



Finding The Shortest Path,
With A Little Help From
Dijkstra
Finding the shortest path, with a little help from Dijkstra!
If you spend enough time reading about programming
or computer science, there’s a good chance that you’ll
encounter the same ideas, terms, concepts, and names, time
and again. Some of them start to become more familiar
with time. Naturally, organically, and sometimes without
too much effort on your part, you start to learn what all of
these things mean. This happens because either you’ve

slowly begun to grasp the concept, or you’ve read about a
phrase enough times that you start to truly understand its
meaning.
However, there are some ideas and definitions that are
much harder to understand. These are the ones that you feel
like you’re supposed to know, but you haven’t run across it
enough to really comprehend it.
Topics that we feel like we’re meant to know — but never
quite got around to learning — are the most intimidating
ones of all. The barrier to entry is so high, and it can feel
impossibly hard to understand something that you have
little to no context for. For me, that intimidating topic is
Dijkstra’s algorithm. I had always heard it mentioned in
passing, but never came across it, so I never had the
context or the tools to try to understand it.
Thankfully, in the course of writing this series, that has all
changed. After years of fear and anxiety about Dijkstra’s
algorithm, I’ve finally come to understand it. And
hopefully, by the end of this post, you will too!
Graphs that weigh heavy on your
mind

Before we can really get into Dijkstra’s super-famous
algorithm, we need to pick up a few seeds of important
information that we’ll need along the way, first.
Throughout this series, we’ve slowly built upon our
knowledge base of different data structures. Not only have
we learned about various graph traversal algorithms, but
we’ve also taught ourselves the fundamentals of graph
theory, as well as the practical aspects of representing
graphs in our code. We already know that graphs can be
directed, or undirected, and may even contain cycles.
We’ve also learned how we can use breadth-first search and
depth-first search to traverse through them, using two very
different strategies.
In our journey to understand graphs and the different types
of graph structures that exist, there is one type of graph that
we’ve managed to skip over — until now, that is. It’s time
for us to finally come face-to-face with the weighted graph!
Weighted graph: a definition
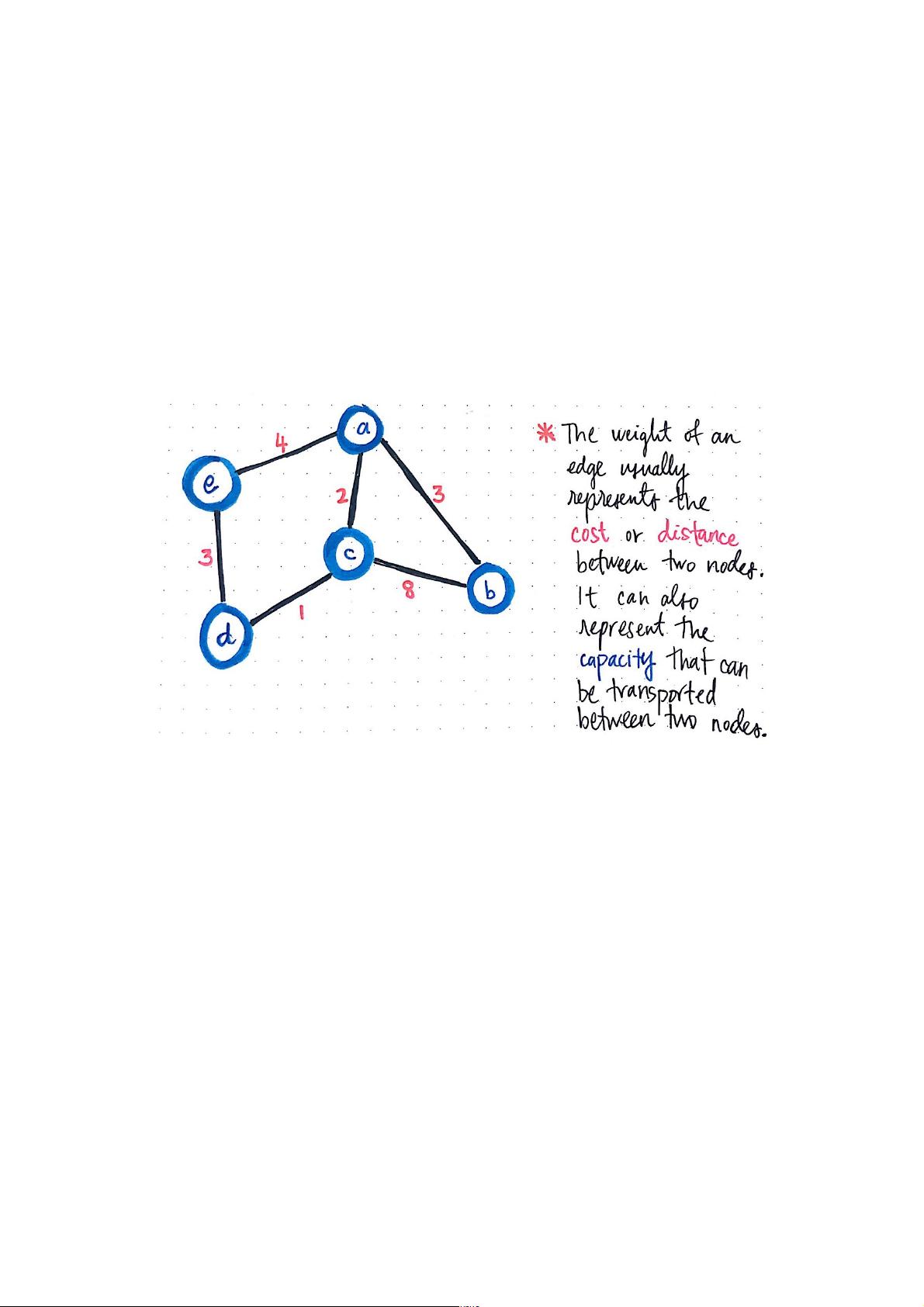
A weighted graph is interesting because it has little to do
with whether the graph is directed, undirected, or contains
cycles. At its core, a weighted graph is a graph whose
edges have some sort of value that is associated with them.
The value that is attached to an edge is what gives the edge
its “weight”.
The weight of an edge represents the cost or distance between two
nodes.
A common way to refer to the “weight” of a single edge is
by thinking of it as the cost or distance between two nodes.
In other words, to go from node a to node b has some sort
of cost to it.
Or, if we think of the nodes like locations on a map, then
the weight could instead be the distance between nodes a
and b. Continuing with the map metaphor, the “weight” of

an edge can also represent the capacity of what can be
transported, or what can be moved between two nodes, a
and b.
For example, in the example above, we could ascertain that
the cost, distance, or capacity between the nodes c and b is
weighted at 8.
We can represent weighted graphs using an adjacency list.
The weighted-ness of the edges is the only thing that sets
weighted graphs apart from the unweighted graphs that
we’ve worked with so far in this series.
In fact, we probably already can imagine how we’d













评论0