基于Seq2Seq与Bi-LSTM的中文文本自动校对模型
183 浏览量
2020-10-15
19:30:11
上传
评论 1
收藏 542KB PDF 举报

基于基于Seq2Seq与与Bi-LSTM的中文文本自动校对模型的中文文本自动校对模型
针对中文文本自动校对提出了一种新的基于Seq2Seq和Bi-LSTM结合的深度学习模型。与传统的基于规则和概
率统计的方法不同,基于Seq2Seq基础结构改进,加入了Bi-LSTM单元和注意力机制,实现了一个中文文本自
动校对模型。采用F0.5与GLEU指标评价,通过公开的数据集进行不同模型的对比实验。实验结果表明,新模型
能有效地处理长距离的文本错误以及语义错误,Bi-RNN以及注意力机制的加入对中文文本校对模型的性能有显
著提升。
0 引言引言
随着出版行业电子化的不断发展,其中中文文本校对环节的任务越来越重,使用传统的人工校对显然无法满足需求。因
此,中文文本自动校对技术的发展就显得尤其重要。
本文采用深度学习中的循环神经网络(Recurrent Neural Networks)进行文本自动校对。其特点是能处理任意长度的输入和输
出序列,因此被广泛应用在自然语言处理(Natural Language Processing)任务中。在机器翻译任务上,CHO K等在2014年发
表的论文
[1]
中首次提出基于循环神经网络设计的Seq2Seq模型,并且在多个自然语言处理问题上取得突破。因此,Seq2Seq
模型的提出为文本校对领域的研究提供了一种新的思路与方法。
目前,基于深度学习的中文文本自动校对技术的研究仍处于起步阶段,本文着重研究了基于Seq2Seq模型与BiRNN网络结
构改进的网络模型,使其适用于中文文本校对问题,为中文文本校对领域提供了一种新的方法。
1 背景背景
1.1 中文文本校对的研究现状中文文本校对的研究现状
目前,国内在中文文本校对方面的研究主要采用以下3种方法:(1)基于拼音的中文文本校对
[2]
;(2)基于字的中文文本校
对
[3]
;(3)基于上下文的中文文本校对
[4]
。这三种方法采用的校对规则又分为3类:(1)利用文本的特征,如字形特征、词性特征
或上下文特征;(2)利用概率统计特性进行上下文接续关系的分析
[5]
;(3)利用语言学知识,如语法规则、词搭配规则等
[6]
。
1.2 Seq2Seq模型模型
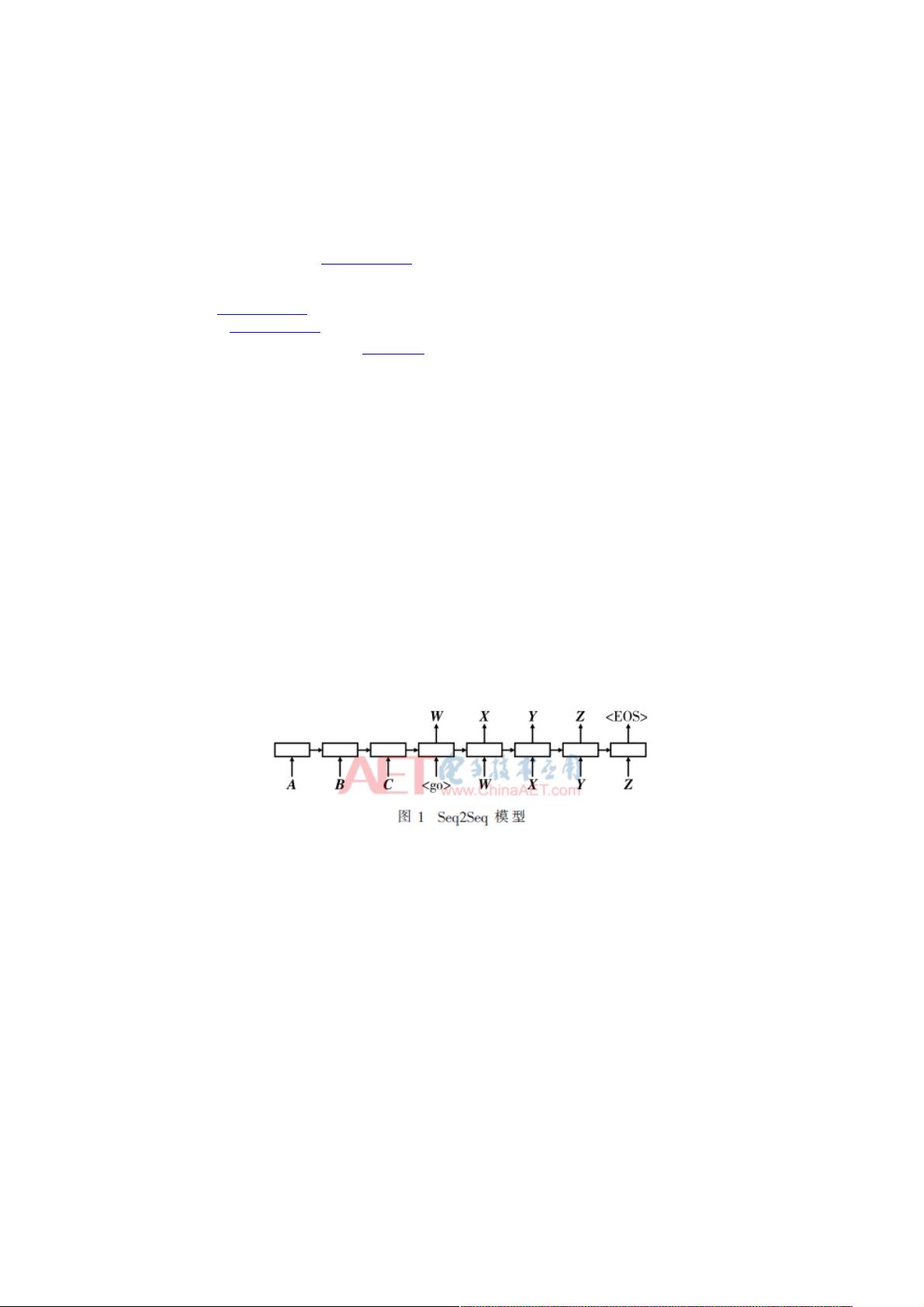
基础的Seq2Seq模型包含三部分,即Encoder端、Decoder端以及连接两者的中间状态向量
[7]
。Encoder编码器将输入序列
X=(x
1
,…,x
T
)编码成一个固定大小的状态向量S传给Decoder解码器,解码器通过对S的学习生成输出序列Y=(y
1
,
…,y
K
)
[8]
。解码器主要基于中间状态向量S以及前一时刻的输出y(t-1)解码得到该时刻t的输出y(t)
[9]
。其结构如图1所示。
1.3 Bidirectional-LSTM
LSTM(Long Short-Term Memory)是门控制循环神经网络的一种。标准的RNN网络能够存储的信息很有限,并且输入对于输
出的影响随着网络环路的不断递增而衰退
[10]
;而LSTM在面对较长的序列时,依然能够记住序列的全部信息。LSTM是一种拥
有输入门、遗忘门、输出门3个门结构的特殊网络结构
[11]
。LSTM通过这些门的结构让信息有选择性地影响网络中每个时刻的
状态
[12]
。LSTM的结构如图2所示。
资源评论













