Spark随机森林算法原理、源码分析及案例实战
98 浏览量
2021-02-26
09:14:29
上传
评论 2
收藏 908KB PDF 举报

Spark随机森林算法原理、源码分析及案例实战随机森林算法原理、源码分析及案例实战
本文首先对决策树算法的原理进行分析并指出其存在的问题,进而介绍随机森林算法。同单机环境下的随机森林构造不同的
是,分布式环境下的决策树构建如果不进行优化的话,会带来大量的网络 IO 操作,算法效率将非常低,为此本文给出了随机
森林在分布式环境下的具体优化策略,然后对其源码进行分析,最后通过案例介绍随机森林在金融领域内如何进行优质客户的
分类。
引言
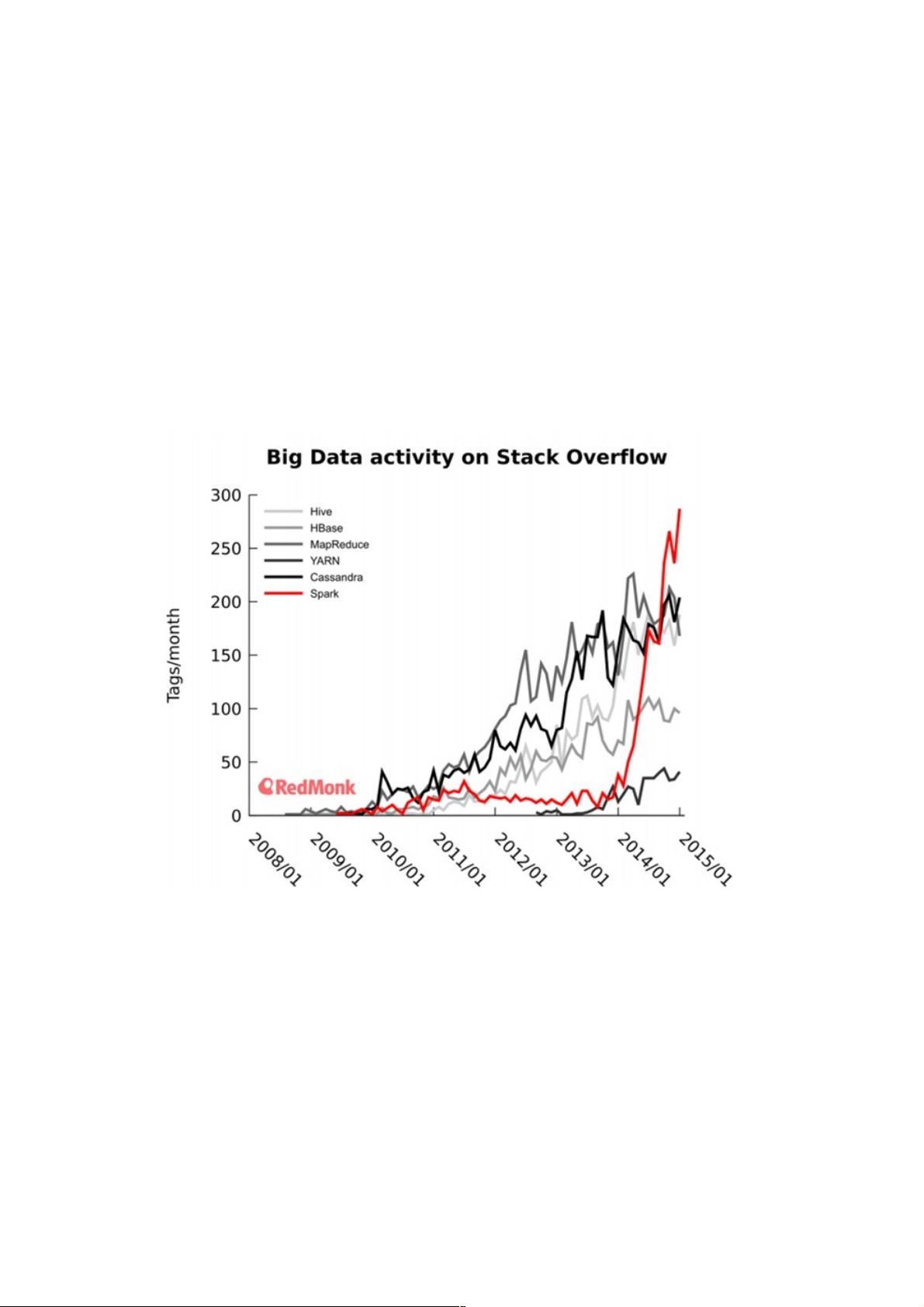
Spark 内存计算框架在大数据处理领域内占有举足轻重的地位,2014 年 Spark 风靡 IT 界,Twitter 数据显示 Spark 已经超越
Hadoop、Yarn 等技术,成为大数据处理领域中最热门的技术,如图 1 所示。2015 年 6 月 17 日,IBM 宣布它的“百万数据工
程师计划”,承诺大力推进 Apache Spark 项目,并称该项目为“以数据为主导的,未来十年最为重要的新的开源项目”,计划投
入超过 3500 名研究和开发人员在全球十余个实验室开展与 Spark 相关的项目,并将为 Spark 开源生态系统无偿提供突破性的
机器学习技术——IBM SystemML。从中不难发现,机器学习技术是 IBM 大力支持 Spark 的一个重要原因,这是因为 Spark
是基于内存的,而机器学习算法内部实现几乎都需要进行迭代式计算,这使得 Spark 特别适用于分布式环境下的机器学习。
本文将对机器学习领域中经典的分类和回归算法——随机森林(Random Forests)进行介绍。首先对随机森林算法的核心原
理进行介绍,接着介绍其在 Spark 上的实现方式并对其源码进行分析,最后给出一个案例说明随机森林算法在实际项目中的
应用。后续相关内容介绍全部以分类角度进行,回归预测与分类在算法上并没有太多的差异,本文旨在理解随机森林在 Spark
上的实现原理。
图 1. Spark 与其它大数据处理工具的活跃程度比较
环境要求
操作系统:Linux,本文采用的 Ubuntu 10.04,大家可以根据自己的喜好使用自己擅长的 Linux 发行版
Java 与 Scala 版本:Scala 2.10.4,Java 1.7
Spark 集群环境(3 台):Hadoop 2.4.1+Spark 1.4.0
源码阅读与案例实战环境:Intellij IDEA 14.1.4
决策树
随机森林算法是机器学习、计算机视觉等领域内应用极为广泛的一个算法,它不仅可以用来做分类,也可用来做回归即预测,
随机森林机由多个决策树构成,相比于单个决策树算法,它分类、预测效果更好,不容易出现过度拟合的情况。
随机森林算法基于决策树,在正式讲解随机森林算法之前,先来介绍决策树的原理。决策树是数据挖掘与机器学习领域中一种
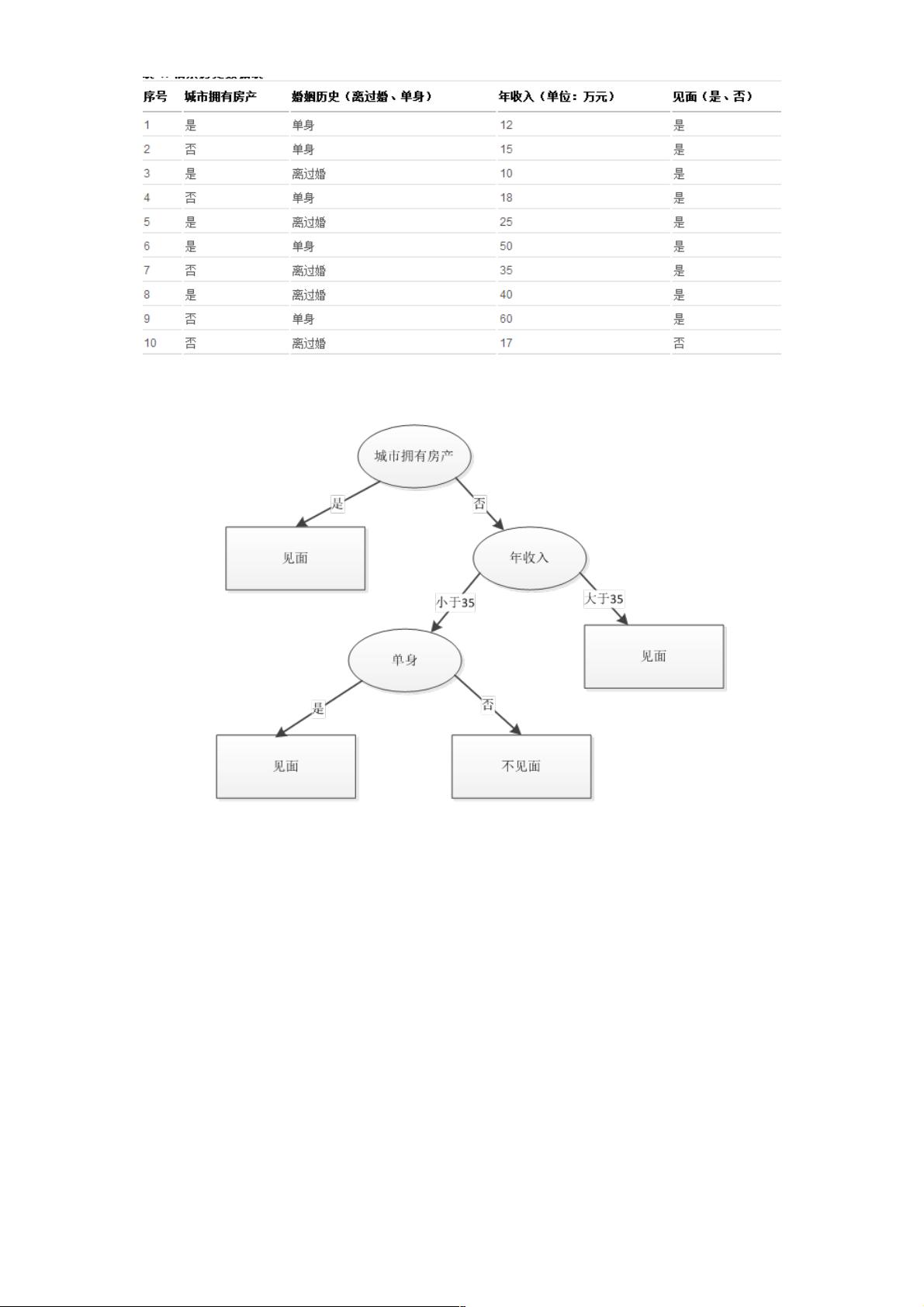
非常重要的分类器,算法通过训练数据来构建一棵用于分类的树,从而对未知数据进行高效分类。举个相亲的例子来说明什么
是决策树、如何构建一个决策树及如何利用决策树进行分类,某相亲网站通过调查相亲历史数据发现,女孩在实际相亲时有如
下表现:
剩余18页未读,继续阅读
资源评论













