题目:招聘网爬取、可视化与机器学习应用1
需积分: 0 48 浏览量
2022-08-08
20:03:13
上传
评论
收藏 6.01MB DOCX 举报


题目:招聘网爬取、可视化与机器学习应用
一、完成人
姓名
学号
分工
占比
康育鑫
SA19225203
写爬虫,爬取网页
1/3
周天逸
SA19225509
数据可视化分析
1/3
苟小飞
SA19225149
机器学习应用
1/3
二、设计背景
作为工程硕士,大部分同学的毕业去向主要是就业,但是有些同学对就业
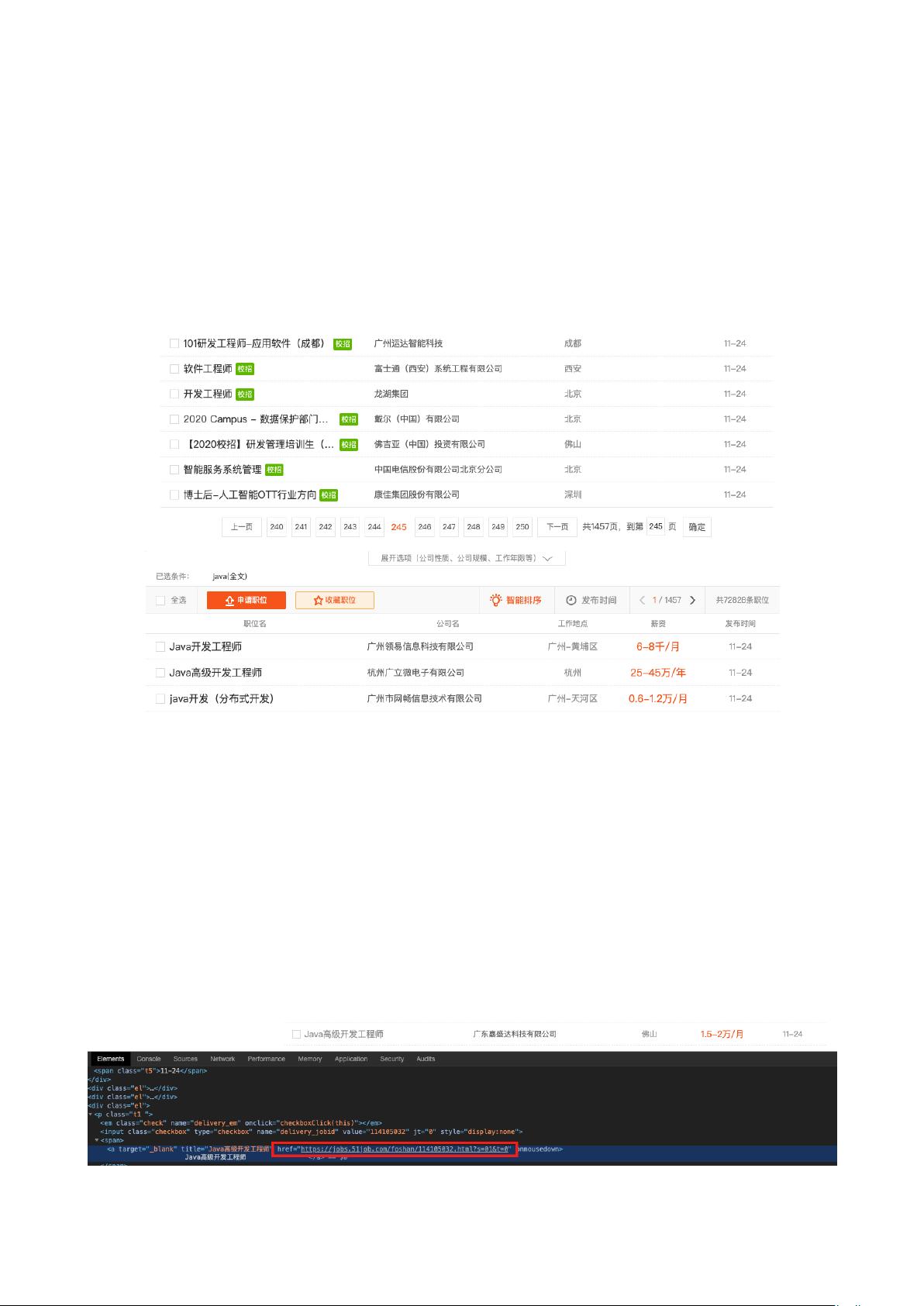
市场的了解还不够充分。因此,本项目爬取了“前程无忧”网站“Java 开发”
岗位的招聘信息,对数据进行可视化展示及分析,并建立了预测期望薪资的机
器学习模型,来帮助同学们加深对就业形势的认识。
三、设计目标
本项目旨在设计出爬取效率较高的爬虫程序、充分而生动的可视化展示、
误差较低的期望薪资预测模型。
四、技术路线
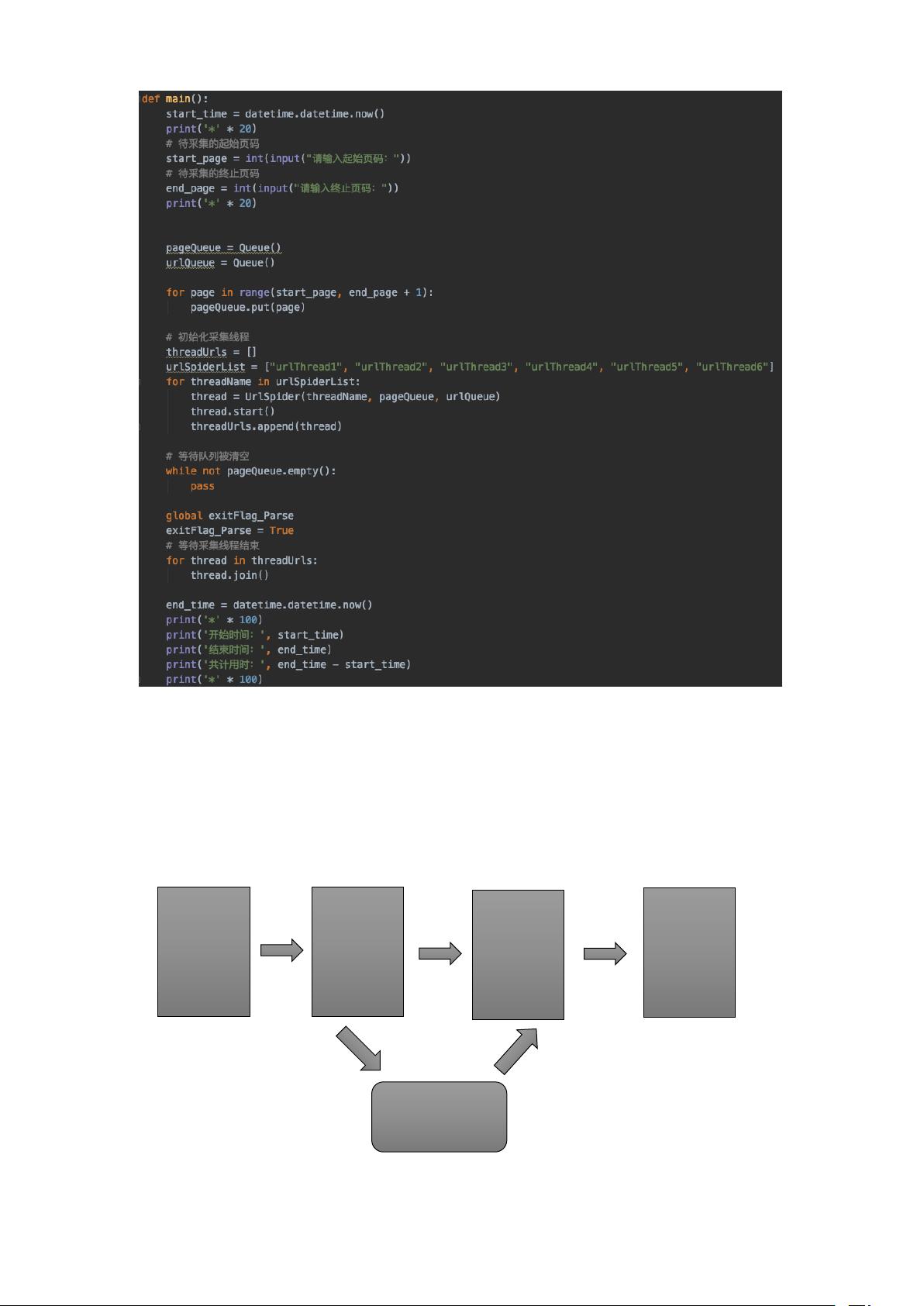
使用 threading 和 queue 进行多线程爬取
使用 lxml 中的 xpath 进行定位;
使用 pyecharts 及 matplotlib.pyplot 对数据进行可视化操作
使用 pandas 对数据进行处理;
使用 sklearn 中操作数据集的函数及机器学习算法函数;
使用 matplotlib 画出描述数据的图像。


剩余35页未读,继续阅读













评论0