### Hadoop编程思想
#### Hadoop架构
Hadoop的核心组件包括**Hadoop Distributed File System (HDFS)** 和 **MapReduce**。Hadoop架构主要由以下几个关键部分组成:
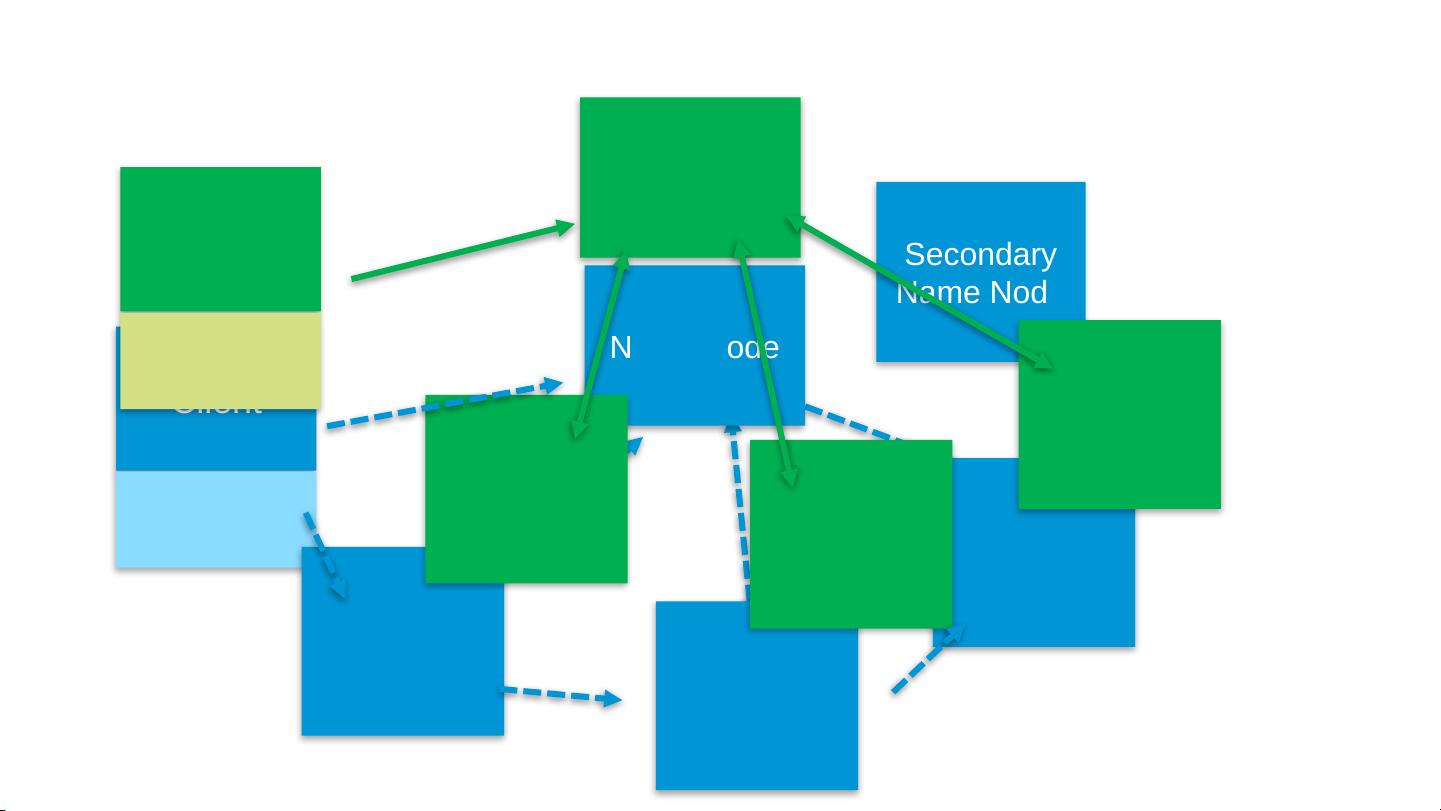
- **NameNode**: 存储元数据(metadata),如文件系统命名空间(文件名、目录名等)和访问控制列表等信息,并负责管理文件系统的命名空间。
- **Secondary NameNode**: 不是集群中的NameNode的备份,而是一种辅助角色,帮助NameNode合并编辑日志,减少启动时间。
- **DataNode**: 存储实际的数据块,响应客户端或NameNode的请求。
- **JobTracker**: MapReduce作业调度器,负责接收作业提交,调度任务到TaskTracker上执行,并跟踪它们的状态。
- **TaskTracker**: 接受来自JobTracker的任务,执行这些任务并将结果写回磁盘。
#### Hadoop文件系统
Hadoop文件系统(HDFS)是一种分布式文件系统,设计用于在大规模集群环境中存储大量数据。HDFS具有以下特点:
- **高容错性**: 数据自动复制到多个节点,以防止单点故障。
- **可扩展性**: 可以轻松地添加更多节点来扩展存储容量。
- **简单的数据模型**: 文件被分割成块(默认大小为64MB),每个块尽可能存储在网络中的不同节点上。
HDFS的关键组成部分包括:
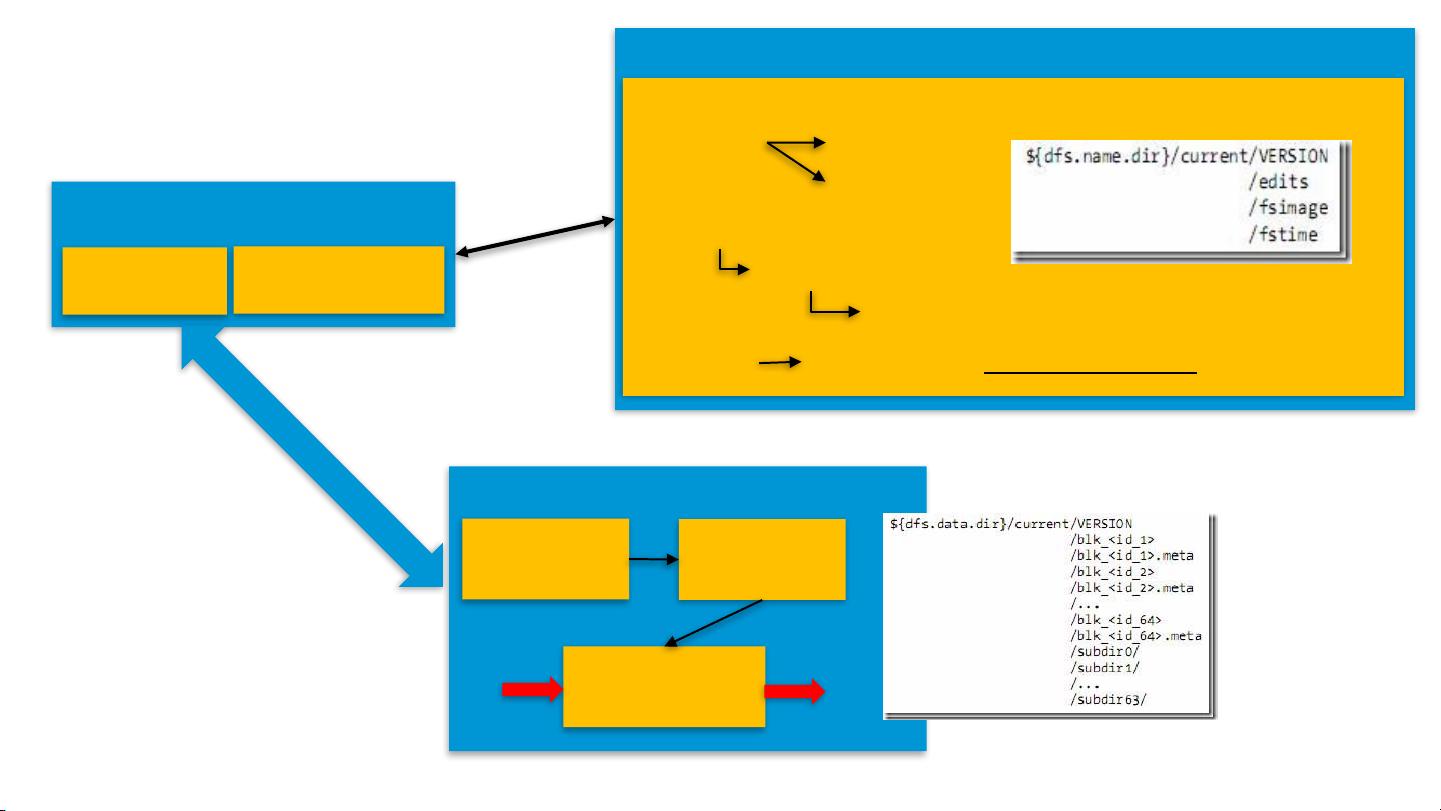
- **FSNamesystem**: 包含文件系统的所有元数据。
- **FSDirectory**: 文件系统的目录结构。
- **FSImage**: 存储文件系统的当前状态。
- **FSEditLog**: 记录对文件系统进行的所有更改操作。
- **INodeDirectory/INodeFile**: 分别代表目录和文件的信息,包含指向具体数据块的引用。
- **BlocksMap**: 映射数据块到相应的文件节点。
#### Map-Reduce
MapReduce是一种用于处理和生成大型数据集的编程模型,它通过将任务分解成一系列简单的映射(Map)和归约(Reduce)步骤来实现。
- **概念1:分而治之**:将大数据集分割成小块并分配给不同的处理器进行处理。
- **概念2:数据绑定到处理器**:数据被存储在处理节点附近以减少网络延迟。
MapReduce的工作流程如下:
1. **问题识别与逻辑过程**:首先明确要解决的问题,例如处理天气数据,提取每年的平均温度。
2. **逻辑设计**:定义Map函数和Reduce函数。Map函数处理输入数据的每个键值对,并生成一组中间键值对;Reduce函数接受相同中间键的所有值,并产生最终输出。
- **Map**阶段示例:根据天气数据的格式(每行一条记录,第15-18个字符为年份,第25-29个字符为温度)解析数据,生成年份作为键,温度作为值的键值对。
- **Reduce**阶段示例:对每个年份的温度求平均值,输出年份及其平均温度。
#### 大数据案例
本节将通过一个具体的案例——处理天气数据,进一步理解MapReduce的工作原理。
**原始数据**:每行一条记录,每行字符从0开始计数,第15-18个字符为年份,第25-29个字符为温度,其中第25位是符号+/-。
**Map阶段输出**:(1950, [0, 22, –11]),(1949, [111, 78])
**Reduce阶段输出**:(1950, 平均温度),(1949, 平均温度)
#### 调试与性能分析
在开发Hadoop应用程序时,调试和性能优化非常重要。这通常涉及到以下步骤:
- 使用日志和监控工具监控程序运行状态。
- 分析任务执行时间和资源消耗。
- 通过增加节点或优化代码提高性能。
#### 结论
Hadoop及其核心组件HDFS和MapReduce提供了强大的工具来处理大数据集。通过理解其架构、文件系统以及MapReduce的工作原理,开发者可以有效地利用这些工具解决复杂的大数据问题。