使用python的scrapy模块爬取文本保存到txt文件
111 浏览量
2020-12-23
01:22:25
上传
评论
收藏 310KB PDF 举报

使用使用python的的scrapy模块爬取文本保存到模块爬取文本保存到txt文件文件
使用使用python的的scrapy爬取文本保存为爬取文本保存为txt文件文件
编码工具编码工具
Visual Studio Code
实现步骤实现步骤
1.创建创建scrapyTest项目项目
在vscode中新建终端并依次输入下列代码:
scrapy startproject scrapyTest
cd scrapyTest
code
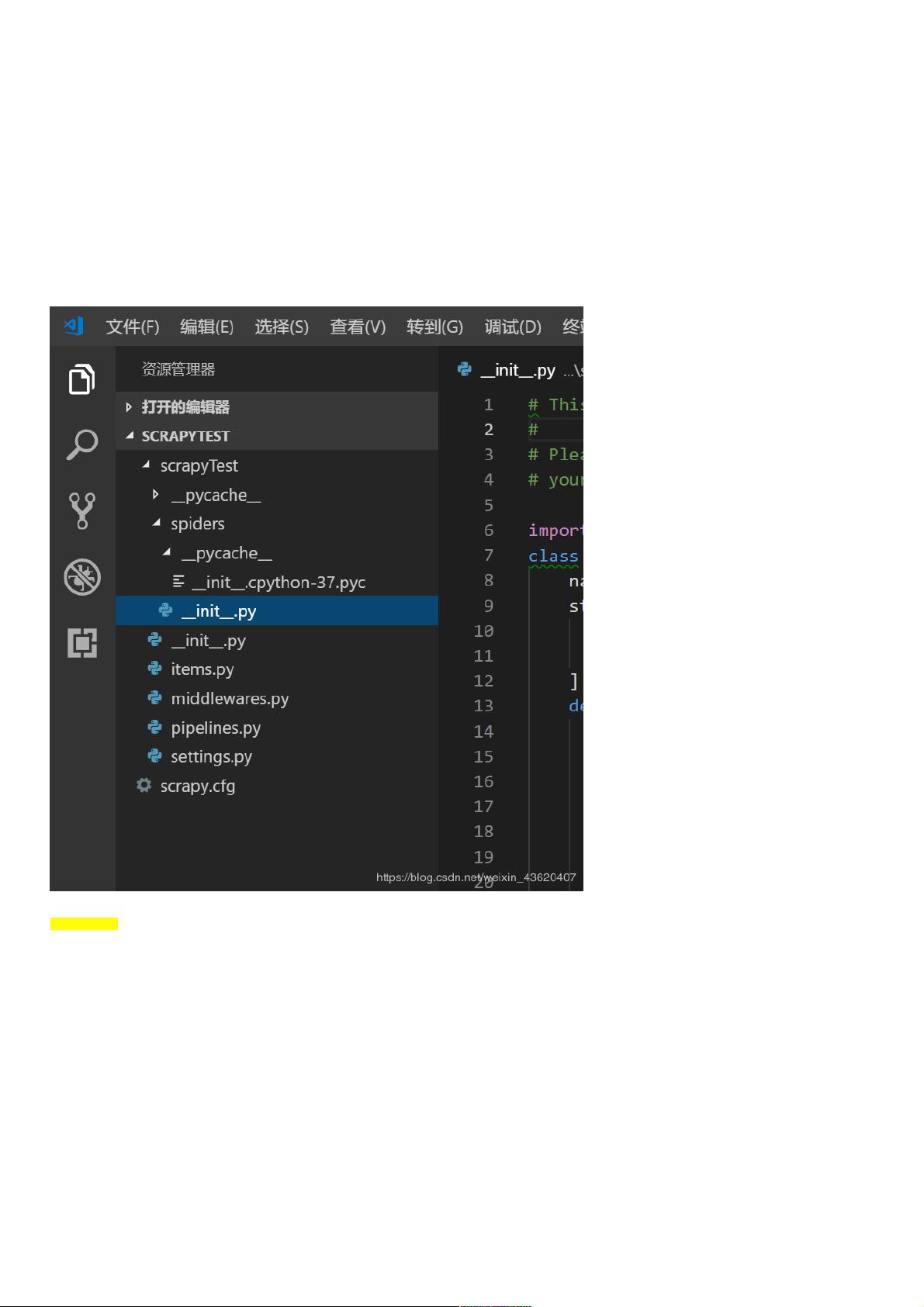
打开项目scrapyTest(vscode自动生成下列文件)
2.源代码源代码
pipelines.py
class ScrapytestPipeline(object):
def open_spider(self,spider):
#创建my.txt文件,并将字符集设为utf-8
self.file = open('my.txt', 'w', encoding='utf-8')
def close_spider(self,spider):
self.file.close()
def process_item(self, item, spider):
#将爬取到的文本保存到my.txt中;当向txt中写入字典,list集合时,使用str()
self.file.write(str(item)+'')
settings.py
BOT_NAME = 'scrapyTest'
SPIDER_MODULES = ['scrapyTest.spiders'] NEWSPIDER_MODULE = 'scrapyTest.spiders'
ROBOTSTXT_OBEY = False
# 关键代码,没有这段无法实现保存
ITEM_PIPELINES = {
'scrapyTest.pipelines.ScrapytestPipeline': 300,
资源评论













