详解python爬虫系列之初识爬虫
189 浏览量
2020-09-19
12:02:32
上传
评论
收藏 398KB PDF 举报

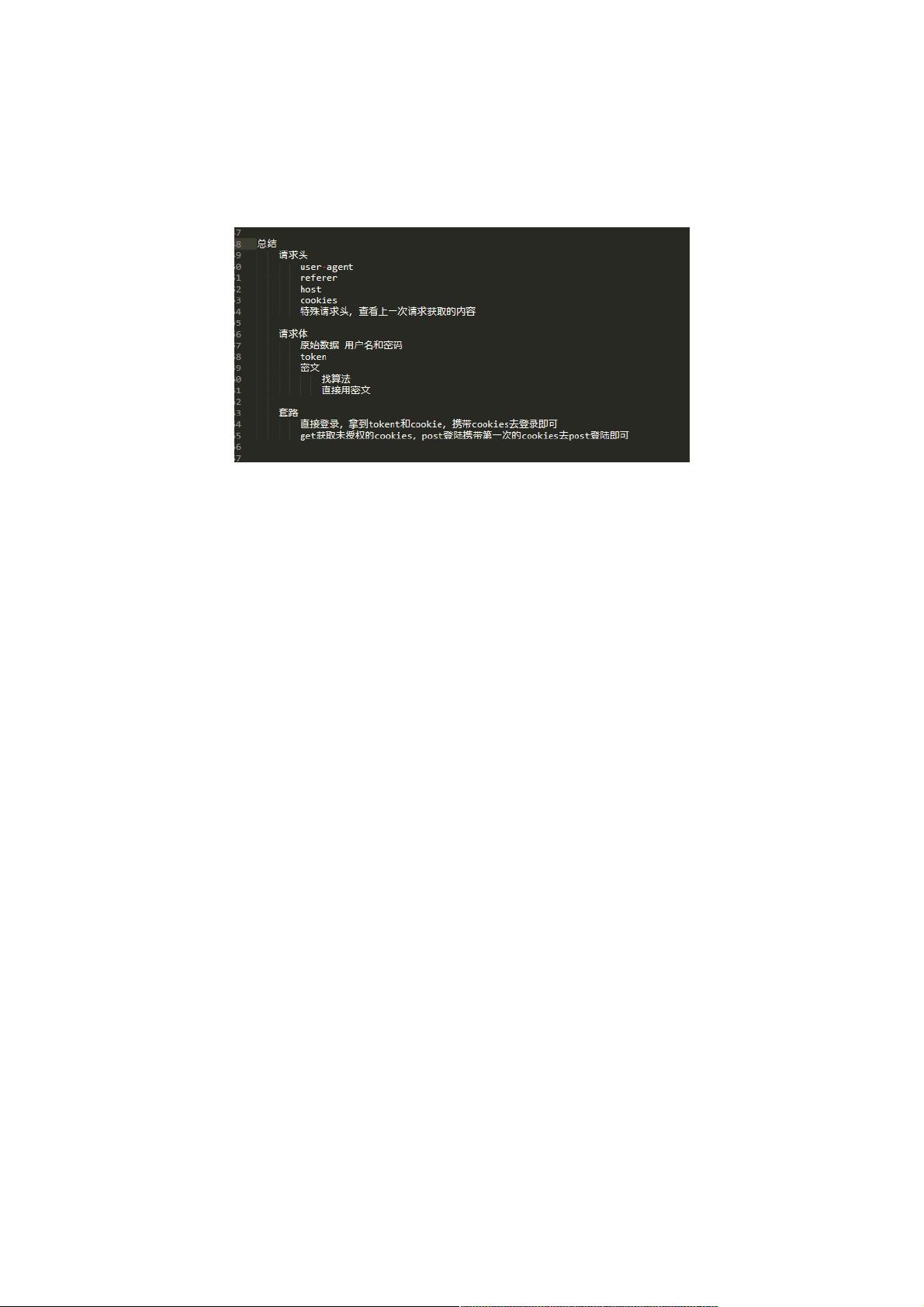
详解详解python爬虫系列之初识爬虫爬虫系列之初识爬虫
主要介绍了python爬虫系列之初识爬虫,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友
们下面随着小编来一起学习学习吧
前言
我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握
爬虫的基础知识,做网络爬虫还是需要基本的前端的知识的,下面我们进行我们的爬虫讲解
在进行实战之前,我们先给大家看下爬虫的一般讨论,方便大家看懂下面的实例
一、爬汽车之家一、爬汽车之家
汽车之家这个网站没有做任何的防爬虫的限制,所以最适合我们来练手
1、导入我们要用到的模块
import requests
from bs4 import BeautifulSoup
2、利用requests模块伪造浏览器请求
# 通过代码伪造浏览器请求
res = requests.get(https://www.autohome.com.cn/news/)
3、设置解码的方式,python是utf-8,但是汽车之家是用gbk编码的,所以这里要设置一下解码的方式
# 设置解码的方式
res.encoding = "gbk"
4、把请求返回的对象,传递一个bs4模块,生成一个BeautifulSoup对象
soup = BeautifulSoup(res.text,"html.parser")
5、这样,我们就可以使用BeautifulSoup给我们提供的方法,如下是查找一个div标签,且这个div标签的id属性为auto-channel-lazyload-atricle
# find是找到相匹配的第一个标签
div = soup.find(name="div",attrs={"id":"auto-channel-lazyload-article"})
# 这个div是一个标签对象
6、findall方法,是超找符合条件的所有的标签,下面是在步骤5的div标签内查找所有的li标签
li_list = div.find_all(name="li")
7、查找li标签中的不同条件的标签
li_list = div.find_all(name="li")
for li in li_list:
title = li.find(name="h3")
neirong = li.find(name="p")
href = li.find(name="a")
img = li.find(name="img")
if not title:
continue
8、获取标签的属性
# print(title, title.text, sep="标题-->")
# print(neirong, neirong.text, sep="内容-->")
# print(href, href.attrs["href"], sep="超链接-->")
# 获取标签对接的属性
# print(img.attrs["src"])
# ret = requests.get(img_src)
9、如果我们下载一个文件,则需要requests.get这个文件,然后调用这个文件对象的content方法
src = img.get("src")
img_src = src.lstrip("/")
file_name = img_src.split("/")[-1]
img_src = "://".join(["https",img_src])
print(file_name)
ret = requests.get(img_src)
with open(file_name,"wb") as f:
资源评论













