Linux服务器性能优化最佳实践
需积分: 50 30 浏览量
2018-04-24
10:13:04
上传
评论 2
收藏 1.11MB PDF 举报


1/26
性能优化
了解调优
调优的目的:
1. 根据不同的角色调优的方法是不一样的
2. 找到性能瓶颈以及缓解这个瓶颈(CPU,内存,IO调度、网络、使用的应用程序)
3. 通常做两种调优:
response time: Web服务器,用户感受度好
throughput: 文件服务器,拷贝的速度
调优需要掌握的技能:
1. 必须了解硬件和软件
2. 能够把所有的性能、指标量化,用数字说话
3. 设置一个正常期待值,比如将响应速度调到1.5秒
(企业版操作系统在出厂时已经调优,适用于普遍的应用,再根据个人的环境进行微调)
4. 建议有一定的开发能力
5. 如果想要更好的调优,让调优有艺术性,需要更多的经验的积累,从而有一定洞察力,调节时所给参数才最恰当
性能调优的效率问题:
业务级调优 尽量在业务级调,效果最明显,例如: 网站一定要使用Apache吗?
例如:将原有的调度器由LVS换成F5-BigIP
能否禁用一些不必要的服务如蓝牙、smart card,makewathis, updatadb
应用级调优 NFS,Samba,Apache、Nginx、MySQL、Oracle、LVS本身调优
对于日志的处理: 只要有日志产生,就会存盘fsync(),可以调整记录的日志等级或延
后日志写,
从而避免大量的I/O操作
kernel级调优 最后的希望,kernel调优具有普遍性
自上往下,效果越来越不明显
=================================================================================
获取硬件信息
获得硬件信息
=================================================================================
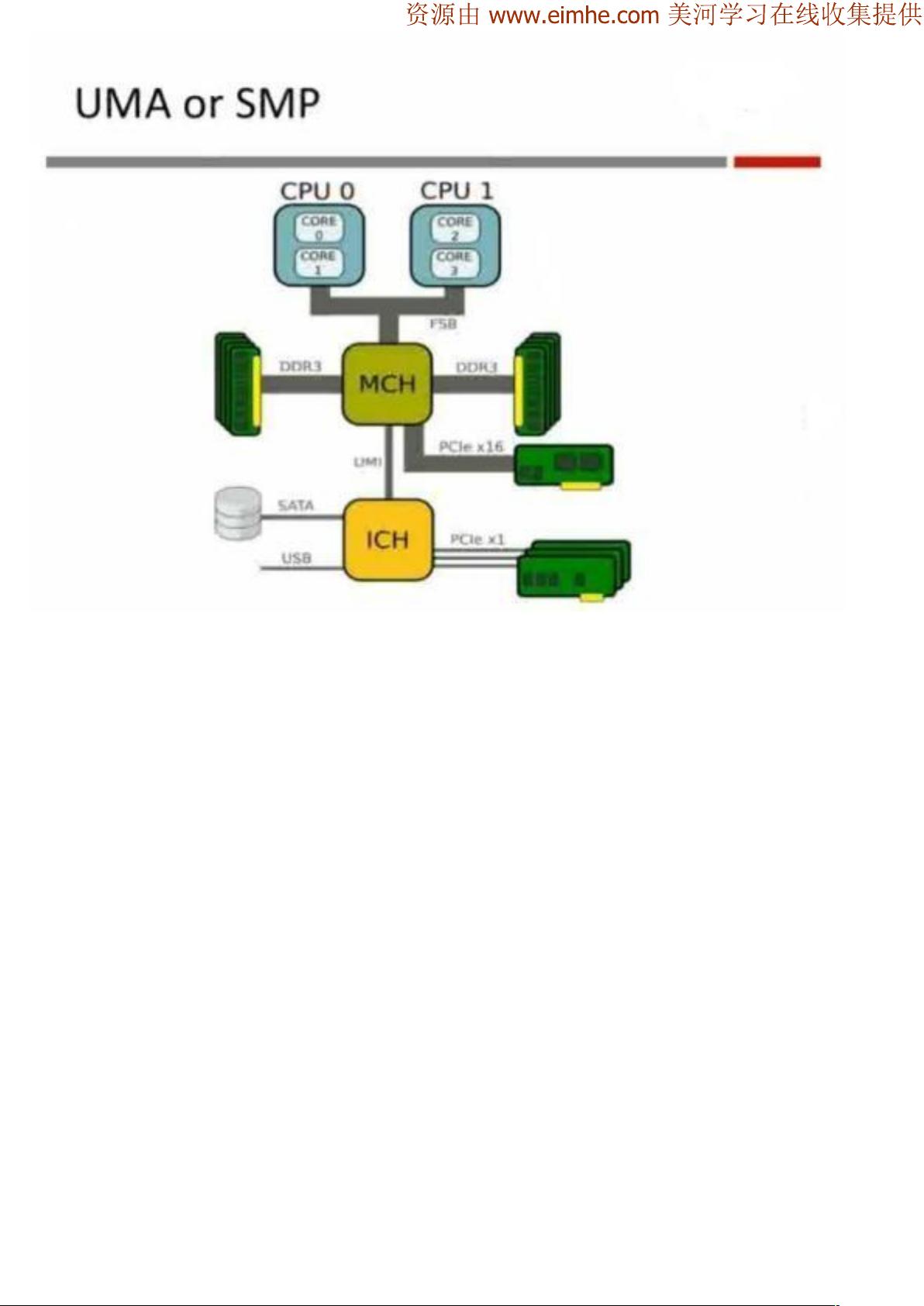
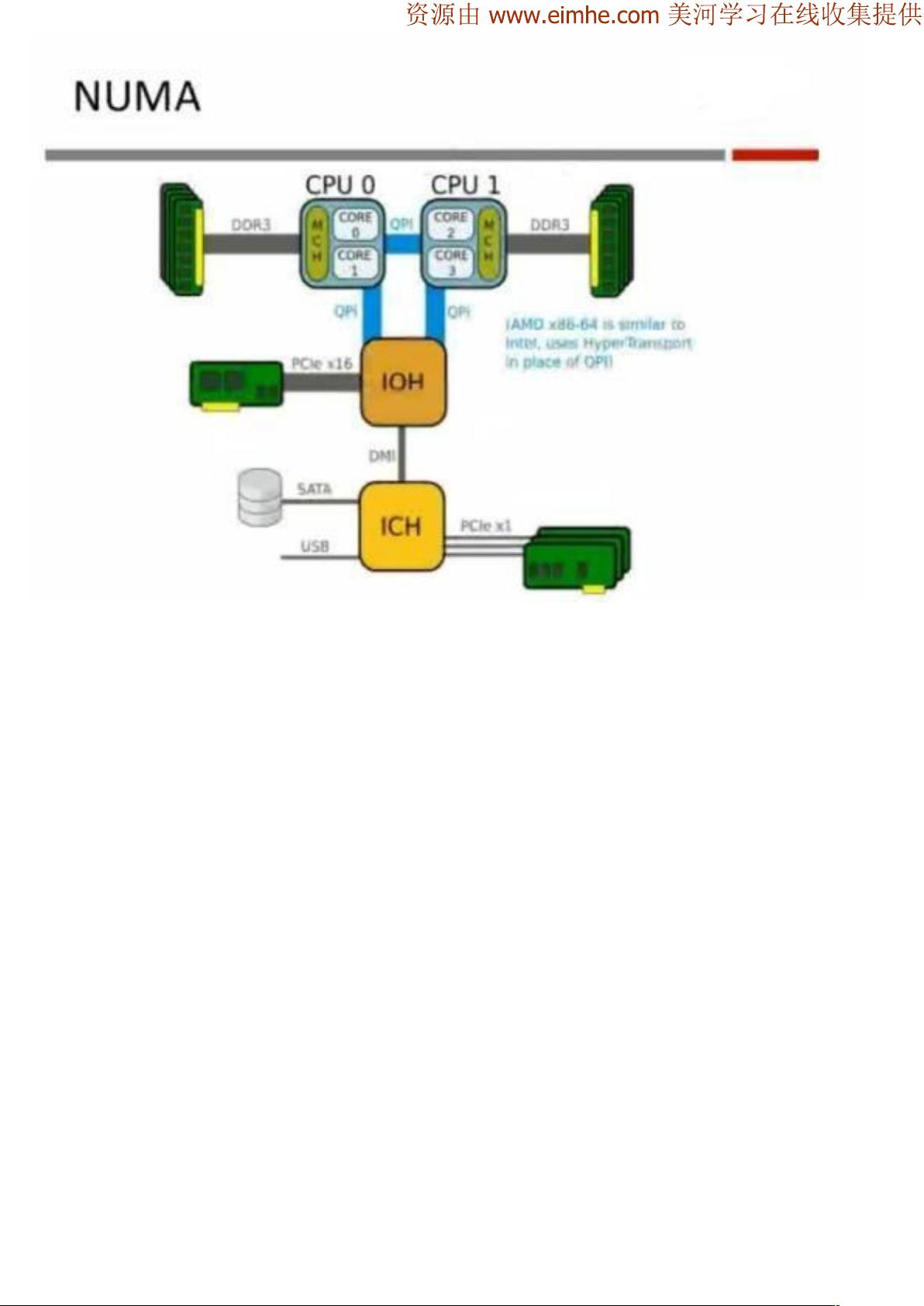
硬件方面,主要要调优的对象
CPU
Memory
Storage
Networking
获取硬件信息的命令
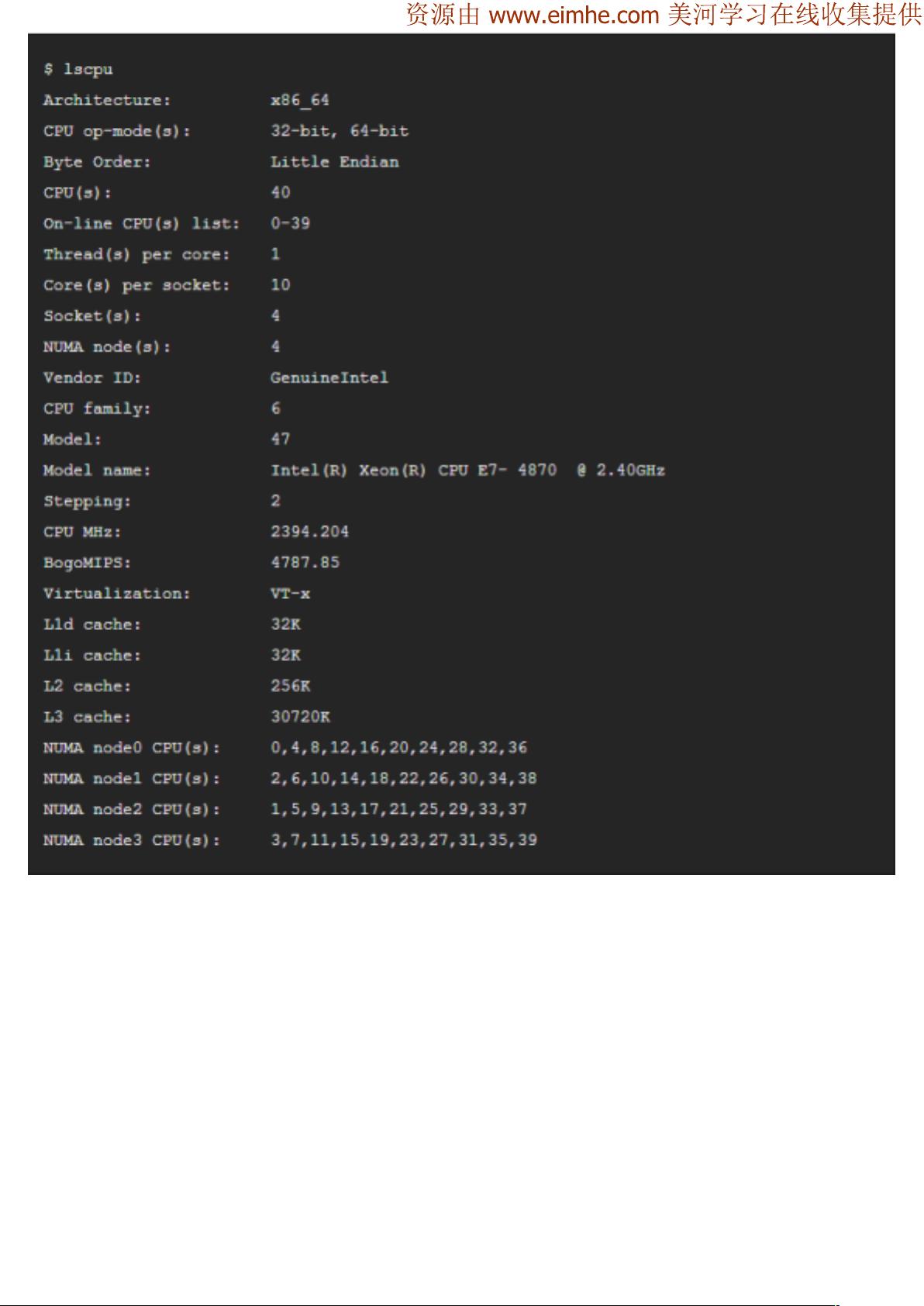
查看CPU:
RHEL7
lscpu,lscpu -p
查看硬件的顶级命令: 会读BIOS
dmidecode 直接查BIOS信息
dmidecode -t 0 type 0主要是硬件信息
查看服务器型号:dmidecode | grep 'Product Name'
查看主板的序列号:dmidecode |grep 'Serial Number'
查看系统序列号:dmidecode -s system-serial-number
查看cpu信息: 使用dmidecode -t 4
查看内存信息:dmidecode -t memory
查看最大支持内存数:dmidecode -t memory |grep "Maximum Capacity"
[root@SC4304 ~]# dmidecode -t 16
# dmidecode 2.11
# SMBIOS entry point at 0xb89a5000

剩余25页未读,继续阅读
资源评论













