







设计任务及要求:
设计任务:《儒林外史》小说词频分析系统
要 求:
对《儒林外史》小说统计中文词频,并分析出如下信息:
(1) 统计出小说中有效词语的词频(去掉一些虚词),存入词频文件,并且以词云形
式展现(展示形状可以任意)
(2) 根据小说主角在章节中出现的次数进行统计,以折线图的形式展示
(3) 对小说中的喜怒哀乐(4 种)进行词频统计,建立多系列的折线图
(4) 统计各章段落数和字数,展现为散点图
(5) 小说中的人物基于共现关系建立网络图
二、指导教师评语:
系统功能完善;回答问题正确、熟练;论文内容设计合理,文理通顺,图表完备、正
;平时表现良好。
系统功能基本实现;回答问题基本正确;论文内容设计合理,格式正确;平时表现良
好。
系统大部分功能实现;回答问题大部分正确;论文内容设计合理,格式正确;平时表
现良好。
系统功能不全;回答问题错误多;论文内容设计合理,格式正确;平时表现一般。
系统不能正常运行;回答问题错误过多或者未答辩;论文未交或者质量太差;平时缺
勤较多。
三、成绩
优秀 良好 中等 及格 不及格
指导教师签名:
年 月 日
《儒林外史》小说词频分析系统
1 选题的意义
语言文字虽然复杂,但不是没有痕迹可循。我们在语言中经常出现高频词,代表
我们的语言风格,因此对词频或者字频进行统计,有其特定意义。掌握这项技术对以
后的学习和生活具有现实意义,比如可以通过对问卷调查报告、政府工作报告、政策
文件、法令法规等等文本信息中分析统计出重点和关键字等重要信息。
2 系统功能需求分析
2.1 系统概述
词频统计有助于我们从大量的文本中获得洞见(insight),也是机器学习处理自然
语言文本的一种基础手段。现在词频统计的手段有很多,可以利用现成软件,也可以
编程实现。该系统通过对 Python 的 jieba、wordcloud、matplotlib 等库的综合运用,
实现了对网络小说的统计和分析,以及将分析结果进行图形化展示。
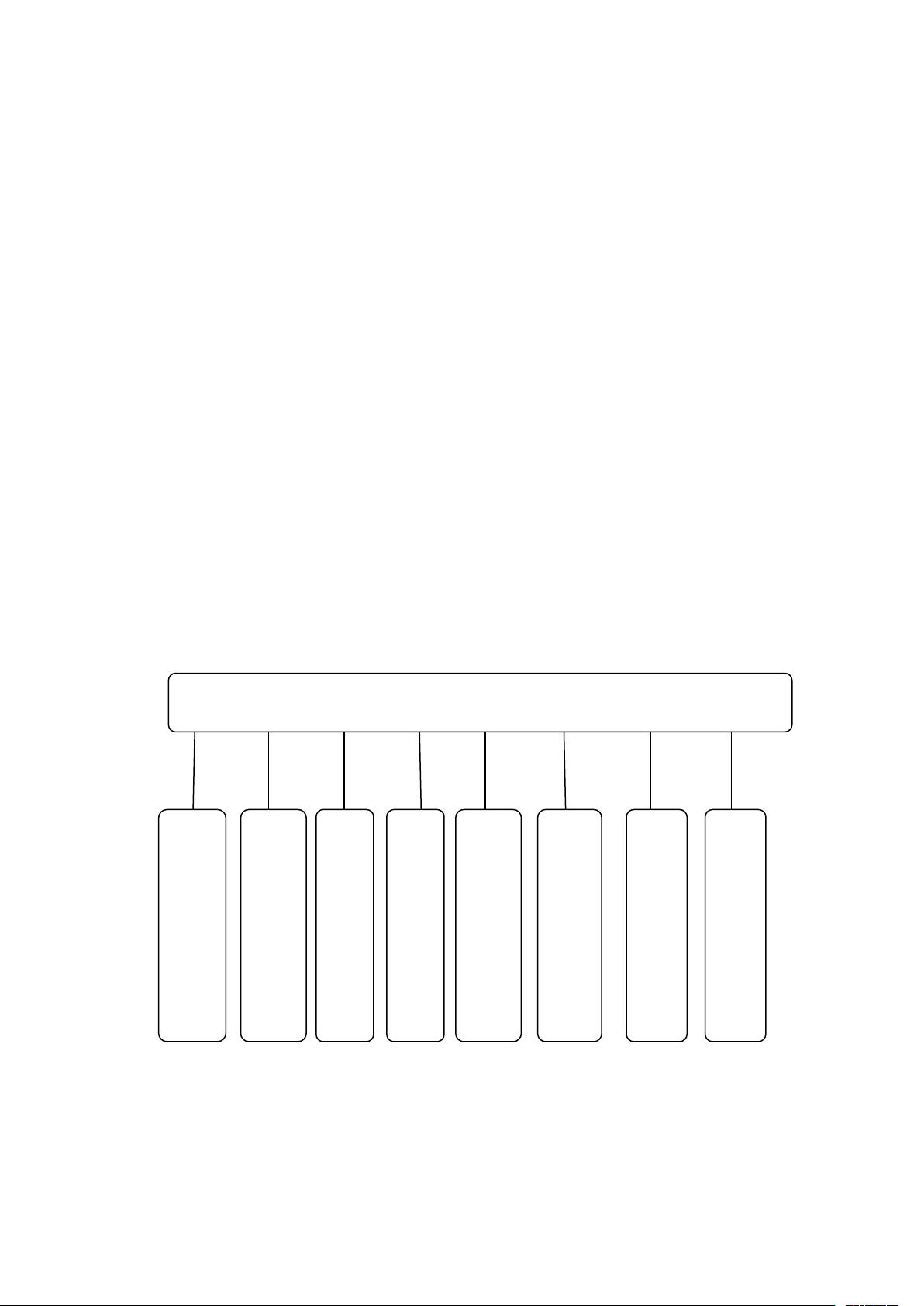
2.2 系统的组成及各模块的功能
2.3 系统的运行环境
《儒林外史》小说词频分析系统
主
菜
单
对
小
说
进
行
词
频
统
计
输
出
词
云
人
物
出
现
的
次
数
统
计
章
节
情
绪
分
析
统
计
段
落
字
数
统
计
人
物
共
现
关
系
统
计
退出
图 1 总体模块图

系统的运行环境为 Windows10 平台或 Windows7
使用语言为 Python3.8 或 Python3.9
3 系统设计
3.1 总体结构设计
将程序设计成菜单的方式工作,并利用 python 语言中常用的 for 循环、if 函数等
实现功能。
(1)词频统计功能
使用 os 库,打开小说文本文件,文件为空输出打开失败,如果文件编码格式读
出不正确输出显示读取文件失败。通过 read()函数将小说内容保存到 text 文本中。使
用 jieba 库将 text 进行中文词法分析,保存到列表 ls 中,然后用 for 循环统计列表中
的词频,并去掉一些虚词和无关词,进行结果修正。
(2)输出词云功能
首先通过函数传参方式传入小说文本,读入存在本地的背景图片,设置词云的参
数,包括字体、背景颜色、最大单词数量、词云形状、高度、间隔和装载的文本,然
后保存词云图片到本地,并使用 matplotlib 显示图片。
(3)章节情况
首先进行章回拆分,使用 os 库,打开小说文本文件,通过 read()函数将小说
内容保存到 text 文本中。然后创建一个空列表,通过 re 库来引用,再利用 for 循环来
统计小说的章回。然后在创建一个新的列表,再利用 for 循环进行章回分割。其次统
计哭笑悲喜的次数,在形成哭笑图。统计次数时,先建立新的列表,再利用 for 循环
统计哭笑悲喜次数,然后再通过引用 matplotlib.pyplot 来形成哭笑变化图。再其次,
统计人物的出场次数,先创建列表,然后通过 for 循环,再然后引用 matplotlib.pyplot
来形成每章人物出场次数图。最后是段落字数散点图。首先创建列表,然后使用 for
循环,再然后引用 matplotlib.pyplot,在通过 for 循环来统计每章节段落字数,最后形
成该散点图。
(4)人物关系图
首先生成人物关系权重,定义一个函数,在打开小说文本,建立一个关于小说人
物的列表,然后再使用 networkx 和 matplotlib,并且建立一个新字典以及一个新列表,
利用 for 循环来输出人物。再然后通过对字典内容进行比重分析。最后形成该小说主
要人物社交关系网络图。

4 系统实现
4.1 菜单和主程序的设计与实现
(1)主函数
try:
f=open('儒林外史.txt', "r",encoding='utf-8')
except IOError:
print("儒林外史.txt 文件不存在,请先创建!")
else:
text=getText('儒林外史.txt')
print("《儒林外史》:\n",text)
while 1:
menu()
x=int(input('请输入您要选择的功能号:'))
if x==0:
wordFreq('儒林外史.txt',text,50)
print('统计结束')
elif x==1:
outputwordcloud()
elif x==2:
chapsplit()
elif x==3:
relation()
elif x==4:
print()
print("已退出系统!")
break
(2)菜单函数
def menu():
print('*********************************************')
print('~ 班级:方 2311 班 ~')
print('~ 姓名: 杨 建 鑫 ~')
print('~ 学号: 20236529 ~')
print('~ ~')
print('//// 欢迎使用网络小说词频繁分析系统 /////')
print('~ [0] 统计词频 ~')
print('~ [1] 输出词云 ~')
print('~ [2] 统计章节情节 ~')
print('~ [3] 人物关系图 ~')
print('~ [4] 退出 ~')
print('*********************************************')

运行界面如图 2 所示。
4.2 词频统计功能
#文本读取
def getText(filepath):
f = open(filepath, "r",encoding='utf-8')
text = f.read()
f.close()
return text
#词频统计
import jieba
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
def wordFreq(filepath,text,topn):
words = jieba.lcut(text.strip())
counts = {}
stopwords = stopwordslist('stop_words.txt')
for word in words:
if len(word) == 1:
continue
elif word not in stopwords:
if word=="杜仪" or word=="呆子" or word=="败家子":
word="杜少卿"
图 2 菜单的实现界面













