Spark计算引擎之SparkSQL详解
58 浏览量
2021-01-27
12:13:22
上传
评论
收藏 724KB PDF 举报

Spark计算引擎之计算引擎之SparkSQL详解详解
一、Spark SQL
1.Spark SQL概述
1.1.Spark SQL的前世今生
Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理
执行计划交换出来。这个方法使得Shark的用户可以加速Hive的查询,但是Shark继承了Hive的大且复杂的代码使得Shark很难
优化和维护,同时Shark依赖于Spark的版本。随着我们遇到了性能优化的上限,以及集成SQL的一些复杂的分析功能,我们
发现Hive的MapReduce设计的框架限制了Shark的发展。在2014年7月1日的SparkSummit上,Databricks宣布终止对Shark的
开发,将重点放到SparkSQL上。
1.2.什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的
作用。
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上运算的更多信息,Spark SQL使用这些信息进行了额外的优
化,使对结构化数据的操作更加高效和方便。
有多种方式去使用Spark SQL,包括SQL、DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基
于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点,看你喜欢那种风格。
1.3.为什么要学习Spark SQL
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群中去执行,大大简化了编写MapReduce程序的复杂
性,由于MapReduce这种计算模型执行效率比较慢,所以Spark SQL应运而生,它是将Spark SQL转换成RDD,然后提交到
集群中去运行,执行效率非常快!
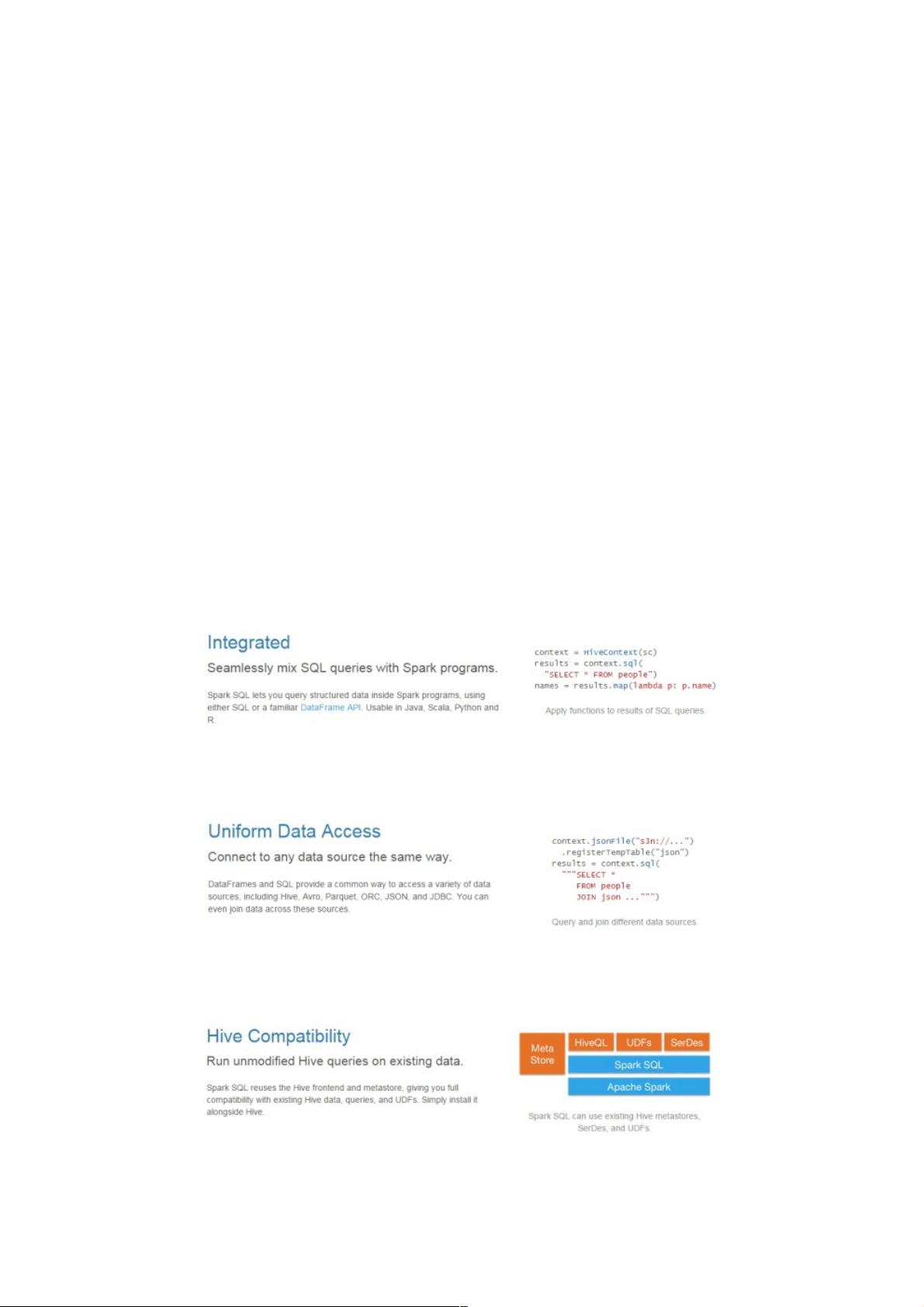
1.易整合
将sql查询与spark程序无缝混合,可以使用java、scala、python、R等语言的API操作。
2.统一的数据访问
以相同的方式连接到任何数据源。
3.兼容Hive
支持hiveSQL的语法。
4.标准的数据连接






评论0
最新资源