毕业设计 一种改进的自适应滤波LMS算法的matlab实现


一、综述
自适应滤波是近 30 年以来发展起来的 一种最佳滤波方法。它是在维纳滤波,
kalman 滤波等线性滤波基础上发展起来的一种最佳滤波方法。由于它具有更
强的适应性和更优的滤波性能。从而在工程实际中,尤其在信息处理技术中得
到广泛的应用。自适应滤波的研究对象是具有不确定的系统或信息过程。“不确
定”是指所研究的处理信息过程及其环境的数学模型不是完全确定的。其中包含
一些未知因数和随机因数。任何一个实际的信息过程都具有不同程度的不确定
性,这些不确定性有时表现在过程内部,有时表现在过程外部。从过程内部来
讲,描述研究对象即信息动态过程的数学模型的结构和参数是我们事先不知道
的。作为外部环境对信息过程的影响,可以等效地用扰动来表示,这些扰动通
常是不可测的,它们可能是确定的,也可能是随机的。此外一些测量噪音也是
以不同的途径影响信息过程。这些扰动和噪声的统计特性常常是未知的。面对
这些客观存在的各种不确定性,如何综合处理信息过程,并使某一些指定的性
能指标达到最优或近似最优,这就是自适应滤波所要解决的问题。
二、 自适应滤波器的基本原理
所谓的自适应滤波,就是利用前一时刻以获得的滤波器参数的结果,自动的
调节现时刻的滤波器参数,以适应信号和噪声未知的或随时间变化的统计特性,
从而实现最优滤波。自适应滤波器实质上就是一种能调节其自身传输特性以达
到最优的维纳滤波器。自适应滤波器不需要关于输入信号的先验知识,计算量
小,特别适用于实时处理。由于无法预先知道信号和噪声的特性或者它们是随
时间变化的,仅仅用 FIR 和 IIR 两种具有固定滤波系数的滤波器无法实现最优
滤波。在这种情况下,必须设计自适应滤波器,以跟踪信号和噪声的变化。
自适应滤波器的特性变化是由自适应算法通过调整滤波器系数来实现的。一般
而言,自适应滤波器由两部分组成,一是滤波器结构,二是调整滤波器系数的
自适应算法。自适应滤波器的结构采用 FIR 或 IIR 结构均可,由于 IIR 滤波器存
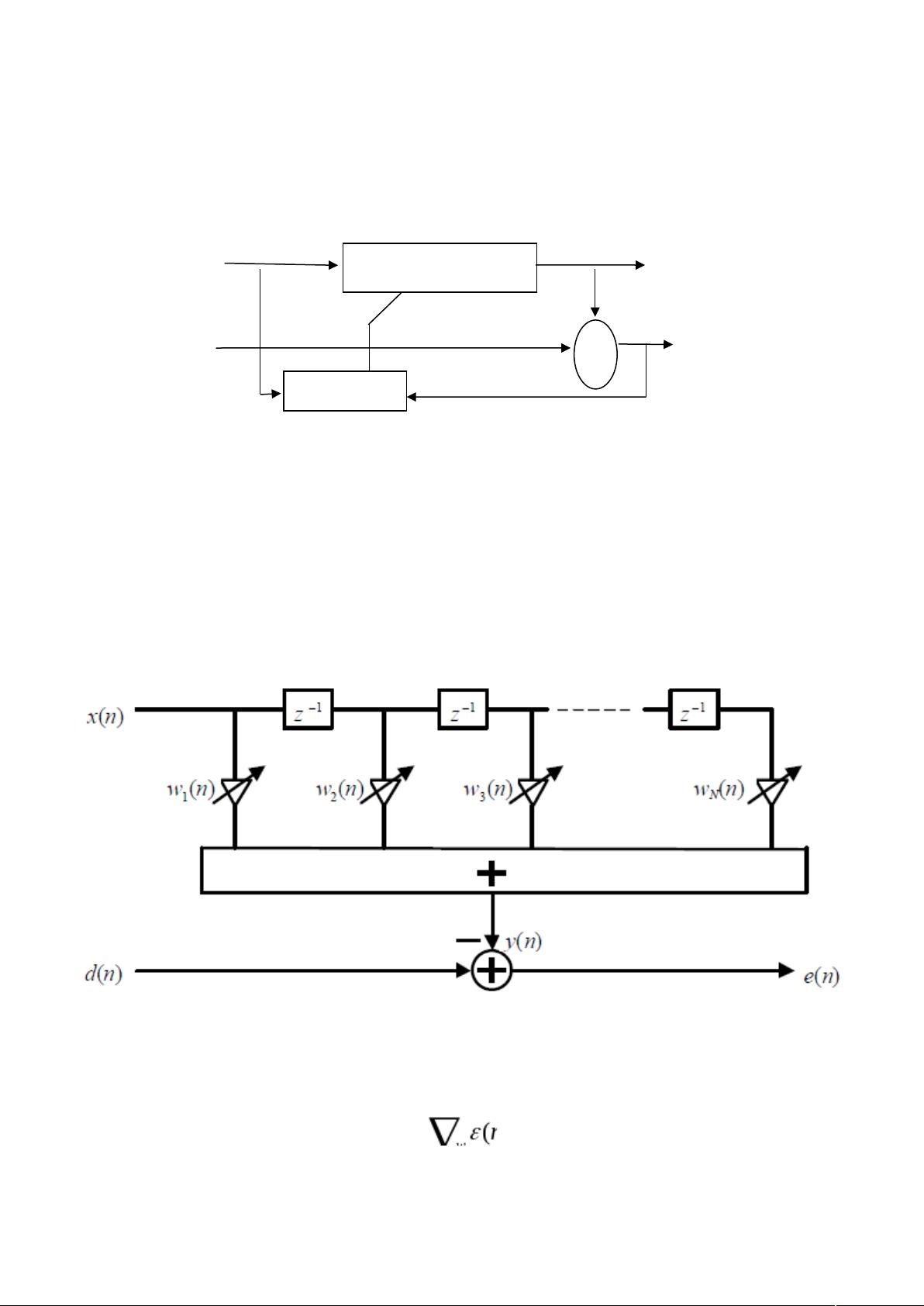
在稳定性问题,因此一般采用 FIR 滤波器作为自适应滤波器的结构。图 1 示出
了自适应滤波器的一般结构。
图 1 中,x(n)为输入信号,y(n)为输出信号,d(n)为参考信号或期望信号,
1


剩余18页未读,继续阅读
资源评论

 脑海里的橡皮檫2015-05-24还不错,可以参考参考。
脑海里的橡皮檫2015-05-24还不错,可以参考参考。- theone1111112012-10-18条理清晰,可惜不是我想要的
- shiww2272012-11-26理解的还是蛮透彻的 但是我要的不是这个 = =
- Good_luck_mf2014-11-26理论学习不错











