
1、HashMap 概述:
HashMap 是基于哈希表的 Map 接口的非同步实现。此实现提供所有可选的映射操作,
并允许使用
null
值和
null
键 。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
2、HashMap 的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。所有的数据
结构都可以用这两个基本结构来构造的
数组:数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时
间复杂度小,为 O(1);数组的特点是:寻址容易,插入和删除困难;
链表:链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,
达 O(N)。链表的特点是:寻址困难,插入和删除容易。
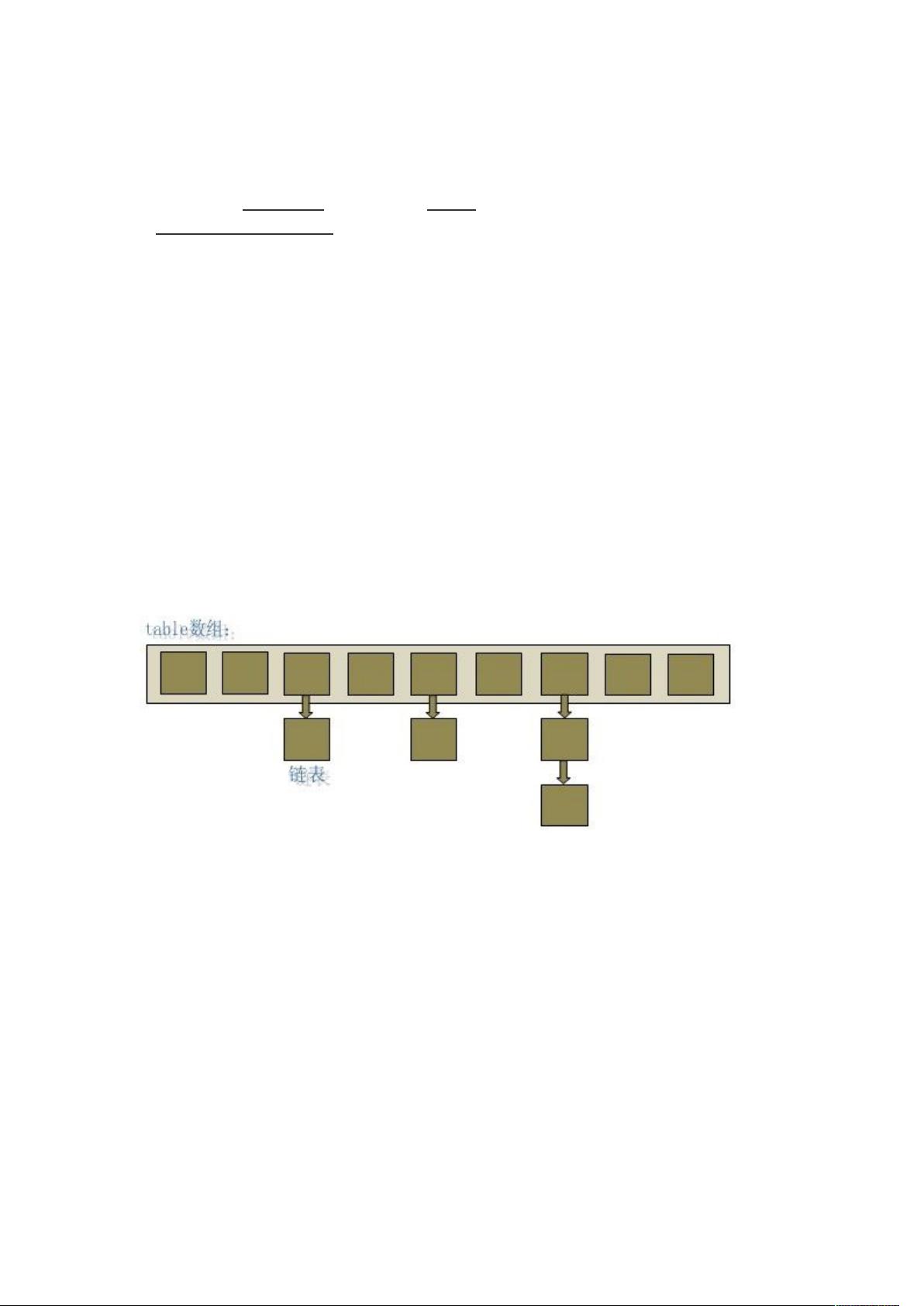
哈希表((Hash table):由数组+链表组成的。既满足了数据的查找方便,同时不占用太
多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我
们可以理解为“链表的数组”
一个长度为 16 的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么
样的规则存储到数组中呢。一般情况是通过 hash(key)%len 获得,也就是元素的 key 的哈
希值对数组长度取模得到。比如上述哈希表中,
12%16=12,28%16=12,108%16=12,140%16=12。所以 12、28、108 以及 140 都存储在
数组下标为 12 的位置。
HashMap 其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一
个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这
里 HashMap 有做一些处理。
首先 HashMap 里面实现一个静态内部类 Entry,其重要的属性有 key , value, next,
从属性 key,value 我们就能很明显的看出来 Entry 就是 HashMap 键值对实现的一个基础
bean,我们上面说到 HashMap 的基础就是一个线性数组,这个数组就是 Entry[],Map 里


剩余14页未读,继续阅读
资源评论


源码小哥
- 粉丝: 5898
- 资源: 178









最新资源
- 基于一款语音交互智能家居机器人全部资料+详细文档+优秀项目.zip
- CuZnAl合金焊接方法 - .pdf
- Cu异种金属冷金属过渡熔钎焊接头显微组织与性能 - .pdf
- D406A钢电子束焊接头组织及性能分析 - .pdf
- 基于语音识别的智能家居控制方案研究与设计全部资料+详细文档+优秀项目.zip
- DB21T 2700-2016 焊接绝热气瓶充装站安全技术条件.pdf
- DG1427-2001钢制压力容器产品焊接试板的力学性能检验.pdf
- DIN 928-2000 焊接方螺母 Square weld nuts.pdf
- DIN 1910-1-1983 焊接 第1部分 焊接概念焊接方法分类.pdf
- DIN 1910-2-1977 焊接 金属焊接 工艺.pdf
- DIN 1910-5-1986 焊接.金属焊接.电阻焊接.方法.pdf
- DIN 1912-1 1976 焊接.钎焊图样表示法.焊接接头.焊接坡口及焊缝的概念与名称.pdf
- DIN 1912-2 1977 焊接.钎焊图样表示法.工作位置.焊缝倾角.焊缝旋转角度.PDF
- DIN 1910-11-1979 焊接.金属焊接材料术语.pdf
- DIN 2393-1-1994 有特殊尺寸精度的精密焊接钢管 尺寸.PDF
- DIN 6700-1-2001 中文版 铁路车辆及车辆部件的焊接.第1部分基本概念,基本规则.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


