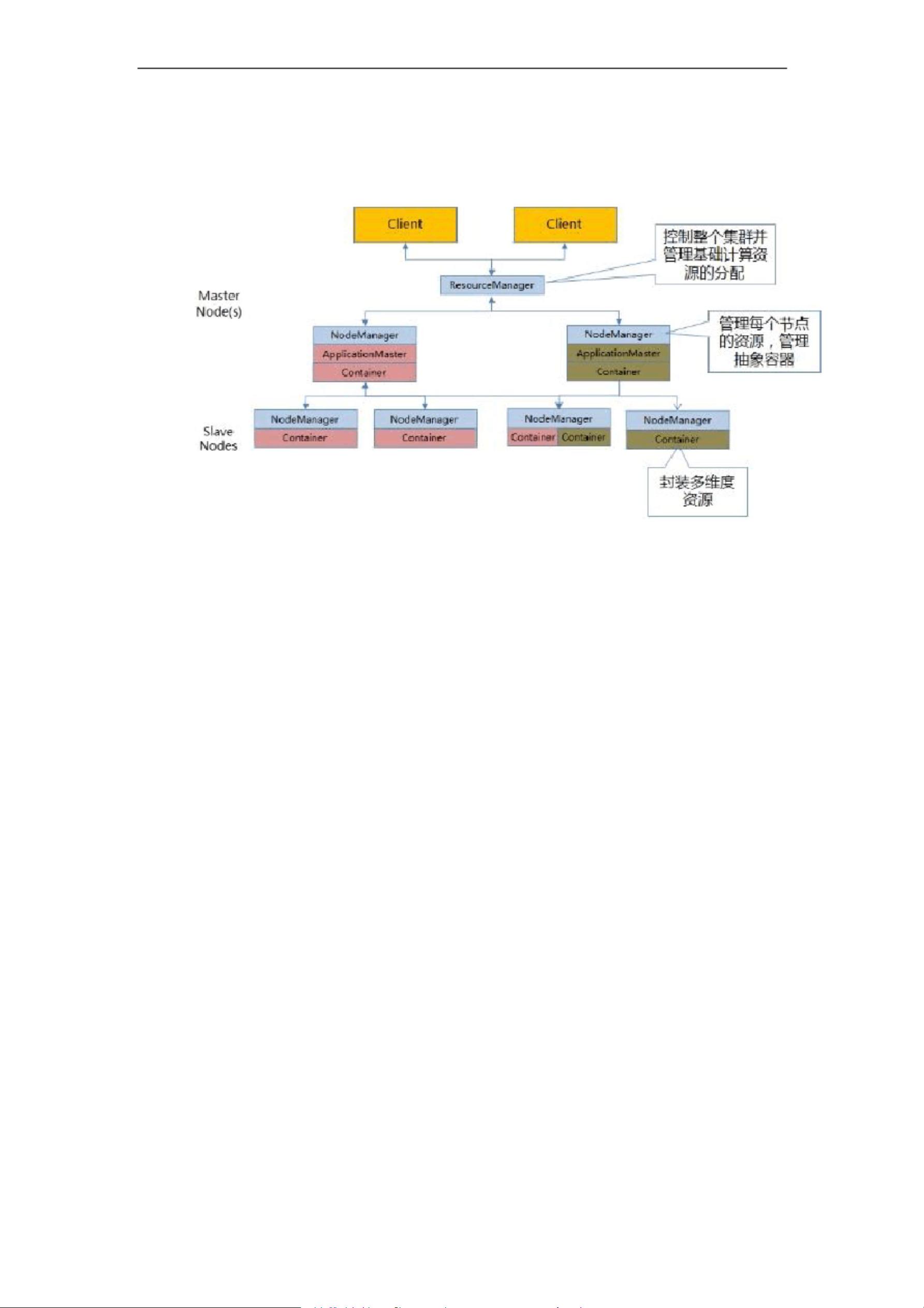
1. 架构设计
1.1. 总体架构设计
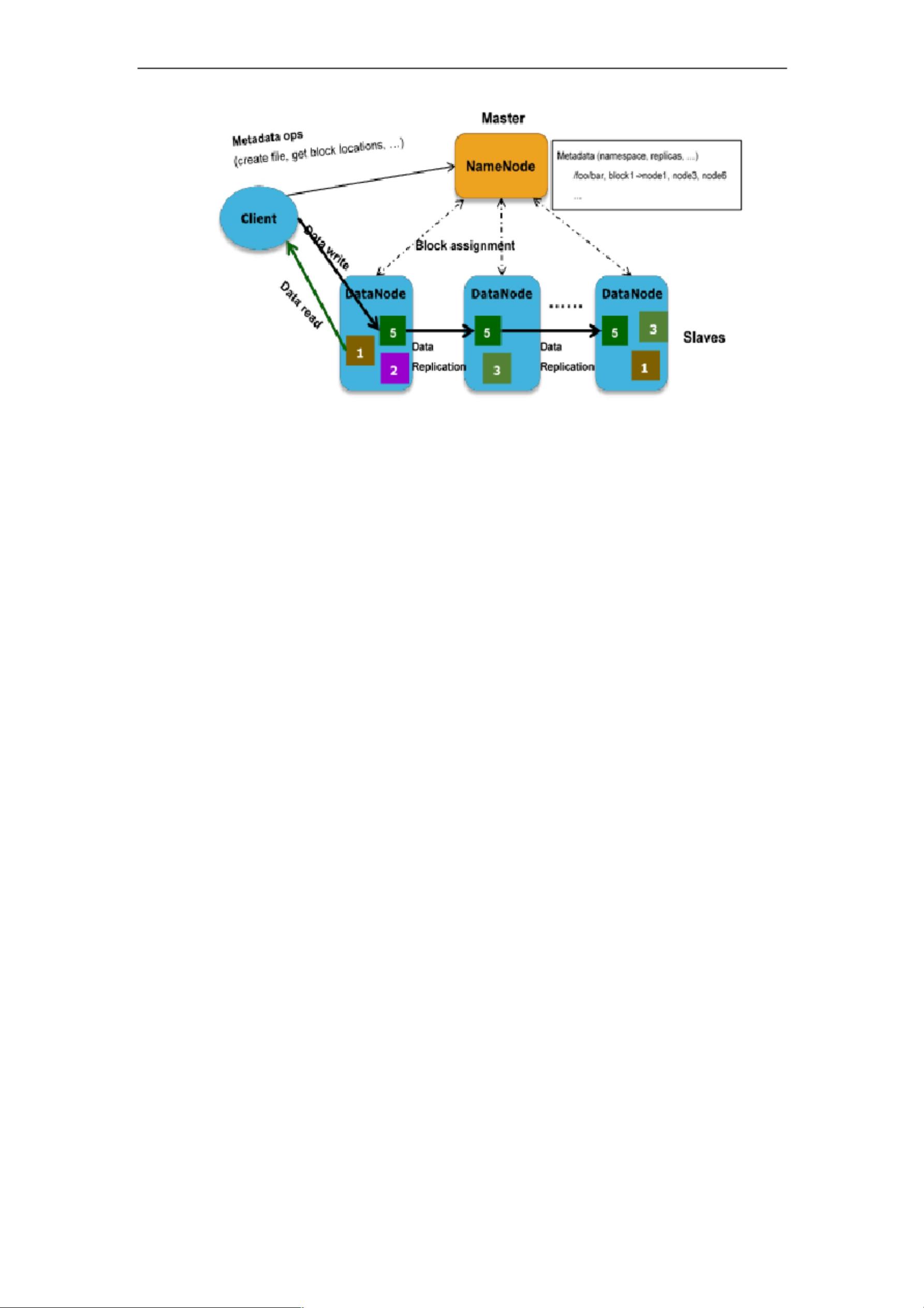
人工智能平台系统底层基于人工智能和大数据平台构建,在 x86 服务器之上
提供数据的采集、存储、计算、算法模型和前端展现等功能。 人工智能平台和
IoT 提供人体识别、行为识别、倾倒行为分析等算法的建模和训练能力;人工智
能平台 边缘平台则处理街道、小区大门等前端摄像头设备数据的实时接入和监
管,并提供模型部署、规则设计等功能。基于平台,提供倾倒行为识别系统,并
开放数据传输接口,用于倾倒行为信息等样本信息的导入和导出。
系统架构涉及到的组件由底向上详细信息如下:
1.1.1. 容器操作系统
云平台系统是为大数据应用量身订做的云操作系统,基于
Docker 和
Kubernetes 开发。支持一键部署,基于优先级的抢占式资源调度和细粒度资源分
配,让大数据应用轻松拥抱云服务。
未来企业对于构建统一的企业大数据平台来驱动各种业务具有强烈需求,统
一的企业大数据平台需要提供以下功能:
➢
资源弹性共享—提高资源利用率
灵活部署:支持灵活部署大数据应用和其他常规应用
资源调度:具备自动扩容和自动修复功能
服务发现:具备集中式的仓库
➢
隔离性—保障服务质量和安全性
数据隔离:包括数据源、访问模式等
计算隔离:隔离 CPU、内存、网络、磁盘 IO 等
容器操作系统满足了以上企业大数据平台的需要,支持对 TDH 的一键式部
署、扩容、缩容,同时也允许其他服务和大数据服务共享集群,从而提高资源的
使用率。容器操作系统创新的抢占式资源调度模型能在保障实时业务的同时,提


剩余51页未读,继续阅读
资源评论


G11176593
- 粉丝: 6643
- 资源: 3万+











