XQuery AnXMLquerylanguage.pdf


XQuery:
An XML query
language
by D. Chamberlin
The World Wide Web Consortium has
convened a working group to design a query
language for Extensible Markup Language
(XML) data sources. This new query language,
called XQuery, is still evolving and has been
described in a series of drafts published by
the working group. XQuery is a functional
language comprised of several kinds of
expressions that can be nested and
composed with full generality. It is based on
the type system of XML Schema and is
designed to be compatible with other XML-
related standards. This paper explains the
need for an XML query language, provides a
tutorial overview of XQuery, and includes
several examples of its use.
Increasingly, Extensible Markup Language (XML)
1
is considered the format of choice for the exchange
of information among various applications on the
Internet. The popularity of XML is due in large part
to its flexibility for representing many kinds of in-
formation. The use of tags makes XML data self-de-
scribing, and the extensible nature of XML makes it
possible to define new kinds of documents for spe-
cialized purposes. As the importance of XML has in-
creased, a series of standards has grown up around
it, many of which were defined by the World Wide
Web Consortium (W3C).
2
For example, XML Sche-
ma
3
provides a notation for defining new types of
elements and documents; XML Path Language
(XPath)
4
provides a notation for selecting elements
within an XML document; and Extensible Stylesheet
Language Transformations (XSLT)
5
provides a no-
tation for transforming XML documents from one
representation to another.
XML makes it possible for applications to exchange
data in a standard format that is independent of stor-
age. For example, one application may use a native
XML storage format, whereas another may store data
in a relational database. Since XML is emerging as
a standard for data exchange, it is natural that que-
ries among applications should be expressed as que-
ries against data in XML format. This use gives rise
to a requirement for a query language designed ex-
pressly for XML data sources. In October 1999, W3C
convened the XML Query Working Group
6
for the
purpose of designing such a query language, to be
called XQuery.
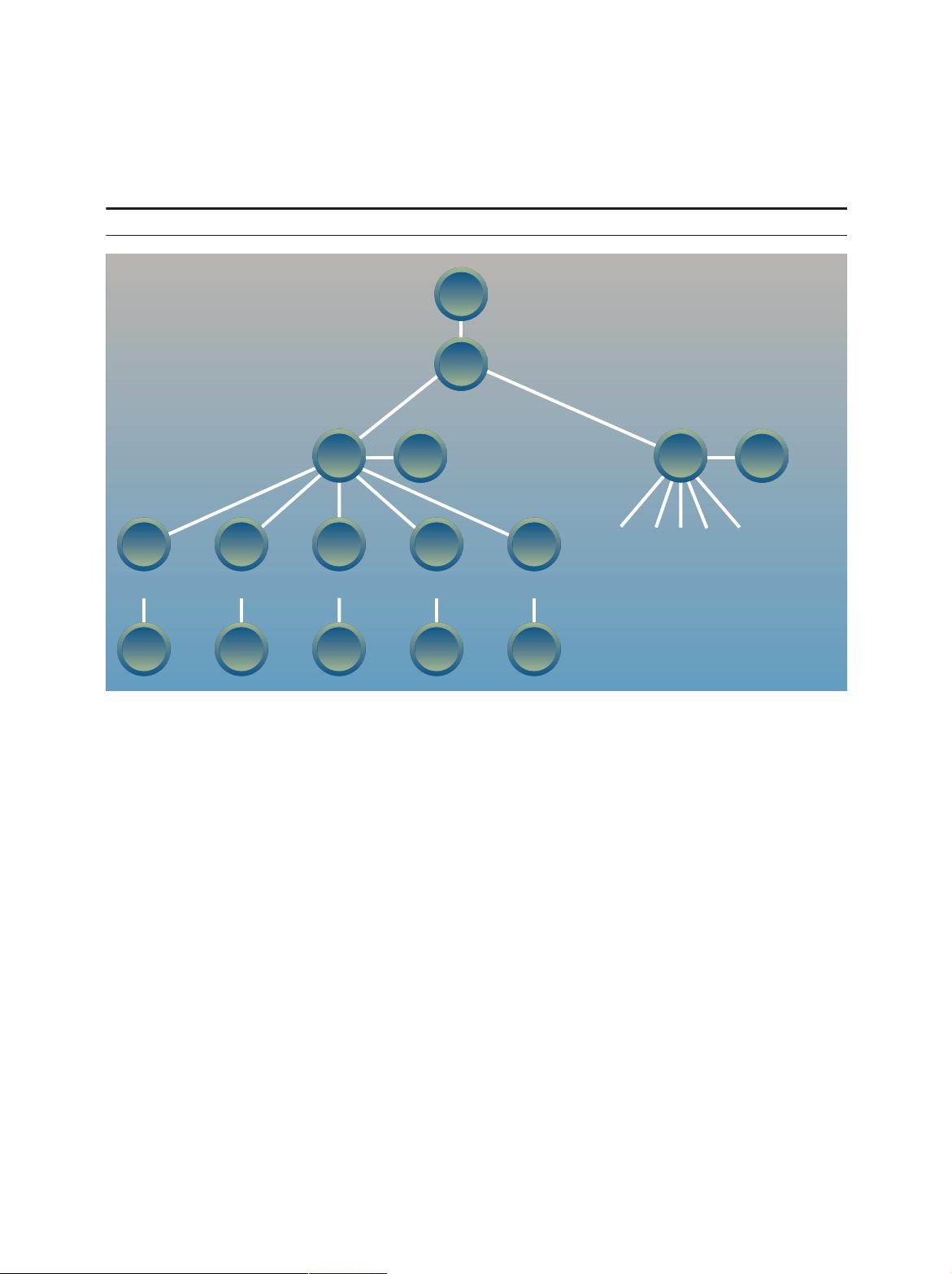
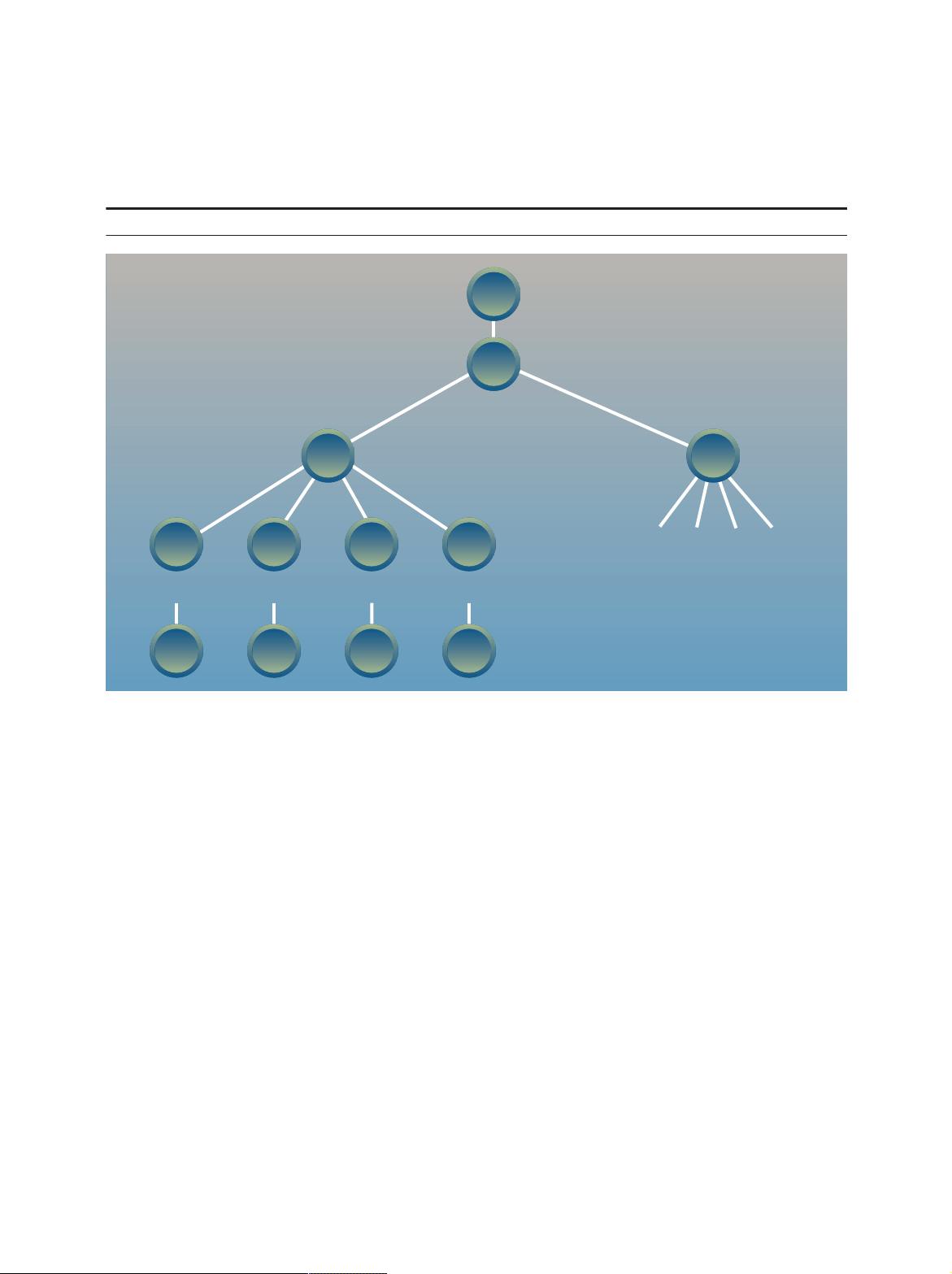
XML data are different from relational data in sev-
eral important respects that influence the design of
a query language. Relational data tend to have a reg-
ular structure, which allows the descriptive meta-data
for these data to be stored in a separate catalog. XML
data, in contrast, are often quite heterogeneous, and
distribute their meta-data throughout the document.
XML documents often contain many levels of nested
elements, whereas relational data are “flat.” XML
documents have an intrinsic order, whereas relational
data are unordered except where an ordering can
be derived from data values. Relational data are usu-
ally “dense” (nearly every column has a value), and
娀Copyright 2002 by International Business Machines Corpora-
tion. Copying in printed form for private use is permitted with-
out payment of royalty provided that (1) each reproduction is done
without alteration and (2) the Journal reference and IBM copy-
right notice are included on the first page. The title and abstract,
but no other portions, of this paper may be copied or distributed
royalty free without further permission by computer-based and
other information-service systems. Permission to republish any
other portion of this paper must be obtained from the Editor.
IBM SYSTEMS JOURNAL, VOL 41, NO 4, 2002 0018-8670/02/$5.00 © 2002 IBM CHAMBERLIN
597

剩余18页未读,继续阅读













评论1