Python实现爬取网页中动态加载的数据
版权申诉

Python实现爬取网页中动态加载的数据实现爬取网页中动态加载的数据
主要介绍了Python实现爬取网页中动态加载的数据,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习
学习吧
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中,无法抓取动态加载的可用数据。例如,获取某网页中,商品价格时就会出现此类现象。如下图所示。本文将实现爬取网页中类似
的动态加载的数据。
1. 那么什么是动态加载的数据那么什么是动态加载的数据?
我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中的url请求得到的。而是通过其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数
据。(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其他url中获取数据)
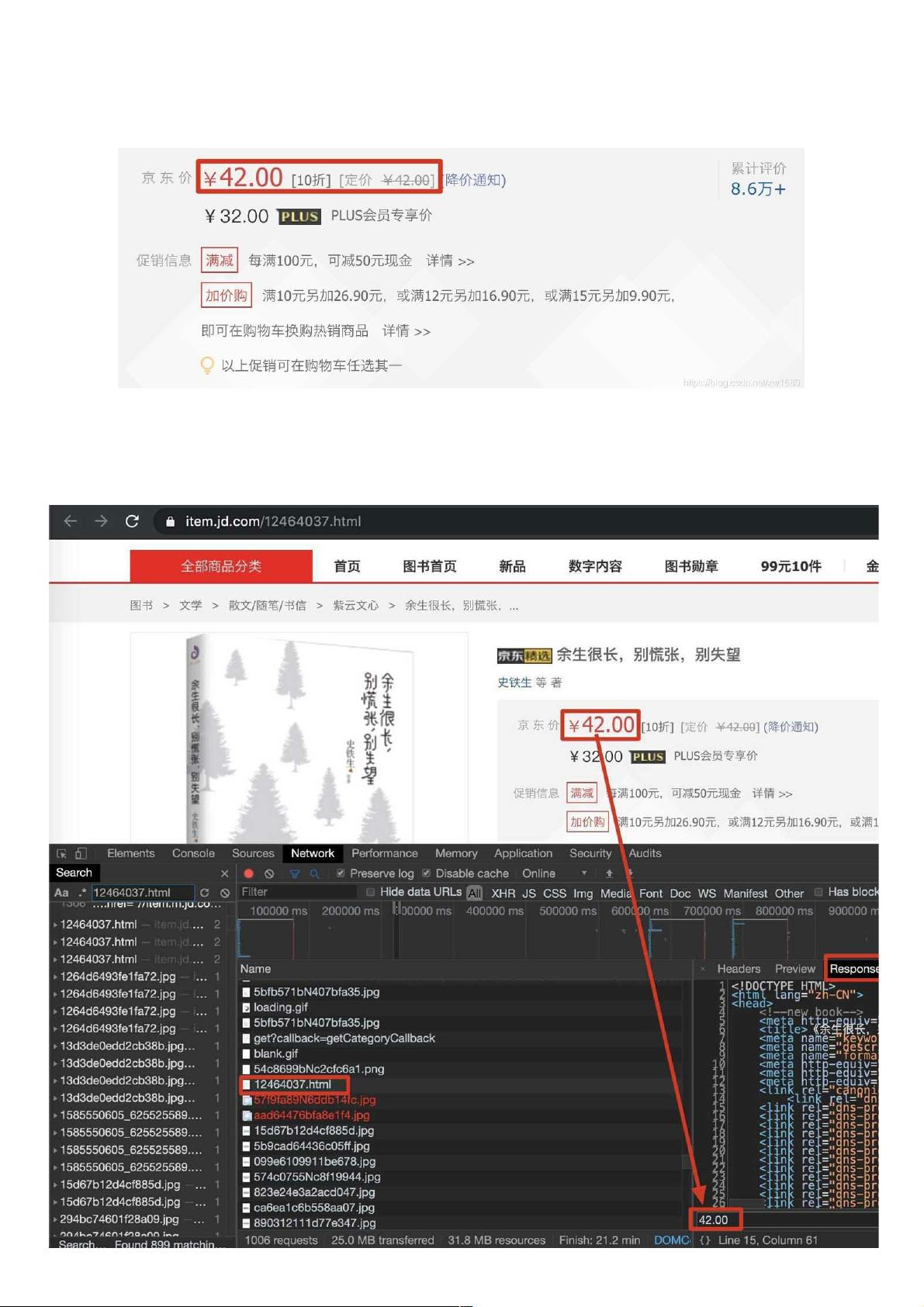
2. 如何检测网页中是否存在动态加载得数据如何检测网页中是否存在动态加载得数据?
在当前页面中打开抓包工具,捕获到地址栏中的url对应的数据包,在该数据包的response选项卡搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的。如
图所示:






评论3
最新资源