关于word2vec,我有话要说1
需积分: 0 17 浏览量
2022-08-03
21:04:40
上传
评论
收藏 531KB PDF 举报


写在前的话:
总结下使word2vec来的些经验,因为在做的时候,很难在上搜到word2vec的经验介
绍,所以归纳出来,希望对读者有。
这介绍word2vec的原,因为原介绍的资上很多:
作者论 word2vec论坛
作者论讲的较简单,推荐个较全的word2vec原分析
最后,由于本知识有限,错误之处,还望指正。
1 word2vec 是word embedding 最好的具吗?
word2vec并是效果最好的word embedding 具。最容看出的就是word2vec没有考虑语序,这
会有训练效果损失。
由于 word2vec 训练速度快 ,,google出品 等,使得word2vec使的多。
训练快是因为 word2vec只有输层和输出层,砍去神经络中,隐藏层的耗时计算(所以word2vec
并算是个深度学习算法)。另外,阅读word2vec的google的源码,会发现有些提速的
trick。如 sigmod函数,采次计算,以后查表,减去的重复计算。如词典hash存储, 层次
softmax等。
是因为word2vec 公布word2vec的代码。在tensorflow,gensim,spark mllib包中都有集成,使
。
2 word2vec 训练结果的差异主要来么因素?
2.1 语影响最
语的场景,如微博的语和新闻语训练的结果差别很。因为微博属于个发帖,较随意。
新闻较官正式,另外新闻式相对复杂。经过训练对:微博这种短,训练的相似词多是同级
别的相关词。如 深圳 相关的是 州 。新闻语,训练得到 深圳 相关的词 多是与 深圳 有关联
的词,如 深圳学。
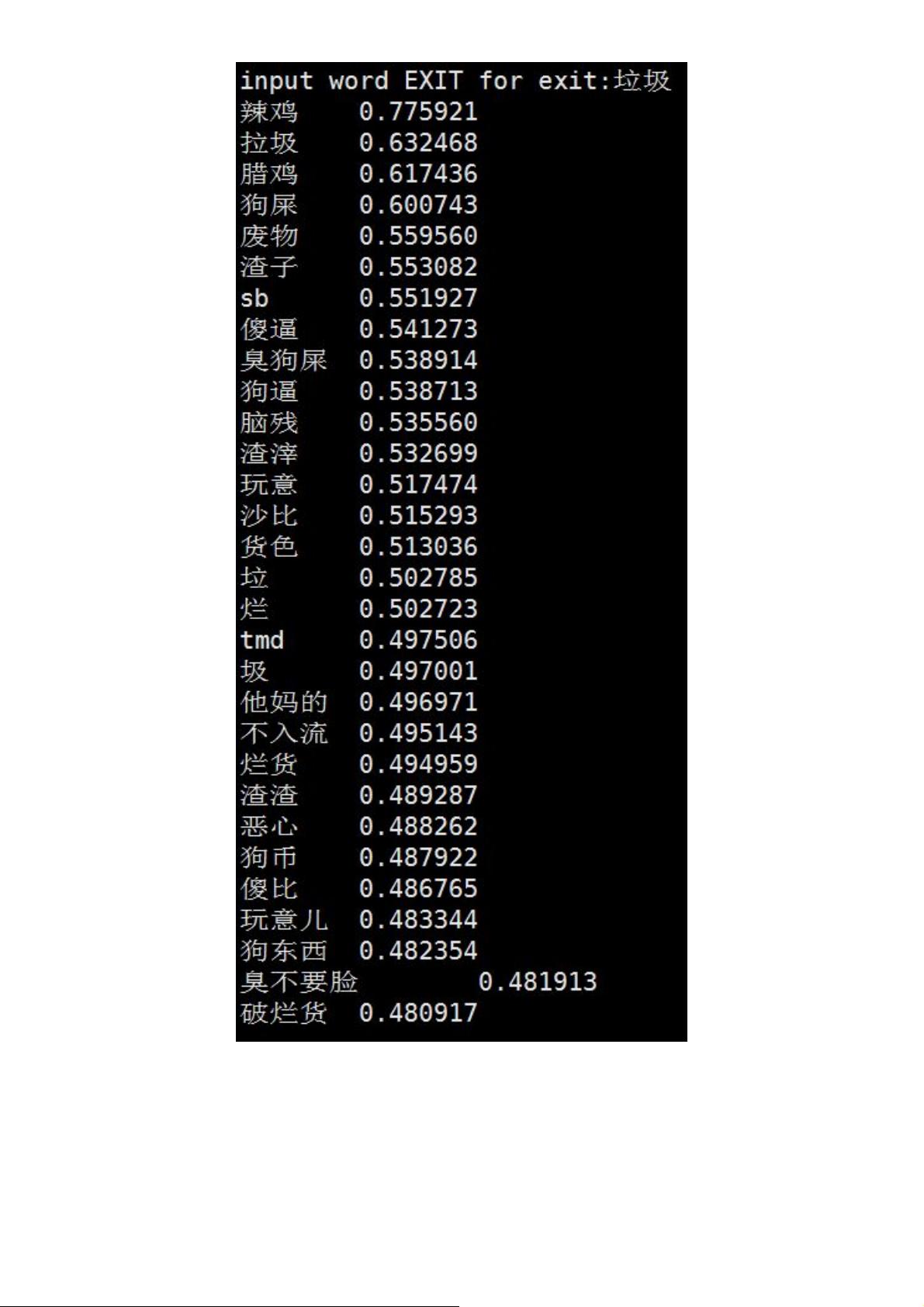
实际发现在微博,违法情的词训练的较好,因为产这种聚到来推。在评论,骂的词训练
的较好,在新闻,则是常的正规的词训练的较好。

剩余10页未读,继续阅读













评论0