python3对拉勾数据进行可视化分析的方法详解
189 浏览量
2020-12-31
17:12:32
上传
评论
收藏 305KB PDF 举报

python3对拉勾数据进行可视化分析的方法详解对拉勾数据进行可视化分析的方法详解
前言前言
上回说到我们如何把拉勾的数据抓取下来的,既然获取了数据,就别放着不动,把它拿出来分析一下,看看这些数据里面都包
含了什么信息。
(本次博客源码地址:https://github.com/MaxLyu/Lagou_Analyze (本地下载))
下面话不多说了,来一起看看详细的介绍吧
一、前期准备一、前期准备
由于上次抓的数据里面包含有 ID 这样的信息,我们需要将它去掉,并且查看描述性统计,确认是否存在异常值或者确实值。
read_file = "analyst.csv"
# 读取文件获得数据
data = pd.read_csv(read_file, encoding="gbk")
# 去除数据中无关的列
data = data[:].drop(['ID'], axis=1)
# 描述性统计
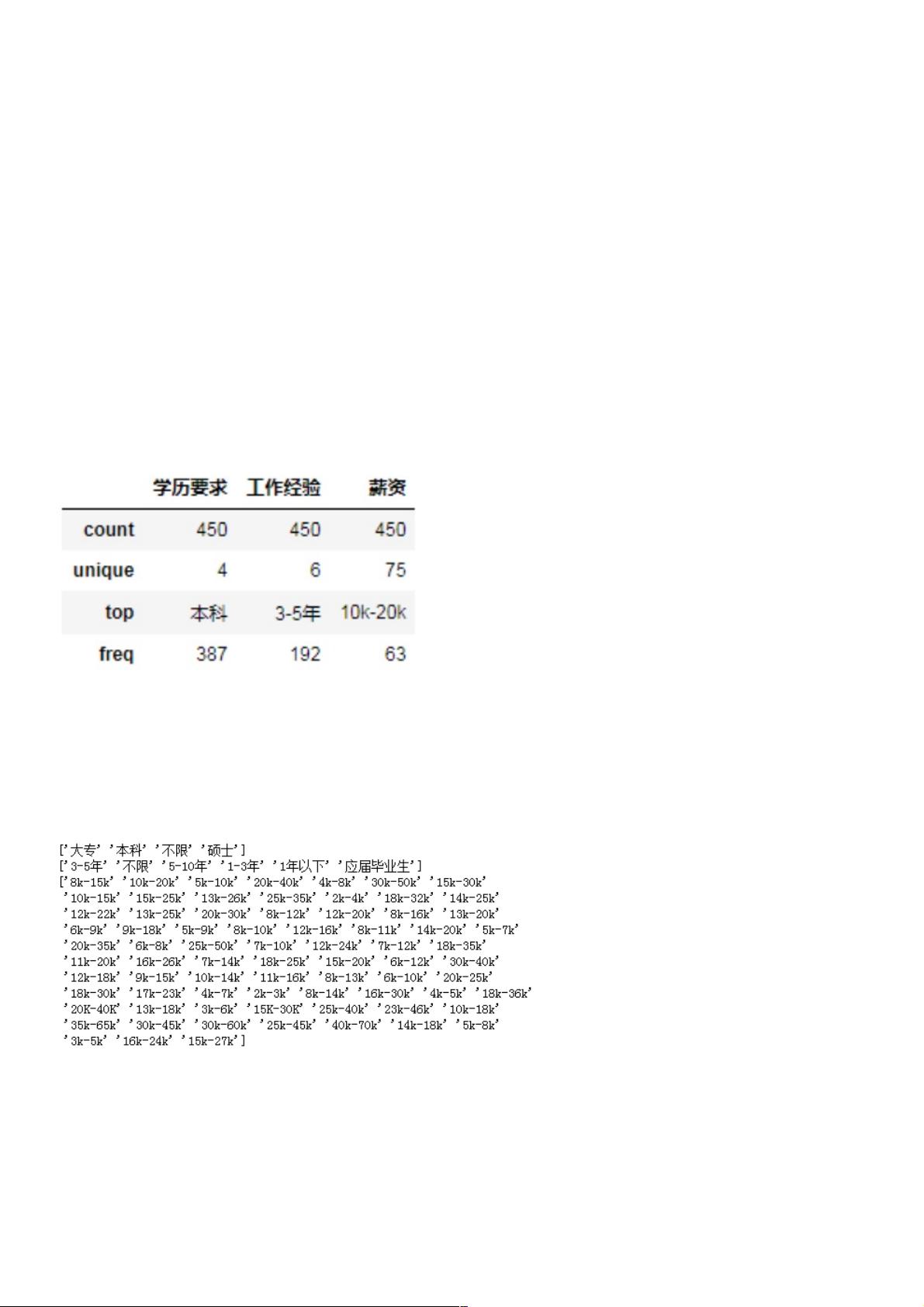
data.describe()
结果中的 unique 表示的是在该属性列下面存在的不同值个数,以学历要求为例子,它包含【本科、大专、硕士、不限】这4
个不同的值,top 则表示数量最多的值为【本科】,freq 表示出现的频率为 387。由于薪资的 unique 比较多,我们查看一下
存在什么值。
print(data['学历要求'].unique())
print(data['工作经验'].unique())
print(data['薪资'].unique())
二、预处理二、预处理
从上述两张图可以看到,学历要求和工作经验的值比较少且没有缺失值与异常值,可以直接进行分析;但薪资的分布比较多,
总计有75种,为了更好地进行分析,我们要对薪资做一个预处理。根据其分布情况,可以将它分成【5k 以下、5k-10k、10k-
20k、20k-30k、30k-40k、40k 以上】,为了更加方便我们分析,取每个薪资范围的中位数,并划分到我们指定的范围内。
# 对薪资进行预处理
def pre_salary(data):
salarys = data['薪资'].values
salary_dic = {}
for salary in salarys:
资源评论













