一文搞懂全链路监控:方案概述与比较
75 浏览量
2021-01-27
11:29:24
上传
评论
收藏 663KB PDF 举报

一文搞懂全链路监控:方案概述与比较一文搞懂全链路监控:方案概述与比较
0 问题背景
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模
块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多
个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定
位和解决问题。
全链路监控组件就在这样的问题背景下产生了。最出名的是谷歌公开的论文提到的 Google Dapper。想要在这个上下文中理
解分布式系统的行为,就需要监控那些横跨了不同的应用、不同的服务器之间的关联动作。
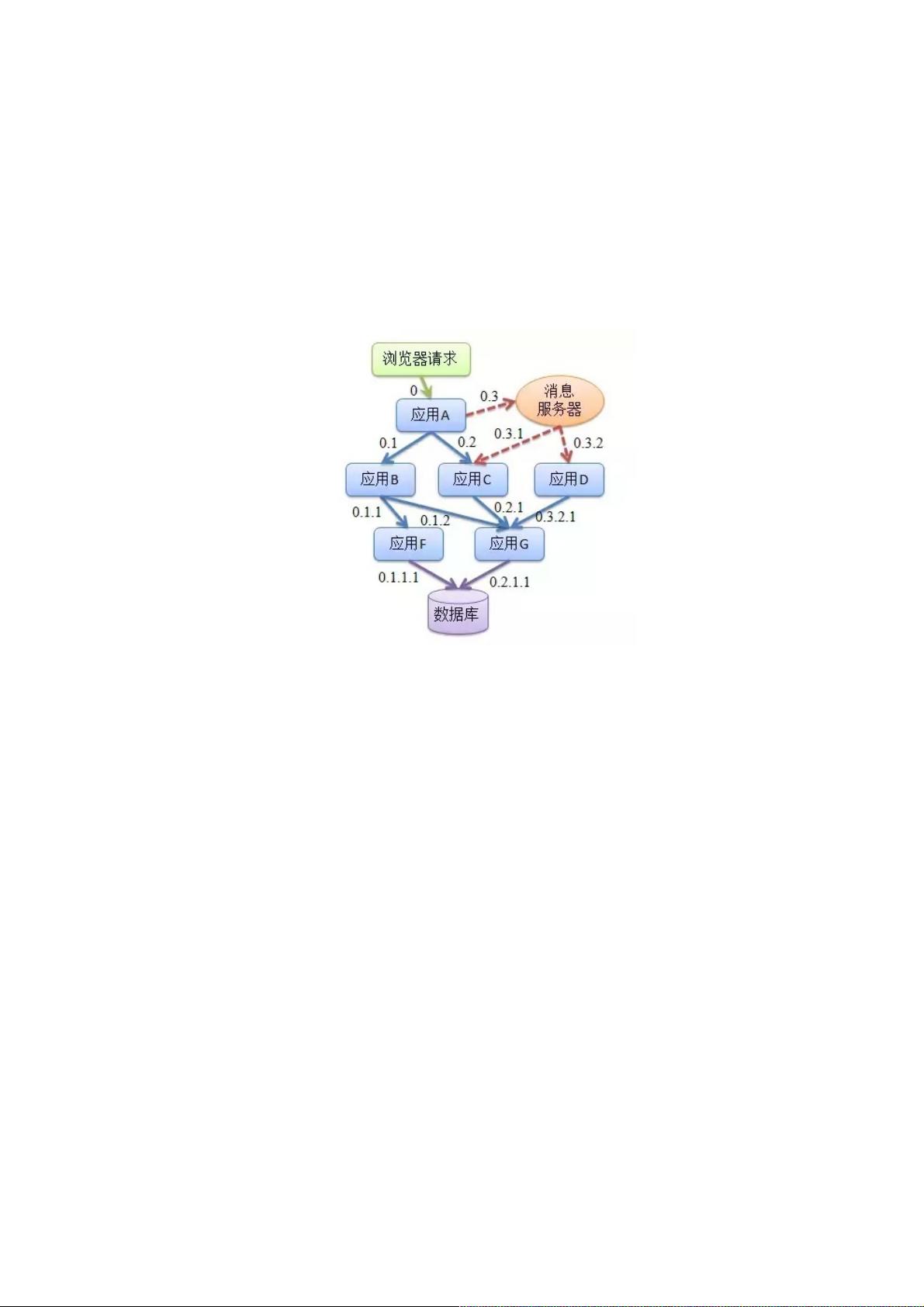
所以,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路。一个请求完整调用链可能
如下图所示:
那么在业务规模不断增大、服务不断增多以及频繁变更的情况下,面对复杂的调用链路就带来一系列问题:
1.如何快速发现问题?
2.如何判断故障影响范围?
3.如何梳理服务依赖以及依赖的合理性?
4.如何分析链路性能问题以及实时容量规划?
同时我们会关注在请求处理期间各个调用的各项性能指标,比如:吞吐量(TPS)、响应时间及错误记录等。
1.吞吐量,根据拓扑可计算相应组件、平台、物理设备的实时吞吐量。
2.响应时间,包括整体调用的响应时间和各个服务的响应时间等。
3.错误记录,根据服务返回统计单位时间异常次数。
全链路性能监控 从整体维度到局部维度展示各项指标,将跨应用的所有调用链性能信息集中展现,可方便度量整体和局部性
能,并且方便找到故障产生的源头,生产上可极大缩短故障排除时间。
有了全链路监控工具,我们能够达到:
1.请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
2.可视化: 各个阶段耗时,进行性能分析。
3.依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化。
4.数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。
1 目标要求
如上所述,那么我们选择全链路监控组件有哪些目标要求呢?Google Dapper中也提到了,总结如下:
1. 探针的性能消耗


剩余10页未读,继续阅读






评论0
最新资源