
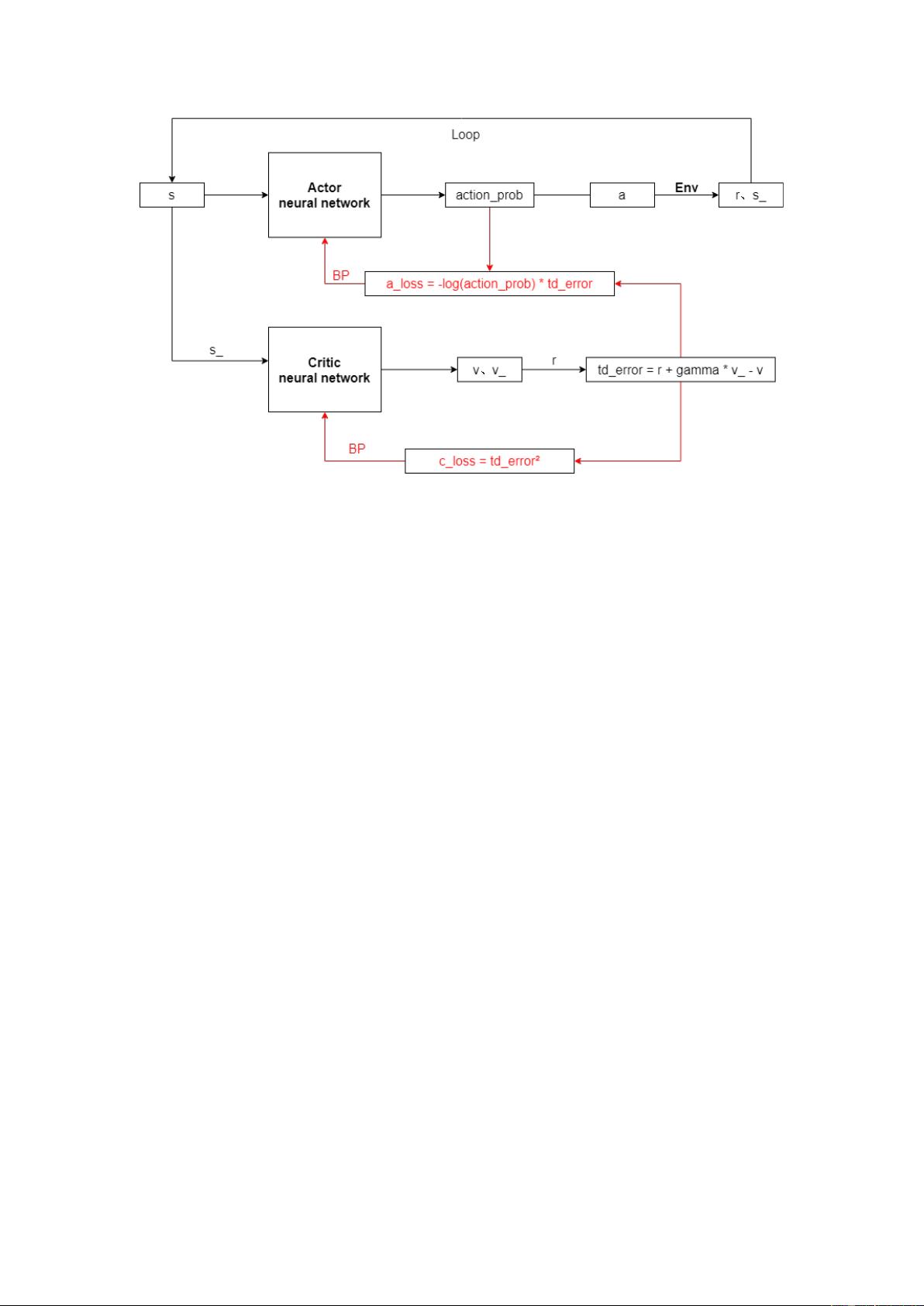
Actor-Critic 框架图
(1) 将当前状态 s 输入到 Actor 网络中,计算出选择每个动作的概率 action_prob,
输出概率最大的动作 a,在环境 Env 中执行 a,得到奖励 r 和下一个状态 s_;
(2) 将 s 和 s_分别输入 Critic 网络中,输出 v 和 v_,再结合 r 使用时间差分
(Temporal-difference,TD)方法计算值函数,即 ;
(3) 使用 td_error 的平方作为 Critic 网络的损失函数,即
²
,反
向传播更新网络参数;
(4) 结合第一步中每个动作的概率和 td_error 得到 Actor 网络的损失函数,即
,反向传播更新网络参数;
(5) 循环(1)~(4)。
剩余7页未读,继续阅读













评论0