哈夫曼树 课程设计 实验报告

一、需求分析
1、理论背景
以哈弗曼树─即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。 在
计算机信息处理中,“哈夫曼编码”是一种一致性编码法(又称"熵编码法"),用于数据的无
损耗压缩。这一术语是指使用一张特殊的编码表将源字符(例如某文件中的一个符号)进
行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来
的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编
码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。这种方法是由
David.A.Huffman 发展起来的。 例如,在英文中,e 的出现概率很高,而 z 的出现概率则最
低。当利用哈夫曼编码对一篇英文进行压缩时,e 极有可能用一个位(bit)来表示,而 z 则可
能花去 25 个位(不是 26) 。用普 通的表 示方法 时,每 个英文 字母均 占用一 个字节
(byte),即 8 个位。二者相比,e 使用了一般编码的 1/8 的长度,z 则使用了 3 倍多。倘若
我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的
比例。
2、功能需求
将任意指定的文本文件中的字符统计后,按 Huffman 编码方式对文件进行编码,并保存
码表及建立的 Huffman 树;用给定的码表对用 Huffman 方式编码的文件进行压缩和解压缩。
二、概要设计
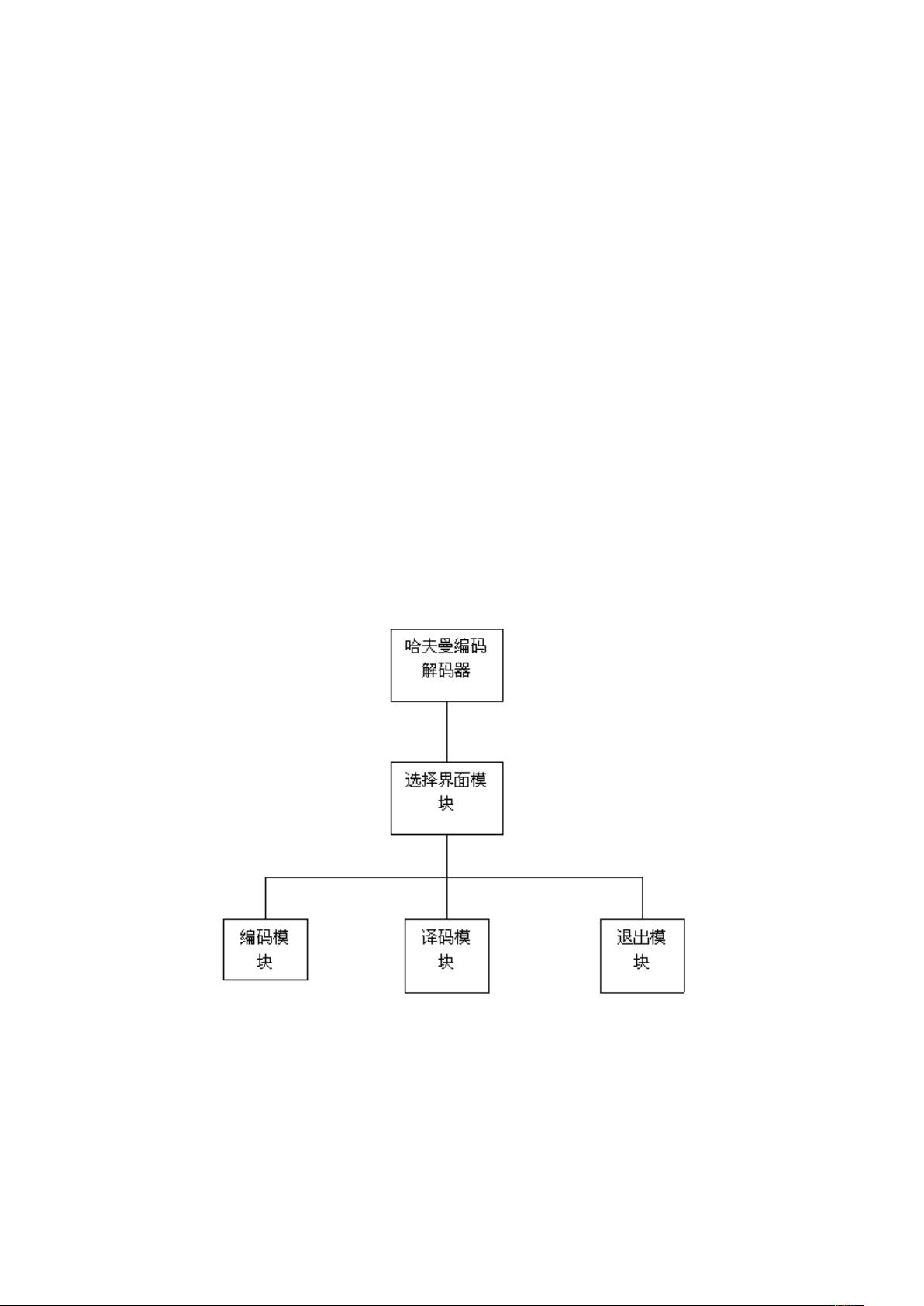
1.模块分解
2.模块功能说明
编码:读取默认源文件→统计字符及其频数做权值→建立哈弗曼树→对文本进行哈弗曼编
码并输出编码→保存到默认编码文件;
译码:打开默认文件→利用建立好的哈弗曼树进行译码→将译码输出→保存到默认的译码
文件;
退出:退出系统,程序运行结束。
资源评论

 radolf2013-11-20挺不错的 值得参考
radolf2013-11-20挺不错的 值得参考- qq_582061782021-12-24lj啥也不是











