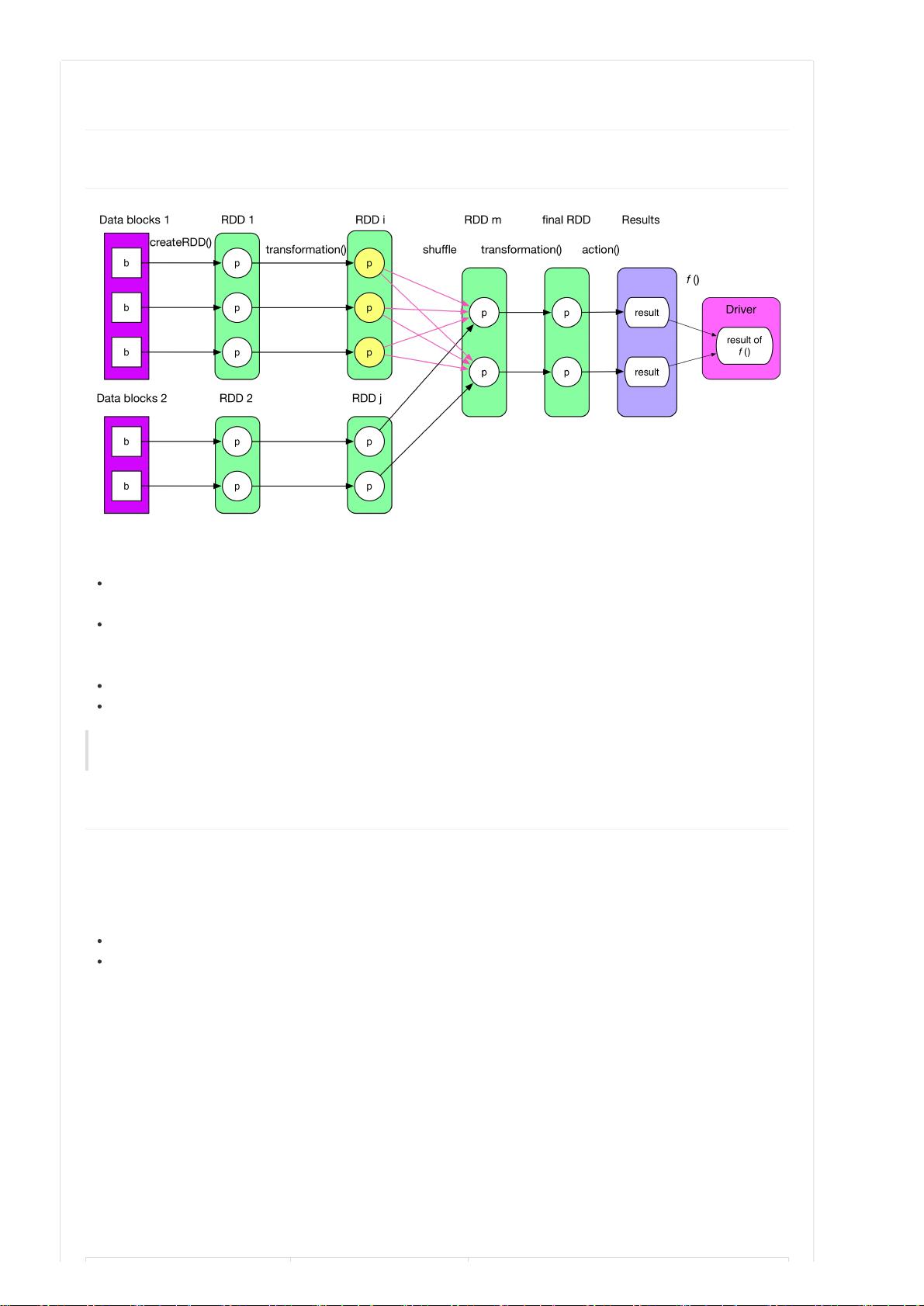
典型的 Job 逻辑执行图如上所示,经过下面四个步骤可以得到最终执行结果:
从数据源(可以是本地 file,内存数据结构, HDFS,HBase 等)读取数据创建最初的 RDD。上一章例子中的
parallelize() 相当于 createRDD()。
对 RDD 进行一系列的 transformation() 操作,每一个 transformation() 会产生一个或多个包含不同类型 T 的 RDD[T]。
T 可以是 Scala 里面的基本类型或数据结构,不限于 (K, V)。但如果是 (K, V),K 不能是 Array 等复杂类型(因为难以
在复杂类型上定义 partition 函数)。
对最后的 final RDD 进行 action() 操作,每个 partition 计算后产生结果 result。
将 result 回送到 driver 端,进行最后的 f(list[result]) 计算。例子中的 count() 实际包含了action() 和 sum() 两步计算。
RDD 可以被 cache 到内存或者 checkpoint 到磁盘上。RDD 中的 partition 个数不固定,通常由用户设定。RDD 和
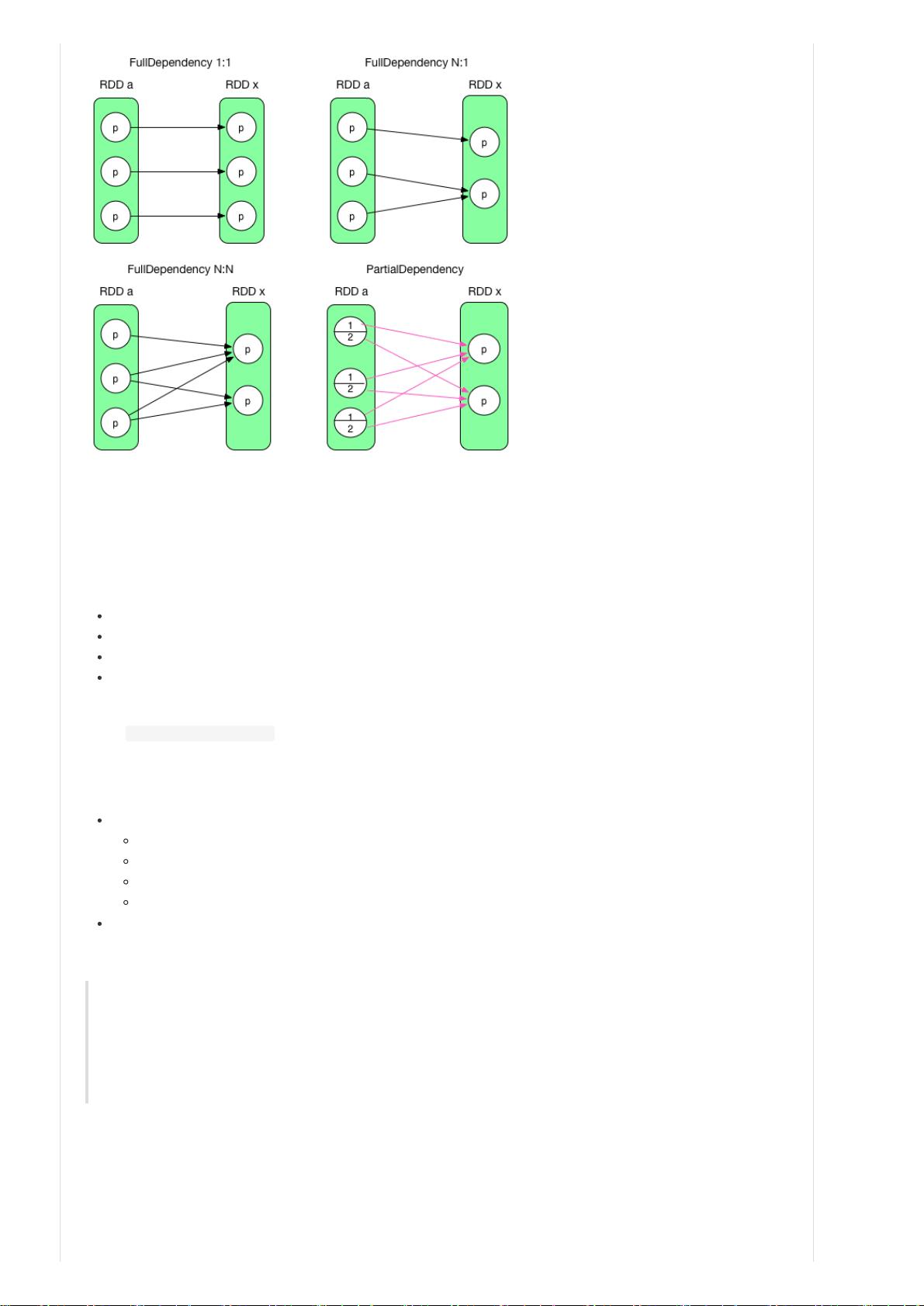
RDD 之间 partition 的依赖关系可以不是 1 对 1,如上图既有 1 对 1 关系,也有多对多的关系。
了解了 Job 的逻辑执行图后,写程序时候会在脑中形成类似上面的数据依赖图。然而,实际生成的 RDD 个数往往比我们
想想的个数多。
要解决逻辑执行图生成问题,实际需要解决:
如何产生 RDD,应该产生哪些 RDD?
如何建立 RDD 之间的依赖关系?
解决这个问题的初步想法是让每一个 transformation() 方法返回(new)一个 RDD。事实也基本如此,只是某些
transformation() 比较复杂,会包含多个子 transformation(),因而会生成多个 RDD。这就是
实际
RDD
个数比我们想象的多
一些
的原因。
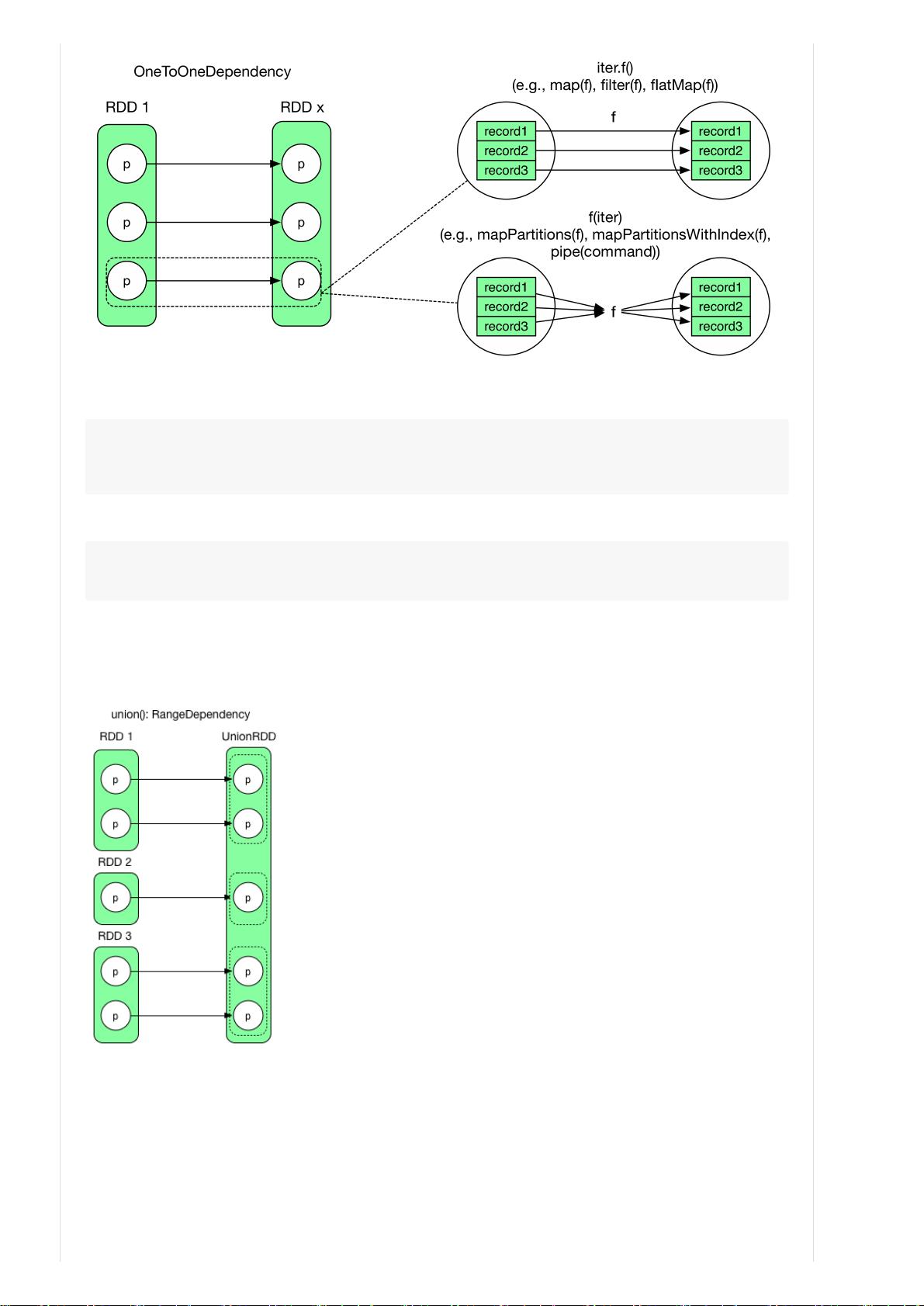
如何计算每个 RDD 中的数据?逻辑执行图实际上是 computing chain,那么 transformation() 的计算逻辑在哪里被
perform?每个 RDD 里有 compute() 方法,负责接收来自上一个 RDD 或者数据源的 input records,perfrom
transformation() 的计算逻辑,然后输出 records。
产生哪些 RDD 与 transformation() 的计算逻辑有关,下面讨论一些典型的 transformation() 及其创建的 RDD。官网上已经
解释了每个 transformation 的含义。iterator(split) 的意思是 foreach record in the partition。这里空了很多,是因为那些
transformation() 较为复杂,会产生多个 RDD,具体会在下一节图示出来。
Job 逻辑执行图
General logical plan
逻辑执行图的生成
1. 如何产生 RDD,应该产生哪些 RDD?