# Boss直聘岗位数据分析
## 1. 项目背景
随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得很有必要。
本文基于这个问题,针对 boss 直聘网站,使用 Scrapy 框架爬取了全国热门城市大数据、数据分析、数据挖掘、机器学习、人工智能等相关岗位的招聘信息。分析比较了不同岗位的薪资、学历要求;分析比较了不同区域、行业对相关人才的需求情况;分析比较了不同岗位的知识、技能要求等。
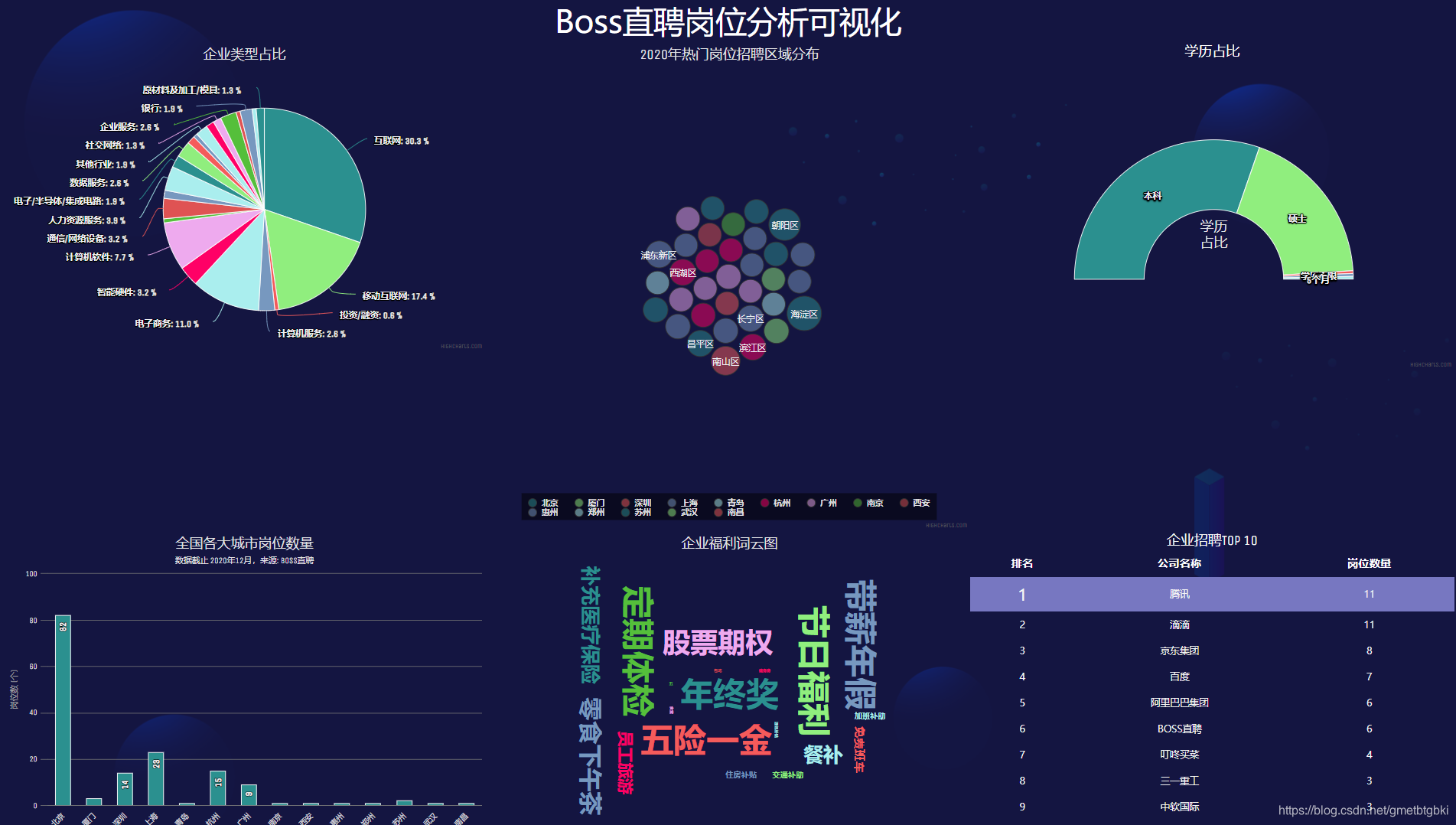
<center><b>图 1 岗位情况分析可视化</b></center>
## 2. 环境准备
<center><b>表 1-1 开发工具和环境</b></center>
| 开发工具/环境 | 版本 | 备注 |
| ------------- | :----------------------------------------------------------- | -------- |
| Windows | Windows10 | 系统 |
| PyCharm | Professional 2020.3 | 编写代码 |
| Anaconda3 | [Anaconda3-2019.03-Windows-x86_64.exe](https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2019.03-Windows-x86_64.exe) | 运行环境 |
<center><b>表 1-2 Python 第三方依赖库</b></center>
| 库名 | 版本 | 备注 |
| ---------- | ------ | ------------- |
| Scrapy | 2.4.1 | WEB爬虫框架 |
| SQLAlchemy | 1.3.5 | 数据库操作 |
| PyMySQL | 0.9.3 | 数据库操作 |
| pandas | 0.24.2 | 数据分析 |
| Flask | 1.1.1 | 轻量级web框架 |
## 3. 项目实现
该项目一共分为三个子任务完成,**数据采集—数据预处理—数据分析/可视化。**

<center><b>图 2 项目流程图</b></center>
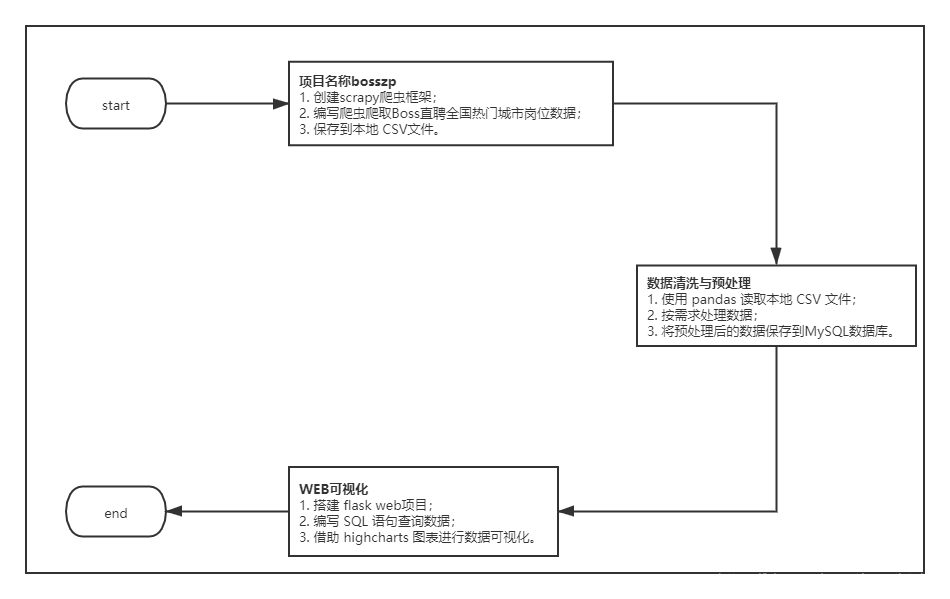
<center><b>图 3 项目架构图</b></center>
### 3.1 数据采集
爬取 Boss直聘热门城市岗位数据,并将数据以 CSV 文件格式进行保存。如下图所示:

<center><b>图 4 全国-Boss直聘热门城市岗位数据</b></center>
#### 3.1.1 创建 Scrapy 爬虫项目
① 环境安装:
```cmd
$ pip install scrapy
```
② 项目创建:
```cmd
$ scrapy startproject bosszp
$ cd bosszp
$ scrapy genspider boss zhipin.com
```
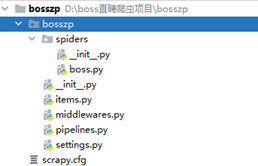
<center><b>图 5 Scrapy 项目结构</b></center>
#### 3.1.2 配置 Scrapy 项目
爬取 Boss 直聘网站数据,通过检测 Boss 直聘网站,发现有 `Cookie`,`User-Agent`,`Referer`,`Robots协议`等常见反爬策略。根据这些策略我们需要在`settings.py` 文件中做对应的一些配置和修改。具体配置如下:
① 关闭 Robots 协议
```python
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
```
② 修改下载延迟为 60 s
```python
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 60
```
③ 禁用系统 cookie
```python
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
```
④ 开启 item-pipelines
```python
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'bosszhipin.pipelines.BosszhipinPipeline': 300,
}
```
#### 3.1.3 编写爬虫程序
创建和配置好 `Scrapy` 项目以后,我们就可以编写 `Scrapy` 爬虫程序了。
① 确定目标(编辑 `items.py`)
```python
import scrapy
class BosszpItem(scrapy.Item):
job_name = scrapy.Field() # 岗位名
job_area = scrapy.Field() # 工作地址
job_salary = scrapy.Field() # 薪资
com_name = scrapy.Field() # 企业名称
com_type = scrapy.Field() # 企业类型
com_size = scrapy.Field() # 企业规模
finance_stage = scrapy.Field() # 融资情况
work_year = scrapy.Field() # 工作年限
education = scrapy.Field() # 学历要求
job_benefits = scrapy.Field() # 岗位福利
```
② 编写爬虫(编辑 `spiders/boss.py`),需要替换成最新的 `cookie`
```python
import scrapy
import json
import logging
import random
from bosszp.items import BosszpItem
class BossSpider(scrapy.Spider):
name = 'boss'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/wapi/zpCommon/data/cityGroup.json'] # 热门城市列表url
# 设置多个 cookie,建议数量为 页数/2 + 1 个cookie.至少 设置 4 个
# 只需复制 __zp_stoken__ 部分即可
cookies = [ '__zp_stoken__=f330bOEgsRnsAIS5Bb2FXe250elQKNzAgMBcQZ1hvWyBjUFE1DCpKLWBtBn99Nwd%2BPHtlVRgdOi1vDEAkOz9sag50aRNRfhs6TQ9kWmNYc0cFI3kYKg5fAGVPPX0WO2JCOipvRlwbP1YFBQlHOQ%3D%3D', '__zp_stoken__=f330bOEgsRnsAIUsENEIbe250elRsb2U4Bg0QZ1hvW19mPEdeeSpKLWBtN3Y9QCN%2BPHtlVRgdOilvfTYkSTMiaFN0X3NRAGMjOgENX2krc0cFI3kYKiooQGx%2BPX0WO2I3OipvRlwbP1YFBQlHOQ%3D%3D', '__zp_stoken__=f330bOEgsRnsAITsLNnJIe250elRJMH95DBAQZ1hvW1J1ewdmDCpKLWBtBHZtagV%2BPHtlVRgdOil1LjkkR1MeRAgdY3tXbxVORWVuTxQlc0cFI3kYKgwCEGxNPX0WO2JCOipvRlwbP1YFBQlHOQ%3D%3D'
]
# 设置多个请求头
user_agents = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
]
page_no = 1 # 初始化分页
def random_header(self):
"""
随机生成请求头
:return: headers
"""
headers = {'Referer': 'https://www.zhipin.com/c101020100/?ka=sel-city-101020100'}
headers['cookie'] = random.choice(self.cookies)
headers['user-agent'] = random.choice(self.user_agents)
return headers
def parse(self, response):
"""
解析首页热门城市列表,选择热门城市进行爬取
:param response: 热门城市字典数据
:return:
"""
# 获取服务器返回的内容
city_group = json.loads(response.body.decode())
# 获取热门城市列表
hot_city_list = city_group['zpData']['hotCityList']
# 初始化空列表,存储打印信息
# city_lst = []
# for index,item in enumerate(hot_city_list):
# city_lst.apend({index+1: item['name']})
# 列表推导式:
hot_city_names = [{index + 1: item['name']} for index, item in enumerate(hot_city_list)]
print("--->", hot_city_names)
毕业设计(Boss直聘岗位数据分析)

版权申诉
 bosszp-master.zip (38个子文件)
bosszp-master.zip (38个子文件)  bosszp-master
bosszp-master  全国-热门城市岗位数据.csv 38KB runspider.py 149B scrapy.cfg 255B .idea misc.xml 185B bosszp.iml 317B inspectionProfiles Project_Default.xml 478B profiles_settings.xml 174B modules.xml 264B .gitignore 270B README.md 31KB bosszp settings.py 3KB clean dataclean.py 4KB __init__.py 52B pipelines.py 812B middlewares.py 4KB __init__.py 0B web run.py 4KB __init__.py 52B dbutils.py 3KB templates
全国-热门城市岗位数据.csv 38KB runspider.py 149B scrapy.cfg 255B .idea misc.xml 185B bosszp.iml 317B inspectionProfiles Project_Default.xml 478B profiles_settings.xml 174B modules.xml 264B .gitignore 270B README.md 31KB bosszp settings.py 3KB clean dataclean.py 4KB __init__.py 52B pipelines.py 812B middlewares.py 4KB __init__.py 0B web run.py 4KB __init__.py 52B dbutils.py 3KB templates  index.html 3KB static highcharts highcharts-more.js 82KB wordcloud.js 9KB oldie.js 26KB dark-unica.js 3KB highcharts.js 268KB img
index.html 3KB static highcharts highcharts-more.js 82KB wordcloud.js 9KB oldie.js 26KB dark-unica.js 3KB highcharts.js 268KB img  favicon.png 2KB bg.png 39KB js fan.js 2KB order.js 1KB packgebubble.js 2KB jquery-1.8.3.min.js 91KB cylindrical.js 2KB word.js 1KB pie.js 2KB css mystyle.css 2KB items.py 640B spiders __init__.py 161B boss.py 6KB
favicon.png 2KB bg.png 39KB js fan.js 2KB order.js 1KB packgebubble.js 2KB jquery-1.8.3.min.js 91KB cylindrical.js 2KB word.js 1KB pie.js 2KB css mystyle.css 2KB items.py 640B spiders __init__.py 161B boss.py 6KB












- 1
- 2
- 3
- 4
- 5
- 6
前往页