

本文讲解了目标检测的基本概念,分析了实现目标检测的常用思路。下一篇
将介绍目标检测经典数据集—VOC 数据集的基本信息,和对 VOC 数据集进行
处理的方法。
一、目标检测基本概念
1. 什么是目标检测
目标检测是计算机视觉中的一个重要任务,近年来传统目标检测方法已经难以
满足人们对目标检测效果的要求,随着深度学习在计算机视觉任务上取得的巨
大进展,目前基于深度学习的目标检测算法已经成为主流。
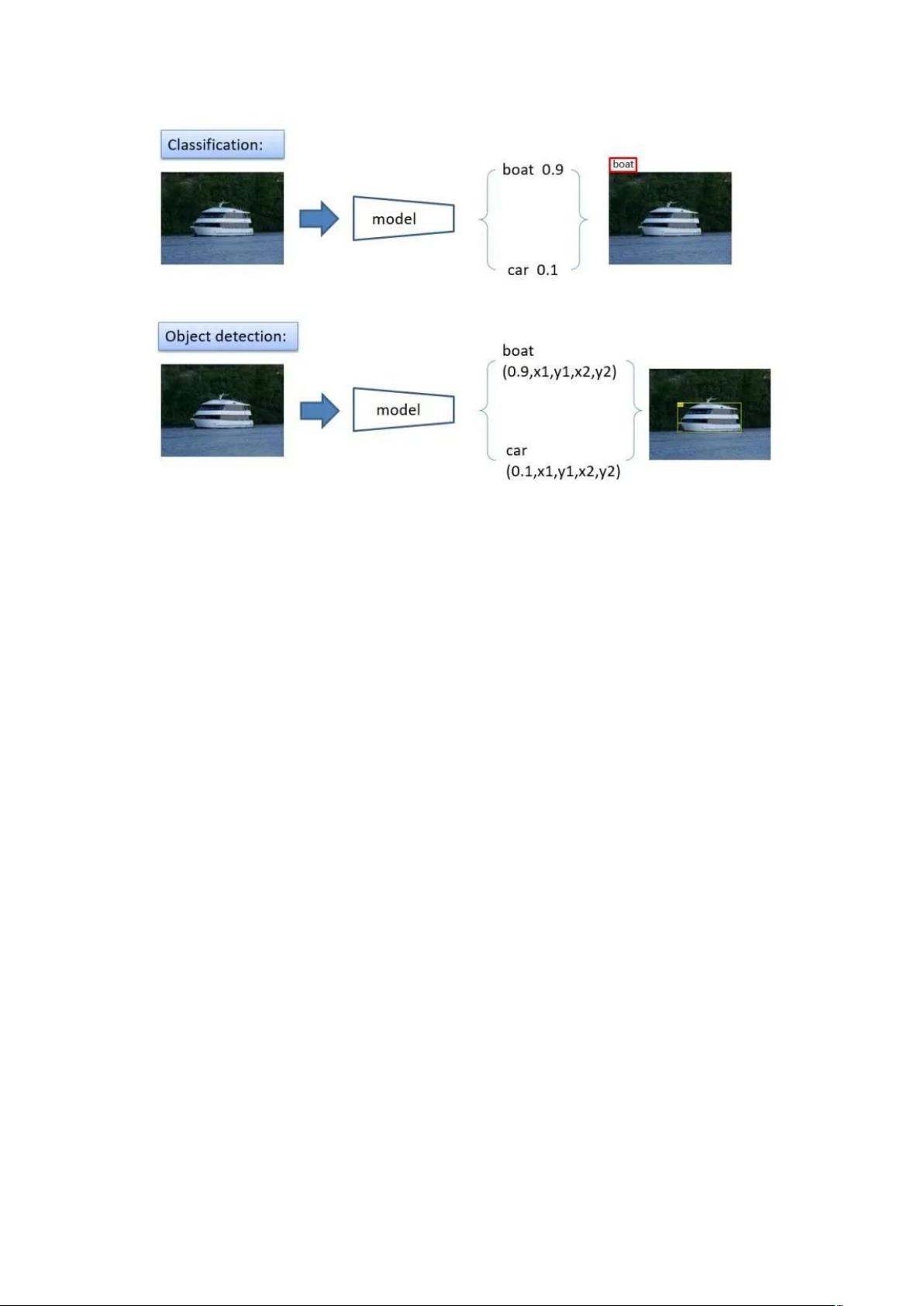
相比较于基于深度学习的图像分类任务,目标检测任务更具难度,具体区别如
下图所示。
图像分类:只需要判断输入的图像中是否包含感兴趣物体。
目标检测:需要在识别出图片中目标类别的基础上,还要精确定位到目标的
具体位置,并用外接矩形框标出。
剩余6页未读,继续阅读
资源评论


极客11
- 粉丝: 386
- 资源: 5519









最新资源
- 基于Matlab的10kW虚拟同步发电机小信号稳定控制仿真研究,10kW同步发电机(VSG)小信号稳定控制matlab仿真 【985双一流专业的电气工程博士自用仿真】 参数可改 1从lunwen中
- 有源电力滤波器对并网变流器谐波补偿研究:光伏发电并网应用下的效果分析及其优化策略,26 有源电力滤波器补偿并网变流器谐波 以光伏发电并网为应用场景 在并网联络线处加入有源电力滤波器 补偿前thd:0
- 改进IEEE 33节点系统下的潮流计算与电压分析:含风机光伏接入,电动机应用,不含特定内容(风光280除外),改进的IEEE33节点,潮流计算,电压分析,可加风机光伏,接电动机 含风光380,不含2
- lightningx.deb
- Simulink仿真下的自适应巡航控制(ACC)系统建模:速度与间距控制策略探究,Simulink仿真:基于模型预测的自适应巡航控制系(ACC)建模 参考文献:无 仿真平台:MATLAB Simuli
- 基于三菱PLC与MCGS组态的农田智能灌溉系统:详解梯形图程序、接线图与IO分配及组态画面,基于三菱PLC和MCGS组态农田智能灌溉系统 带解释的梯形图程序,接线图原理图图纸,io分配,组态画面 ,核
- 基于MATLAB的新能源与储能技术模型构建:光伏、飞轮储能、燃料电池与锂电池的综合应用,基于MATLAB搭建的光伏,飞轮储能,燃料电池和锂电池的模型,可以再此基础上搭建个各种形式的新能源和储能模型
- 微秒制造与超快激光应用研究:飞秒激光与石英玻璃的交互机制探索与COMSOL仿真分析,研究背景:随着微秒制造的发展,对超快激光的应用越来越广泛,对超快激光与物质作用机理的研究也越来越深入,目前做超快激光
- 西门子S7-200 PLC四层电梯组态仿真设计与程序实现,西门子S7-200PLC程序和组态王4层电梯四层电梯带组态仿真组态设计PLC设计 ,核心关键词:西门子S7-200PLC程序; 四层电梯;
- 直驱永磁同步风力发电机MATLAB仿真模型设计与分析,直驱永磁同步风力发电机MATLAB仿真模型 ,核心关键词:直驱永磁同步风力发电机; MATLAB仿真模型; 风电技术; 能源转换; 仿真模拟; 电
- 电压型单相双极性SPWM逆变仿真模型详解:原理、调制策略及载波与调制波频率影响分析,电压型单相双极性SPWM逆变仿真模型 含有对应的仿真说明,包含原理,调制策略 针对不同载波频率,调制波频率的仿真说
- COMSOL变压器油流注放电模型:仿真分析与应用探讨,COMSOL变压器油流注放电模型 ,核心关键词:COMSOL; 变压器; 油流注放电模型; 仿真模拟 ,COMSOL中变压器油流注放电模型的建立与
- "改进粒子群算法GAPSO:Matlab编程下的基本、混沌与遗传粒子群算法的程序与结果对比分析",改进粒子群算法GAPSO 采用matlab编程,有基本粒子群、混沌粒子群和遗传粒子群三种算法的程序和结
- COMSOL 6.0超声相控阵仿真模型:压力声学与固体力学对比建模介绍,COMSOL超声相控阵仿真模型 模型介绍:本链接有两个模型,分别使用压力声学与固体力学对超声相控阵无损检测进行仿真,负有模型说明
- 永磁同步电机一阶非线性自抗扰(ADRC)matlab仿真模型与参数调优研究,永磁同步电机一阶非线性自抗扰(ADRC)matlab,simulink模型 参数已调好含有参考文档,送自抗扰相关电子书 不
- 传统轿车ABS防抱死系统模糊控制策略研究:与PID及逻辑门限值控制的效能对比,联合仿真优化模型文件夹包含代码与模型原件,课题名称:传统轿车ABS防抱死系统控制策略研究 课题内容:基于Carsim和S
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


