A multilinear singular value decomposition.pdf


A MULTILINEAR SINGULAR VALUE DECOMPOSITION
∗
LIEVEN DE LATHAUWER
†
, BART DE MOOR
†
, AND JOOS VANDEWALLE
†
SIAM J. M
ATRIX ANAL. APPL.
c
2000 Society for Industrial and Applied Mathematics
Vol. 21, No. 4, pp. 1253–1278
Abstract. We discuss a multilinear generalization of the singular value decomposition. There is
a strong analogy between several properties of the matrix and the higher-order tensor decomposition;
uniqueness, link with the matrix eigenvalue decomposition, first-order perturbation effects, etc., are
analyzed. We investigate how tensor symmetries affect the decomposition and propose a multilinear
generalization of the symmetric eigenvalue decomposition for pair-wise symmetric tensors.
Key words. multilinear algebra, singular value decomposition, higher-order tensor
AMS subject classifications. 15A18, 15A69
PII. S0895479896305696
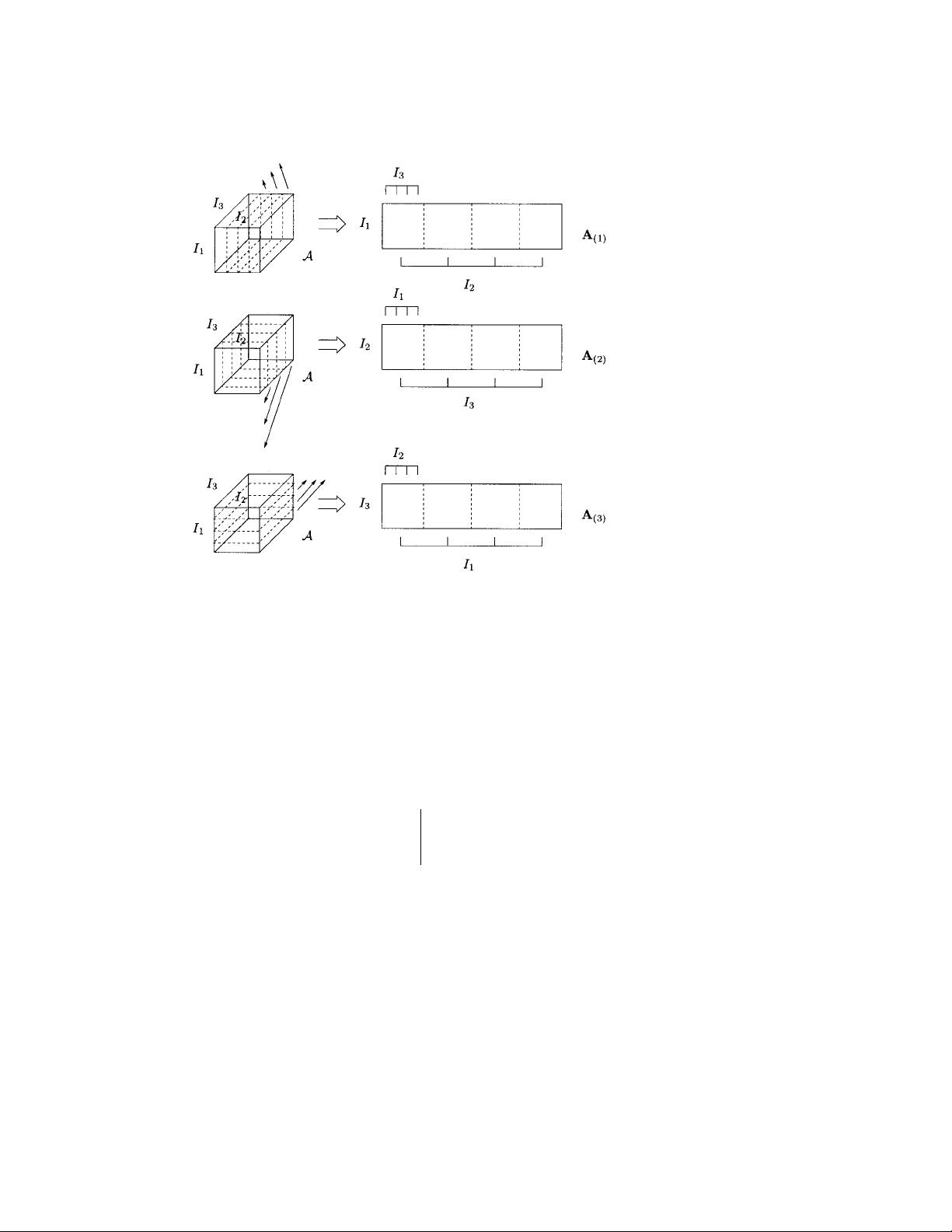
1. Introduction. An increasing number of signal processing problems involve
the manipulation of quantities of which the elements are addressed by more than
two indices. In the literature these higher-order equivalents of vectors (first order)
and matrices (second order) are called higher-order tensors, multidimensional matri-
ces, or multiway arrays. For a lot of applications involving higher-order tensors, the
existing framework of vector and matrix algebra appears to be insufficient and/or
inappropriate. In this paper we present a proper generalization of the singular value
decomposition (SVD).
To a large extent, higher-order tensors are currently gaining importance due to the
developments in the field of higher-order statistics (HOS): for multivariate stochastic
variables the basic HOS (higher-order moments, cumulants, spectra and cepstra) are
highly symmetric higher-order tensors, in the same way as, e.g., the covariance of a
stochastic vector is a symmetric (Hermitean) matrix. A brief enumeration of some
opportunities offered by HOS gives an idea of the promising role of higher-order
tensors on the signal processing scene. It is clear that statistical descriptions of random
processes are more accurate when, in addition to first- and second-order statistics, they
take HOS into account; from a mathematical point of view this is reflected by the fact
that moments and cumulants correspond, within multiplication with a fixed scalar,
to the subsequent coefficients of a Taylor series expansion of the first, resp., second,
characteristic function of the stochastic variable. In statistical nonlinear system theory
HOS are even unavoidable (e.g., the autocorrelation of x
2
is a fourth-order moment).
∗
Received by the editors June 24, 1996; accepted for publication (in revised form) by B. Kagstrom
January 4, 1999; published electronically April 18, 2000. This research was partially supported by
the Flemish Government (the Concerted Research Action GOA-MIPS, the FWO (Fund for Scientific
Research - Flanders) projects G.0292.95, G.0262.97, and G.0240.99, the FWO Research Communi-
ties ICCoS (Identification and Control of Complex Systems) and Advanced Numerical Methods for
Mathematical Modelling, the IWT Action Programme on Information Technology (ITA/GBO/T23)-
IT-Generic Basic Research), the Belgian State, Prime Minister’s Office - Federal Office for Scientific,
Technical and Cultural Affairs (the Interuniversity Poles of Attraction Programmes IUAP P4-02 and
IUAP P4-24) and the European Commission (Human Capital and Mobility Network SIMONET,
SC1-CT92-0779). The first author is a post-doctoral Research Assistant with the F.W.O. The sec-
ond author is a senior Research Associate with the F.W.O. and an Associate Professor at the K.U.
Leuven. The third author is a Full Professor at the K.U. Leuven. The scientific responsibility is
assumed by the authors.
http://www.siam.org/journals/simax/21-4/30569.html
†
K.U. Leuven, E.E. Dept., ESAT–SISTA/COSIC, Kard. Mercierlaan 94, B-3001 Leuven (Hever-
lee), Belgium (Lieven.DeLathauwer@esat.kuleuven.ac.be, Bart.DeMoor@esat.kuleuven.ac.be, Joos.
Vandewalle@esat.kuleuven.ac.be).
1253



剩余26页未读,继续阅读
资源评论

 liuguohua8072014-05-09非常好,很好的一篇文献,正是我需要的
liuguohua8072014-05-09非常好,很好的一篇文献,正是我需要的











