

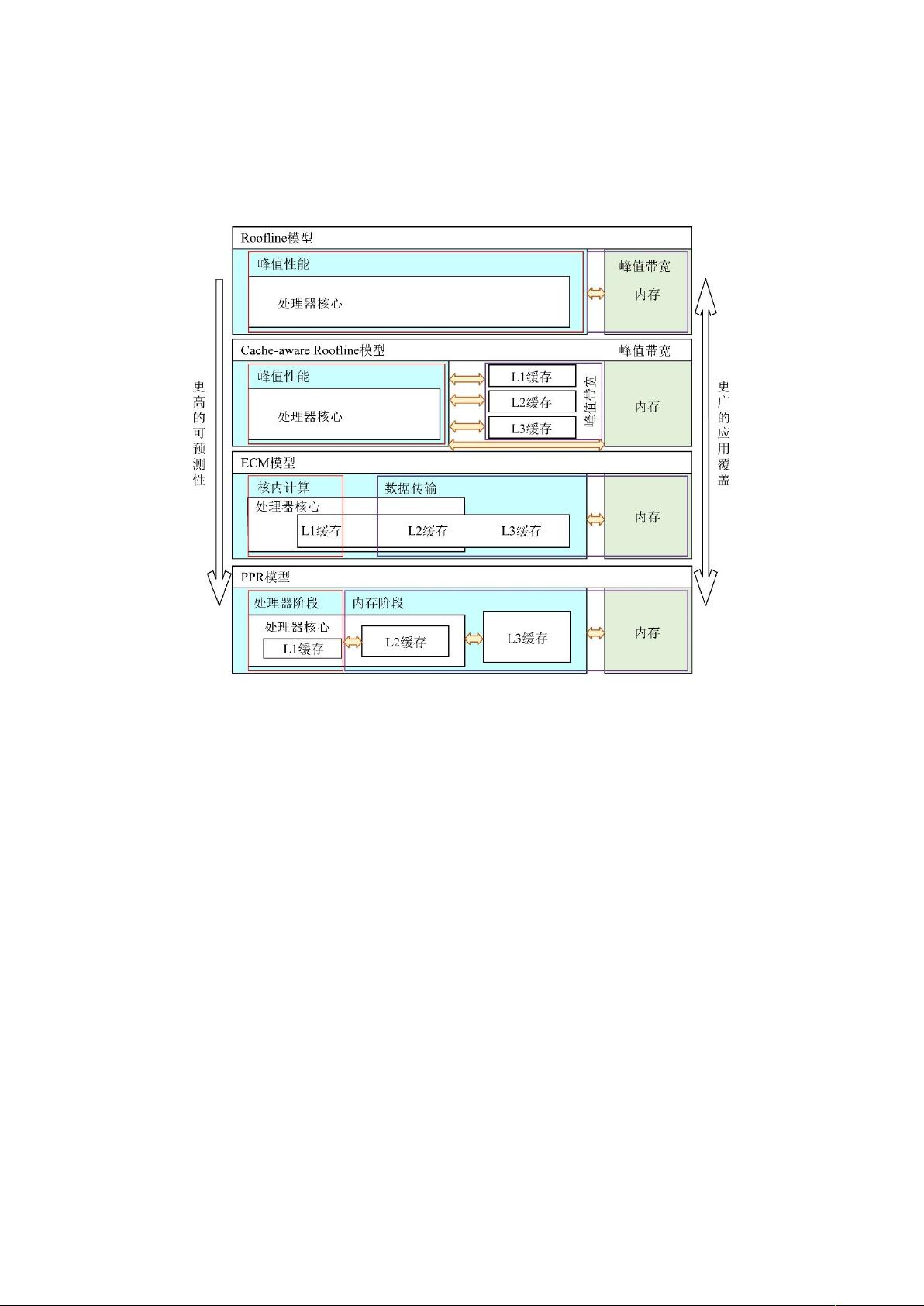
近些年来,使用性能模型的方法去分析和优化程序已经被广泛地
使用其中以稀疏矩阵向量乘
yAx 为例,作为典型的非规则访存的重要计算核心,该算法
被广泛应用在信号处理、图像处理和迭代求解器等科学计算和实际应
用中
但是在现有的多级存储器层次的体系结构上,稀疏矩阵向量乘
的效率一般很低,浮点效率往往低于硬件浮点峰值的 ,其主要原
因是复杂的存储器层次结构以及应用数据可重用性差的特征导致
命中率较低,从而凸显了各级存储器之间的访问延迟差异的瓶
颈为了解决这些问题,李肯立等人
在 !"# 上使用概率质量函数模型
去选择最佳的稀疏矩阵格式,从而构造不同的访存模式去优化数据重
用性问题; $ 等人
%
使用建模方法自动调优不同的向量寄存器从而优
化矩阵计算开销但是这些方法都属于粗粒度选择和评判优化方法的优
劣,不能细化 在特定平台上具体的执行行为因此如何建模
的计算过程以及随机的数据传输特性仍然是性能优化的主要挑
战此外,作为规则访存的典型代表,卷积计算在图像分类、目标检测 、
图像语义分割和神经网络等领域
&
取得了一系列突破性的研究成果,其
强大的特征学习与分类能力引起了广泛的关注之前的研究表明
'(
,卷
积操作在不同的数据规模和体系结构下最优的实现方法差异巨大,从
而也给性能模型优化提供了发挥的空间



剩余29页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 4459
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 精选微信小程序源码:仿美团外卖小程序(含源码+源码导入视频教程&文档教程,亲测可用)
- 离线安装包 Adobe Flash Player 32.0.0.156 for Linux 32-bit NPAPI
- java常见面试题包含答案
- 资源名称资源名称资源名称资源名称资源名称23
- HTML化妆品官方网站模板.zip
- 含电热联合系统的微电网运行优化
- 窗口函数和sql调优比较
- 精选微信小程序源码:仿饿了吗小程序(含源码+源码导入视频教程&文档教程,亲测可用)
- 精选微信小程序源码:仿KFC肯德基小程序(含源码+源码导入视频教程&文档教程,亲测可用)
- 离线安装包 Adobe Flash Player 32.0.0.156 for Linux 32-bit PPAPI
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


