






编译方法实验报告
姓 名 李亚方 学 号
20080931
班 级 软一0801 指 导 教 师 高健
实 验 名 称 扫描器设计
开 设 学 期 20 10 -20 11 第二学 期
实 验 时 间 第 16 周
评 定 成 绩
评定人签 字
评 定 日 期
东北大学软件学院
2011年1月
实验目的
(1) 熟悉并实现一个扫描器(词法分析程序);
(2) 掌握如何设计扫描器的有限自动机(识别器);
(3) 熟悉翻译、生成 Token 的算法(翻译器);
(4) 了解扫描器、识别器、翻译器三者之间的关系;
(5) 掌握有限自动机及词法分析器原理;
(6) 加深对课堂讲授内容的理解,了解编译程序的基本结构;
(7) 学习并掌握编译程序的相关实现技术:如设计扫描器的自动机、设计翻译及生成 Token
的算法;
(8) 熟悉算术表达式的语法分析与中间代码生成原理。
实验内容
(1) 设计扫描器的有限自动机(识别器);
(2) 设计翻译、生成 Token 的算法(翻译器);
(3) 编写代码并上机调试运行通过。
·输入——源程序文件或源程序字符串;
·输出——相应的 Token 序列;
关键字表和界符表;
符号表和常数表;
实验原理及基本步骤
(1)词法分析程序又称扫描器,任务有两个:
a.识别单词——从用户的源程序中把单词分离出来;
b.翻译单词——把单词转换成机内表示,便于后续处理。
即: 单词 Token
(2)有限自动机的状态转换图:
扫描器
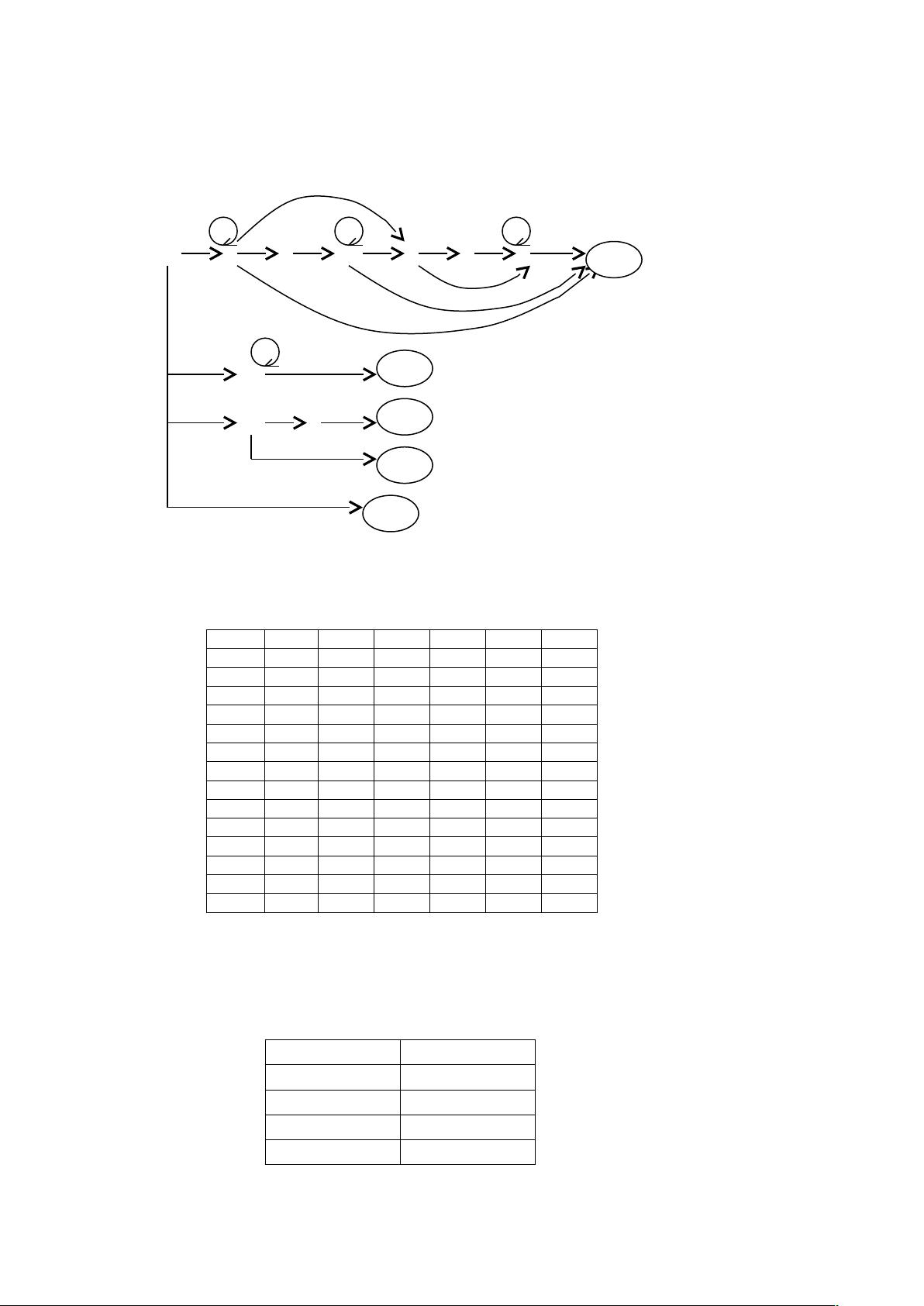
e
d d d
+|- -1/+/-
+ ① d ② . ③ d ④ e ⑤ ⑥ d ⑦
d -
-1/+/-
l/d -1/+/-
-1
l ⑧ -
-1
b ⑨ b ⑩ -
-1
-
-1
-
其中:d 为数字,l 为字母,b 为界符,-1 代表其它符号(如在状态 8 处遇到了非字母或数
字的其它符号,会变换到状态 12)。
(3)状态转换矩阵:
d · E|e +|- l b -1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
(2) 关键字表和界符表
Program ;
Begin :
End (
Var )
While ,
2 8 9 15
2 3 5 11 11
4
4 5 11 11
7 6
7
7 11 11
8 8 12
10 14
15 13
12
11
13
1
4
15

Do :=
Repeat +
Until -
For *
To /
If >
Then >=
Else ==
<
<=
数据结构设计
① 状态转换矩阵:int aut[10][7]={ 2, 0, 0, 0, 8, 9, 15,
2, 3, 5,11, 0, 0, 11,
4, 0, 0, 0, 0, 0, 0,
4, 0, 5,11, 0, 0, 11,
7, 0, 0, 6, 0, 0, 0,
7, 0, 0, 0, 0, 0, 0,
7, 0, 0,11, 0, 0, 11,
8, 0, 0, 0, 8, 0, 12,
0, 0, 0, 0, 0, 10, 14,
0, 0, 0, 0, 0, 0, 13};
② 关键字表:
char keywords[30][12]={“program”,”begin”,”end”,”var”,”while”,”do”,
”repeat”,”until”,”for”,”to”,”if”,”then”,”else”, “;”, ”:”, ”(“, ”)”, ”,”,
”:=”, ”+”, ”-“, ”*”, ”/”,
”>”, ”>=”, ”==”, “<”, “<=”};
③ 符号表:char ID[50][12]; //表中存有源程序中的标识符
④ 常数表:float C[20];
⑤ 其它变量: struct token
{ int code;
int value}; //Token 结构
struct token tok[100]; //Token 数组
int s; //当前状态
int n,p,m,e,t; //尾数值,指数值,小数位数,指数符号,类型
float num; //常数值
char w[50]; //源程序缓冲区
int i; //源程序指针,当前字符为 w[i]
char strTOKEN[12]; //当前已经识别出的单词
(4) 语义动作:

·q
1
:n=m=p=t=0; e=1; num=0; 其它变量初始化;
·q
2
:n=10*n+(w[i]);
·q
3
:t=1;
·q
4
:n=10*n+( w[i]); m++;
·q
5
:t=1;
·q
6
:if ‘-‘ then e=-1;
·q
7
:p=10*p+(w[i]);
·q
8
:将 w[i]中的符号拼接到 strTOKEN 的尾部;
·q
9
:将 w[i]中的符号拼接到 strTOKEN 的尾部;
·q
10
:将 w[i]中的符号拼接到 strTOKEN 的尾部;
//标识符的编码为 1,值为其在常数表中的位置;常数的编码为 2,值为其在符号表中的
位置;关键字和界符的编码为其在关键字表中的位置,值为 0。
·q
11
:num=n*10
e*p-m
; //计算常数值
t[i].code=2; t[i].value=InsertConst(num); //生成常数 Token
·q
12
:code=Reserve(strTOKEN); //查关键字表
if code then { t[i].code=code; t[i].value=0; } //生成关键字 Token
else {t[i].code=1; t[i].value=InsertID(strTOKEN); }
//生成标识符 Token
·q
13
:code=Reserve(strTOKEN); //查界符表
if code then { t[i].code=code; t[i].value=0; } //生成界符 Token
else {
strTOKEN[strlen(strTOKEN)-1]=’\0’; //单界符
源程序缓冲区指针减 1;
code=Reserve(strTOKEN); //查界符表
t[i].code=code; t[i].value=0; //生成界符 Token
}
·q
14
:code=Reserve(strTOKEN); //查界符表
t[i].code=code; t[i].value=0; //生成界符 Token
·q
15
:stop.
(5) 查状态变换表
int find(int s,char ch) //s 是当前状态,ch 是当前字符,返回值是转换后状态
{
查状态转换矩阵 aut[10][7];
返回新状态;
}
(6) 主程序流程:
初始化;
打开用户源程序文件;
while (文件未结束{ 读入一行到 w[i],i=0;
do //处理一行,每次处理一个单词
{ 滤空格,直到第一个非空的 w[i];
i--;
s=1; //处理一个单词开始
while (s!=0) //拼单词并生成相应 Token













