
Apache Kylin安装⽂档
Kylin安装
Kylin使⽤案例
1. Kylin安装
使⽤FTP⼯具上传apache-kylin-2.5.1-bin-hbase1x.tar.gz压缩包到node01的 opt/software ⽬录下
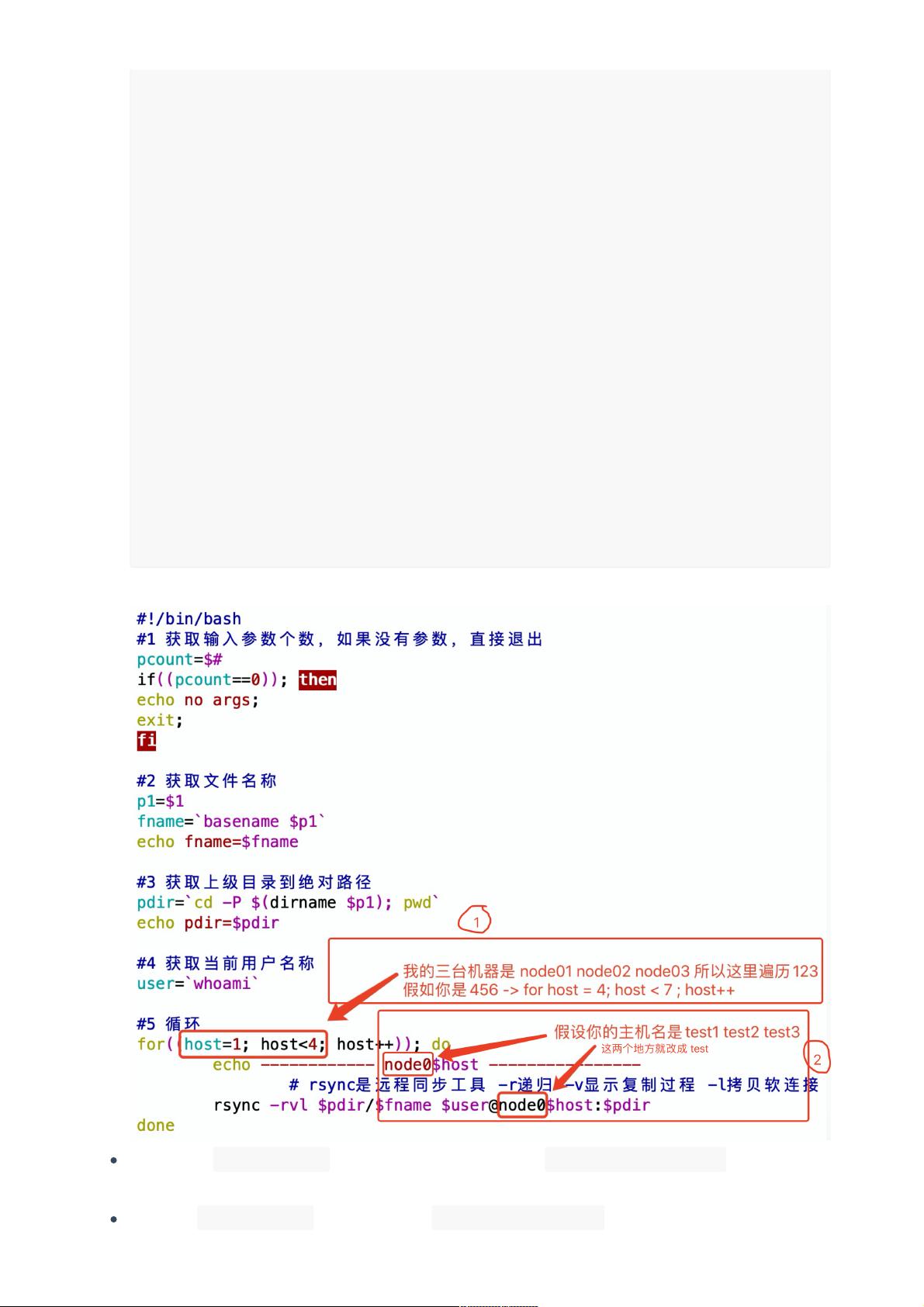
解压上⼀步上传的压缩包 opt/module 下 tar -zxvf apache-kylin-2.5.1-bin-
hbase1x.tar.gz -C /opt/module
进⼊ opt/module ⽬录,更改apache-kylin-2.5.1-bin-hbase1x⽬录名字 mv pache-kylin-2.5.1-
bin-hbase1x kylin-2.5.1
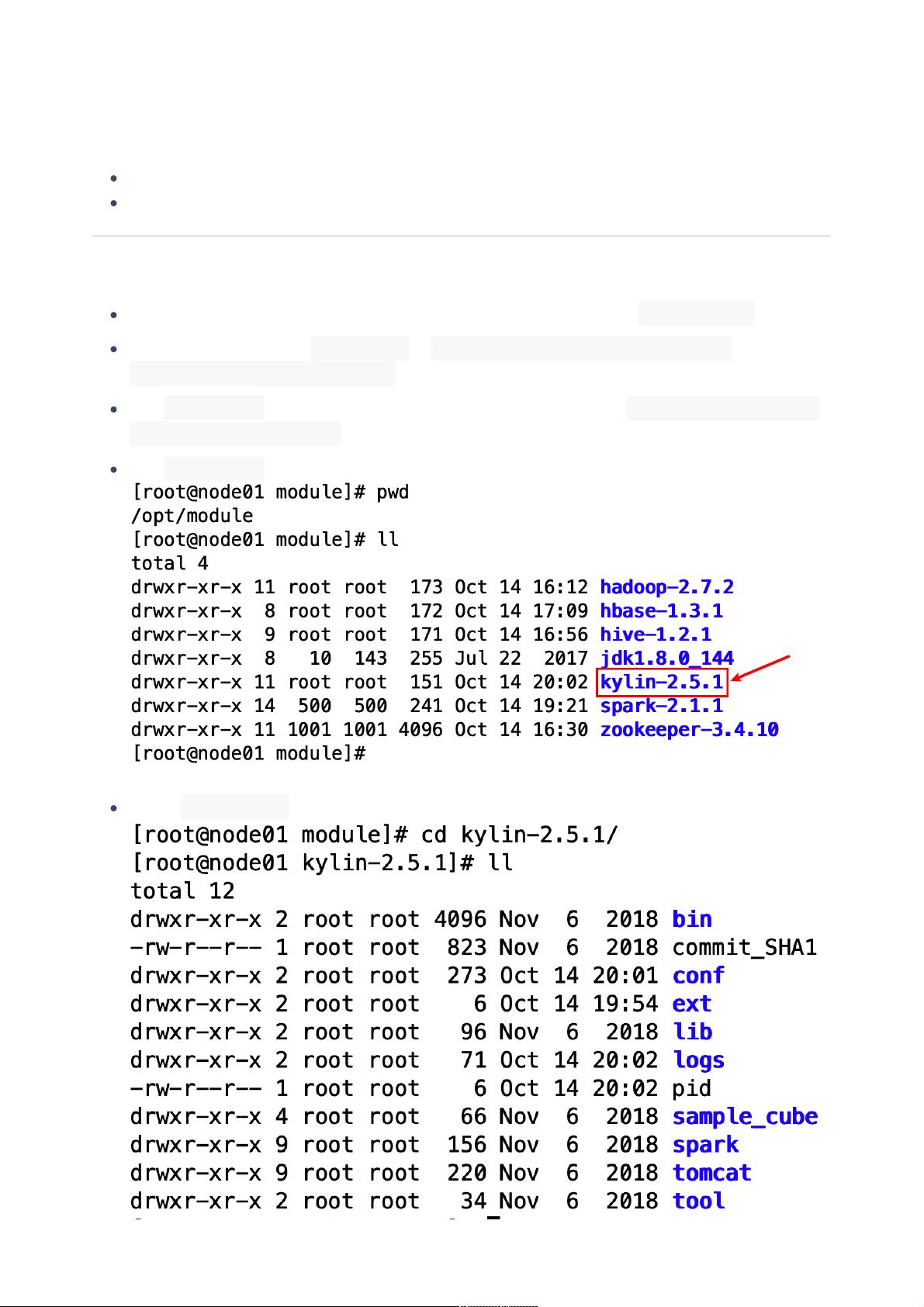
此时 opt/module ⽬录结构如下
进⼊到 kylin-2.5.1 ⽬录,查看kylin的⽬录结构

剩余14页未读,继续阅读
资源评论


我与共饮长江水
- 粉丝: 4
- 资源: 1









最新资源
- Origin教程007所需练习数据
- 高速脉冲与高速计数指令.pdf
- 1.5T气缸气动式压机机械设计图纸+PPT+说明文档+技术方案资料+其它技术资料100%好用超级好的技术资料.zip
- 120°模温机工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- 毕设和企业适用springboot自动化仓库管理平台类及智能会议管理平台源码+论文+视频.zip
- 毕设和企业适用springboot自动化仓库管理平台类及智能电商平台源码+论文+视频.zip
- 毕设和企业适用springboot自动化仓库管理平台类及智能办公平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及企业供应链平台源码+论文+视频.zip
- 毕设和企业适用springboot自动化仓库管理平台类及智能客服系统源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及企业数字资产管理平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及企业云管理平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及视频编辑平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及视觉识别平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及视频流平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及数据处理平台源码+论文+视频.zip
- 毕设和企业适用springboot智能云服务平台类及虚拟银行平台源码+论文+视频.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


