





实验五 KNN 算法
一. 实验目的
1. 加强对 k-最近邻算法的理解。
2. 锻炼分析问题、解决问题并动手实践的能力。
二. 实验原理
KNN(k Nearest Neighbors)算法又叫 k 最临近方法,K-最临近分类方法存放所有的训练样
本,在接受待分类的新样本之前不需构造模型,并且直到新的(未标记的)样本需要分类时
才建立分类。K-最临近分类基于类比学习,其训练样本由 N 维数值属性描述,每个样本代表
N 维空间的一个点。这样,所有训练样本都存放在 N 维模式空间中。给定一个未知样本,k-
最临近分类法搜索模式空间,找出最接近未知样本的 K 个训练样本。这 K 个训练样本是未知
样本的 K 个“近邻”。“临近性”又称为相异度(Dissimilarity),由欧几里德距离定义,其中
两个点 X(x1,x2,„,xn)和 Y(y1,y2,„,yn)的欧几里德距离是:
D
(
X,Y
)
=
(𝑥1
―
𝑦1)
2
+
(𝑥2
―
𝑦2)
2
+
…
+
(𝑥𝑛
―
𝑦𝑛)
2
�������
未知样本被分配到 K 个最临近者中最公共的类。在最简单的情况下,也就是当 K=1 时,未
知样本被指定到模式空间中与之最临近的训练样本的类。
三. 实验内容
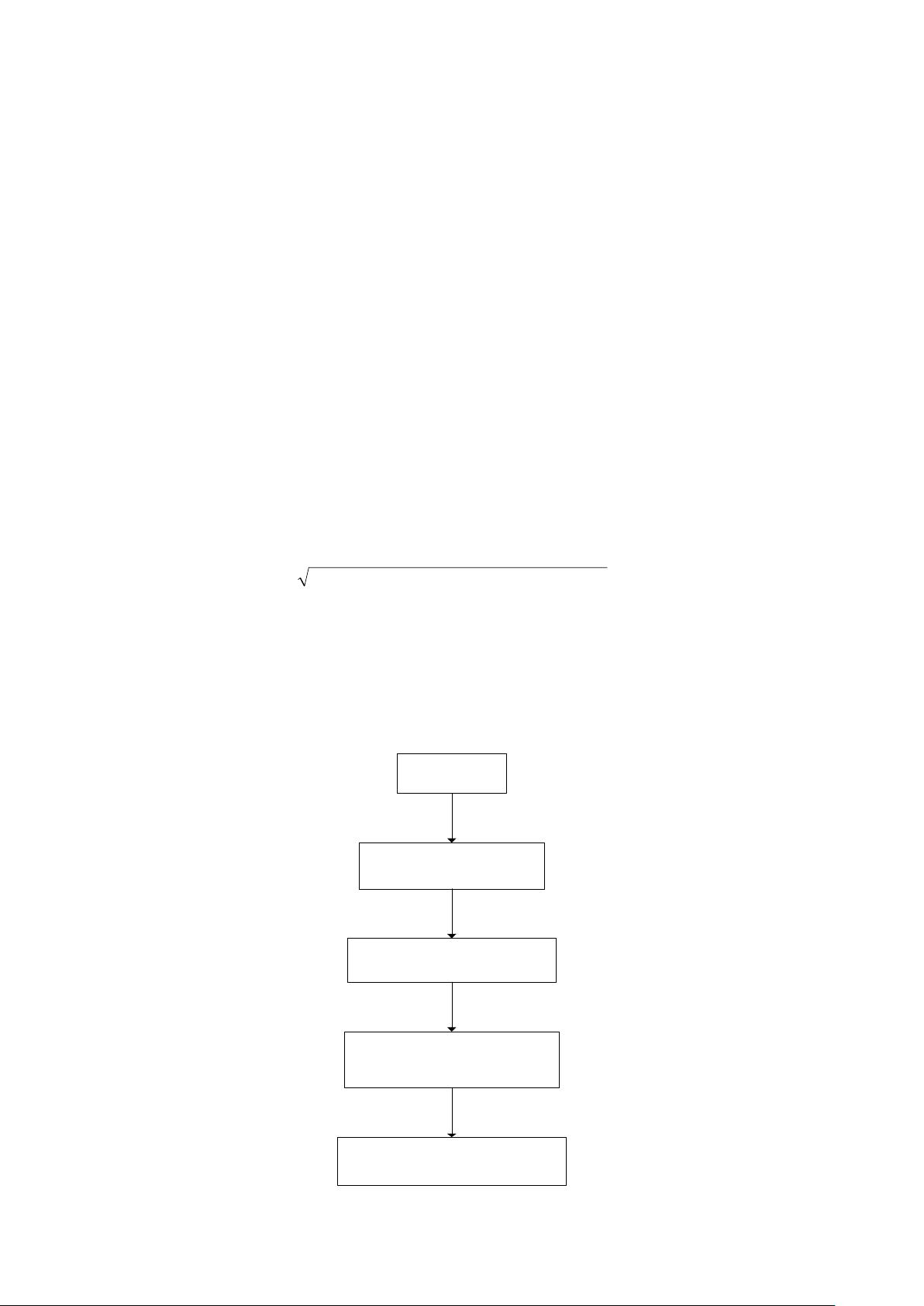
1. 算法流程图:
设定参数K
计算出样本数据和待
分类数据的距离
为待分类数据选择K个与
其距离最小的样本
统计出K个样本中大多数
样本所属的分类
待分类数据就属于这个大多
数样本所属类













评论0